
الان دیگه چند سالی هست که برای هر مهندس نرم افزار یا برنامه نویس Mid-Level به بالایی مهارت طراحی سیستم های نرم افزاری یا همان System Design بسیار مهم شده است و تقریبا در همه ی مصاحبه های شغلی سوالی در این باره از شما پرسیده خواهد شد. این مهارت هم مثل مهارت های دیگر نیازمند دانش فنی است، ولی مواردی هستند که مثل آجرهای ساختمان می مانند و شما باید آنها را بلد باشید تا بتوانید با استفاده از دانش فنی تان یک خانه ی خوب بسازید. در این مقاله قرار است با 10 تا از مهمترین این موارد آشنا بشوید.
1- Scalability
مقیاس پذیری به توانایی یک سیستم برای مدیریت حجم فزاینده کار یا پتانسیل آن برای تطبیق با رشد در آینده اشاره دارد. به عبارت دیگر، یک سیستم مقیاس پذیر با افزایش بار، عملکرد را حفظ یا حتی بهبود می بخشد.
فرض کنید سایتی دارید که 100 بازدید در روز داشته است. حالا این سایت شما به 100000 بازدید در روز رسیده است. آیا می توانید با همان منابع سخت افزاری و نرم افزاری سابق پاسخگوی این 1000 برابر شدن بازدید کننده هایتان باشید؟ خیر.
Scalability یعنی سیستم را به گونه ای طراحی کنید که در زمان افزایش بار (تعداد بازدید، تعداد درخواست و ...) روی سیستم، بتواند بدون اینکه به عملکرد سیستم آسیبی برساند، پاسخگوی بار اضافه باشد. برای موفق شدن در آزمونهای Scalability (مقیاس پذیری) لازم است به مفاهیمی از جمله Load Balancing، Caching، Sharding و پردازش ناهمزمان (Asynchronous Processing) حسابی فکر کرده باشید.
دو نوع اصلی مقیاس پذیری وجود دارد:
مقیاسپذیری افقی (Horizontal Scalability یا Scale-out)، یعنی اضافه کردن ماشین بیشتر به مجموعه منابع سیستم. برای مثال یک سرور جدید به مجموعه سرورهایی که برای پاسخگویی به درخواستهای کاربران سیستم در نظر گرفته اید.
این نوع مقیاسبندی به سیستم اجازه میدهد، با به اشتراک گذاشتن بار در چندین سرور، به کاربران همزمان بیشتری خدمت کند. مقیاس پذیری افقی اغلب با مفهوم Elasticity مرتبط است، جایی که می توان منابع جدید را به طور خودکار در پاسخ به تغییرات تقاضا اضافه یا از رده خارج کرد.
مقیاسپذیری عمودی (Vertical Scalability یا Scale-up)، یعنی قدرت بیشتری (CPU، RAM، ذخیره سازی) به یک ماشین موجود اضافه کنیم. به عنوان مثال می توان به ارتقای سروری با CPU سریعتر، رم بیشتر یا فضای دیسک اضافی اشاره کرد. این نوع مقیاس گذاری ظرفیت یک سرور را افزایش می دهد اما به تعداد سرورها اضافه نمی کند. این رویکرد میتواند بلاخره یک سقف و محدودیتی دارد، زیرا محدودیتهای فیزیکی در مورد قدرت یک ماشین واحد وجود دارد.
در طراحی سیستمهای مقیاسپذیر همیشه بزرگترین چالش شما به عنوان طراح برقراری تعادلی خوب بین مقیاسپذیر بودن سیستم، سطح پیچیدگی سیستم و هزینه (دقیقا به معنی پول) راه اندازی و نگهداری آن است.
2- Availability
در زمینه طراحی سیستم (System Design)، در دسترس بودن به توانایی یک سیستم برای عملیاتی شدن مداوم و در دسترس بودن در صورت نیاز اشاره دارد. به عبارت دیگر، مدت زمانی است که یک سیستم در حال کار است تا عملکرد مورد نیاز خود را در یک دوره خاص انجام دهد.
معمولا Availability را اینگونه محاسبه می کنند که طی مدت زمانی (مثل یک سال) چقدر آن سیستم Down Time یا زمان خارج از دسترس داشته است. اگر جایی خواندید که بخش X در سیستم Y میزان دردسترس بودنش در سال Five Nine است، یعنی 99/999% مواقع در سال این سیستم درحال کار است. که میشود معادل 5 دقیقه در دسترس نبودن طی سال.
Availability برای حفظ یک تجربه کاربری مثبت بسیار مهم است، زیرا کاربران انتظار دارند سیستم هر زمان که به آن نیاز داشته باشند در دسترس باشد. دستیابی به دسترسی بالا اغلب مستلزم سیستمهای اضافی و مکانیزمهای خرابی (failover mechanisms) است تا اطمینان حاصل شود که اگر بخشی از سیستم از کار بیفتد، قسمت دیگری میتواند کنترل را به دست بگیرد.
فکر کنید سیستمی را طراحی کرده اید که تمام درخواست های کاربران به 5 بخش مختلف از برنامه تان را به یک جز ارسال میکند. حالا اگر این جز به هر دلیلی خراب بشود و نتواند پاسخگو باشد، کل سیستم شما از دسترس خارج میشود.
پس یکی از معیارهای مهم در طراحی یک سیستم قابل اعتماد همین است که SPOF در سیستم ایجاد نکنیم. و حواسمان باشد سیستم را به گونه ای طراحی کنیم که اگر بعضی از بخش ها از کار افتادند، سیستم توانایی تحمل را داشته باشد و از کار نیافتد.
3- Consistency
در زمینه طراحی سیستم، بهویژه در سیستمهای توزیعشده، Consistency یا «سازگاری» به این اطلاق میشود که هر کلاینت یا کاربر مشاهده ای یکسان از دادهها در یک زمان یکسان داشته باشد، علیرغم اینکه بهروزرسانیها به طور همزمان از مکانهای مختلف اتفاق میافتد.
زمانی که صحبت از سیستم های توزیع شده (Distributed Systems) است، که در این سیستمها دادهها در چندین سرور توزیع می شوند، سازگاری می تواند کمی پیچیده باشد. چرا که وقتی یک به روز رسانی برای یک داده انجام می شود، آن به روز رسانی باید به همه سرورها منتشر شود تا همه کاربران دید یکسانی از داده ها داشته باشند. اگر همه کاربران همیشه دادههای یکسانی را در همه گرهها ببینند، گفته میشود که همه گرهها سازگار هستند.
4- Partitioning
پارتیشن بندی فرآیند تقسیم داده ها به تکه های کوچکتر و قابل مدیریت تر است. برای پارتیشن بندی موثر داده ها، باید عواملی مانند الگوهای دسترسی به داده ها، توزیع داده ها و تکرار داده ها را در نظر بگیرید. هدف اصلی پارتیشن بندی تسهیل مدیریت مقادیر بزرگتر داده با تقسیم آن به قطعات کوچکتر و قابل مدیریت تر است. که با تقسیم داده ها (Data Sharding) روی دیتابیس ها و سرورهای مختلف انجام میشود.
روشهای مختلفی برای پارتیشن بندی داده ها وجود دارد:
پارتیشن بندی افقی (Horizontal Partitioning) که داده های یک دیتابیس را به ردیف ها تقسیم می کند و ردیفهای 1 تا 1000 را روی یک دیتابیس و ردیف های 1001 تا 2000 را روی دیتابیس (یا سرور) بعدی ذخیره می کند.
پارتیشن بندی عمودی (Vertical Partitioning) هم داده های یک دیتابیس را بر اساس ستون ها تقسیم بندی می کند. یعنی بعضی از ستون ها در یک جدول یا دیتابیس یا سرور ذخیره میشود و ستون های دیگری در جایی دیگر. این روش در زمانی مناسب است که میزان مراجعه شما به گروهی از ستونها یا ترکیبی از آنها یکسان نباشد.
پارتیشن بندی عملکردی (Functional Partitioning)، روشی است که طی آن شما دادهها را براساس عملکردشان در سیستم روی دیتابیسها یا سرورهای مختلف ذخیره میکنید. برای مثال در سایت سکانآکادمی می توان دیتاهای مربوط به پروفایل کاربران، دورهها، بلاگها و ... روی دیتابیسهای مختلفی روی سرورهای مختلف ذخیره شود.
پارتیشن بندی جغرافیایی (Geographic Partitioning) هم شامل پارتیشن بندی داده ها بر اساس موقعیت جغرافیایی کاربران است. این نوع تقسیم بندی داده ها به ویژه برای برنامه هایی در ابعاد کاربران جهانی مفید است که در آن تأخیر باید برای کاربران در مناطق خاص به حداقل برسد.
پارتیشن بندی دادهها هر چند مزایای زیادی دارد، ولی پیچیدگی زیادی هم برای سیستم ایجاد میکند. زیرا اغلب لازم است تراکنش ها را در چندین پارتیشن توزیع کرد و داده ها را همگام نگه داشت.
5- Caching
Caching به فرآیند ذخیره یک کپی از داده ها در مکانی اشاره دارد که سریعتر از منبع اصلی قابل دسترس باشد. دادههایی که در Cache ذخیره میشوند ممکن است مقادیری باشند که قبلاً محاسبه شدهاند یا تکراری از مقادیر اصلیای باشند که در جای دیگر ذخیره شدهاند.
Caching میتواند در لایههای مختلفی انجام شود که در اینجا به چند نمونه اشاره میکنم:
Browser Cache
مرورگرها فایلهای وب، مانند تصاویر و فایلهای CSS را برای کاهش زمان بارگذاری صفحات وب که قبلاً بازدید کردهاید، ذخیره میکنند.
CDN (Content Delivery Network) Cache
CDN ها سرورهای توزیع شده ای هستند که محتوای وب را بر اساس موقعیت جغرافیایی، مبدا صفحه وب و سرور CDN به کاربران ارائه می دهند. آنها محتوای ثابت مانند تصاویر و کدهای جاوا اسکریپت را برای کاهش تأخیر در تحویل به کاربر بر اساس موقعیت جغرافیایی اش ذخیره می کنند.
Database Cache
داده هایی که اغلب از یک دیتابیس خوانده میشوند را می توان در کش ذخیره کرد تا از کوئریهای وقت گیر جلوگیری شود.
Application Cache
در برنامه های نرم افزاری، داده های پرکاربرد یا بدون تغییر اغلب برای جلوگیری از محاسبات مکرر یا کوئریهای بیشتر به دیتابیس، در Cache ذخیره می شوند.
اگر از استراتژی درستی برای Caching استفاده کنید، میتوانید عملکرد سیستم را به طور چشم گیری ارتقا دهید. برای آشنایی بیشتر با Cache و استراتژیهای آن مقالهی "استراتژی های Cache – چطوری بهترین استراتژی کش را انتخاب کنم؟" را مطالعه کنید.
6- Load Balancing
Load Balancing روشی برای توزیع ترافیک شبکه یا برنامه در چندین سرور است تا اطمینان حاصل شود که هیچ سروری تقاضای زیادی را تحمل نمی کند. Load Balancing نه تنها قابلیت اطمینان کلی سیستم را با system redundancy افزایش می دهد (یعنی اگر یک سرور از کار بیفتد، بار به سرور دیگری منتقل می شود)، بلکه عملکرد سیستم را با به اشتراک گذاشتن بار کار افزایش می دهد.
چند استراتژی متداول برای Load Balancing وجود دارد که در ادامه بعضی از آنها را معرفی میکنم:
Round Robin: درخواست ها به صورت متوالی در بین گروهی از سرورها توزیع می شوند.
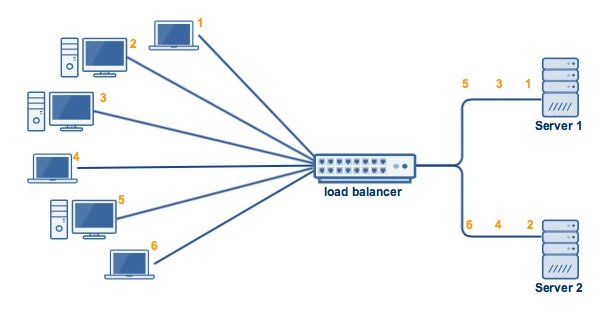
حداقل Connection: درخواست بعدی به سروری ارسال می شود که کمترین Connection فعلی را به مشتریان دارد. این روش زمانی می تواند مفید باشد که تعداد زیادی از Connection های دائمی در ترافیک به طور نابرابر بین سرورها توزیع شده باشد. برای مثال در تصویر زیر Connection های 2و4و6 هنوز به سرور متصل شده هستند، درحالی که Connection های 1 و 3 کارشان تمام شده است.
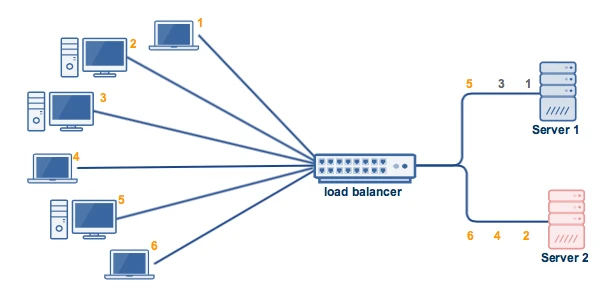
IP Hash: آدرس IP کلاینت برای تعیین اینکه کدام سرور، درخواست را دریافت می کند استفاده می شود.
URL Hash: آدرس URL درخواست یا بخشی از آن برای تعیین سروری که درخواست را دریافت می کند استفاده می شود.
Load Balancer ها به دو گونهی سختافزاری و نرمافزاری تقسیم میشوند. که وظایفی مشابه را دارند. دقت کنید Load Balancing هم ضمن اینکه مزایای زیادی را برای سیستم ایجاد میکند، ولی پیچیدگی هم اضافه میکند. برای مثال در زمانی که Session استفاده میکنید، مدیریت Session ها میتواند چالش برانگیز باشد که برای این منظور هم استراتژیهای مختلفی از جمله کپی کردن همهی Sessionها روی همهی سرورها یا ارسال اطلاعات مربوط به کانکشن هر Session به یک سرور خاص وجود دارد.
7- Microservices
Microservices یک سبک معماری و رویکردی برای طراحی نرمافزارهای کاربردی به عنوان مجموعهای از سرویسهای کوچک، مستقل و بدون وابستگی به دیگر اجزا است که هر کدام یک عملکرد تجاری خاص را انجام میدهند. در معماری میکروسرویس، کل برنامه به سرویسهای جداگانه تجزیه میشود و هر سرویس میتواند به طور مستقل توسعه، استقرار و مقیاسبندی شود.
ویژگی های کلیدی میکروسرویس ها عبارتند از:
Decentralization
هر میکروسرویس یک واحد مستقل با کد، دیتابیس و منطق تجاری (business logic) خاص خود است. این ویژگی به توسعهدهندههای تیم ها اجازه می دهد تا به طور مستقل روی سرویس های مختلف کار کنند.
Loose Coupling
میکروسرویس ها از طریق APIهای کاملاً تعریف شده با یکدیگر ارتباط برقرار می کنند. Loose Coupling تضمین می کند که تا زمانی که قرارداد API حفظ می شود، تغییرات در یک سرویس بر سایر خدمات تأثیر نمی گذارد.
Independently Deployable
از آنجایی که هر سرویس جداگانه است، می توان آن را بدون تأثیر بر کل سیستم مستقر و به روز کرد. این امکان استقرار مکرر و سریعتر را فراهم می کند.
Scalability
میکروسرویس ها را می توان به صورت جداگانه بر اساس نیازهای خاص هر سرویس مقیاس بندی کرد. همانطور که بالاتر هم دیدیم Scalability اجازه می دهد تا منابع به طور موثرتری در صورت لزوم به هرکدام از سرویسها تخصیص داده شوند.
Resilience and Fault Isolation
اگر یک میکروسرویس از کار بیفتد، کل برنامه را از بین نمیبرد، زیرا سایر سرویسها میتوانند به طور مستقل به کار خود ادامه دهند.
Technology Diversity
سرویسهای مختلف را میتوان با استفاده از زبانها و فناوریهای برنامهنویسی مختلف توسعه داد، به شرطی که بتوانند از طریق APIها ارتباط برقرار کنند.
Autonomous Teams (تیم های خودمختار و مستقل)
میکروسرویسها اغلب منجر به ایجاد تیمهایی میشوند که مسئول سرویس خاصی هستند. این امر باعث مالکیت بیشتر، مسئولیت پذیری و تصمیم گیری سریع تر میشود.
حالا که از مزایای میکروسرویس ها گفتم، خوب است اشاره ای هم به معایب آنها بیاندازیم تا یادمان نرود که میکروسرویسها برای هر برنامهای با هر ابعادی، مناسب نیستند.
1- پیچیدگی مدیریت ارتباط بین سرویس ها از طریق شبکه افزایش می یابد.
2- حفظ ثبات داده ها در سرویس های مختلف می تواند چالش برانگیز باشد.
3- مدیریت و نظارت بر تعدادی سرویس ممکن است به تلاش عملیاتی (Operational) بیشتری نیاز داشته باشد.
میکروسرویس ها برای کاربردهای بزرگ و پیچیده با حوزه های عملکردی متفاوت و نیازمندی های در حال تکامل بسیار مناسب هستند. آنها مزایایی مانند مقیاس پذیری، چابکی و سهولت توسعه را برای سیستم می آورند، اما سیستم را با چالش هایی هم روبرو میکنند که باید به دقت مدیریت شوند تا از مزایای کامل این معماری بهره مند شوند.
برای طراحی معماری میکروسرویس ها، باید عواملی مانند مرزهای سرویس، ارتباطات سرویس و کشف سرویس را در نظر بگیرید.
8- Service-Oriented Architecture - SOA
معماری سرویس گرا (SOA) یک رویکرد طراحی نرم افزار است که در آن برنامه های کاربردی بر اساس سرویس هایی که از طریق شبکه با یکدیگر ارتباط برقرار می کنند ساخته می شوند. این سرویسها واحدهای عملکردی مستقلی هستند که میتوان بدون دانستن جزئیات پلتفرم، فناوری یا حتی زبان برنامهنویسی به آنها دسترسی پیدا کرد و از آنها استفاده کرد. آنها با استفاده از پروتکل های استاندارد با یکدیگر ارتباط برقرار می کنند و می توان آنها را ترکیب کرد و مجدداً برای ایجاد برنامه های تجاری استفاده کرد.
ویژگی های کلیدی SOA عبارتند از:
- Reusability: سرویس ها برای استفاده مجدد در چندین برنامه یا بخش های یک سیستم طراحی شده اند.
- Loose Coupling
- Abstraction: هر سرویس پیچیدگی خود را پشت یک رابط پنهان می کند. مصرف کنندگان یک سرویس نیازی به دانستن نحوه اجرای سرویس ندارند.
- Composability (ترکیب پذیری): خدمات را می توان برای ارائه عملکرد پیچیده تر ترکیب کرد.
- Statelessness: در حالت ایده آل، خدمات باید بدون State باشند تا قابلیت استفاده مجدد را به حداکثر برسانند و وابستگی ها را کاهش دهند.
- Interoperability (قابلیت همکاری): سرویس ها می توانند با یکدیگر تعامل داشته باشند و بدون توجه به نحوه اجرای هر سرویس، داده ها را مبادله کنند.
- Standards-based (مبتنی بر استانداردها): سرویسها با استفاده از پروتکلهای استاندارد ارتباط برقرار میکنند، و تضمین میکنند که سوریسها میتوانند توسط هر کلاینتی که استاندارد را رعایت کند، استفاده شوند.
SOA و میکروسرویسها در بعضی موارد به اشتباه به جای هم استفاده میشوند. در حالی که هر دو معماری از طراحی مبتنی بر سرویس بهره میبرند، تفاوت های کلیدی ای هم وجود دارد. در SOA، سرویس ها اغلب یک دیتابیس به اشتراک می گذارند و می توانند باهم Couple شوند، در حالی که در میکروسرویسها، هر سرویس دیتابیس خاص خود را دارد و به گونه ای طراحی شده است که مستقل تر باشد.
9- Message Queues
Message Queues شکلی از ارتباط سرویس به سرویس ناهمزمان (Asynchronous Service-to-Service) است که در معماری های بدون سرور و میکروسرویس استفاده می شود. Message Queue مؤلفه ای است که برای انتقال داده ها بین برنامه ها یا سرویس ها استفاده می شود تا اطمینان حاصل شود که این داده ها به روش Asynchronous پردازش می شوند.
اجزای اصلی درگیر در فرآیند Message Queue عبارتند از:
- Producer: برنامه ای که پیام را ارسال می کند.
- Queue: بافری که پیام را ذخیره می کند.
- Consumer: برنامه ای که پیام را دریافت و پردازش می کند.
سرویسهای Message Queue متداول عبارتند از Amazon Simple Queue Service (SQS)، Apache Kafka، RabbitMQ و Google Cloud Pub/Sub.
10- Security
در زمینه System Design، امنیت به اقدامات، شیوهها و فناوریهایی اطلاق میشود که برای محافظت از سیستم و دادههای آن در برابر تهدیدها یا دسترسیهای غیرمجاز اعمال میشوند. این موارد شامل اطمینان از محرمانه بودن (confidentiality)، یکپارچگی (integrity) و در دسترس بودن (availability) داده ها (معروف به سه گانه CIA در امنیت اطلاعات) است.
هنگام طراحی یک سیستم، مهم است که امنیت را از ابتدا در نظر بگیرید، نه اینکه آن را به عنوان یک اقدامی که در آینده به آن خواهید پرداخت در نظر بگیرید. در ادامه چند نکته در مورد امنیت در طراحی سیستم را معرفی میکنم :
Authentication (احراز هویت)
سیستم باید دارای مکانیزمی برای تایید هویت کاربران، سیستم ها یا برنامه هایی باشد که سعی در دسترسی به آن دارند. این مهم را می توان با استفاده از نام کاربری و رمز عبور، token ها یا روش های پیشرفته تر مانند بیومتریک انجام داد.
Authorization (مجوز)
پس از احراز هویت کاربران، سیستم ها یا برنامه ها، آنها فقط باید بتوانند به منابع یا عملیاتی دسترسی داشته باشند که مجاز به استفاده از آنها هستند.
برای درک بهتر این دو مفهوم به مقالهی "احراز هویت (Authentication) در میکروسرویس: تکنیک ها و روش ها" مراجعه کنید.
Data Protection
داده های حساس باید هم زمانی که ذخیره می شوند و هم در هنگام انتقال رمزگذاری شوند. دادههای حساس شامل رمزهای عبور، اطلاعات کارت اعتباری، اطلاعات شناسایی شخصی و غیره است.
Input Validation
سیستم به طور پیش فرض نباید به ورودی ها اعتماد کند. ورودی ها باید برای جلوگیری از حملاتی مانند SQL injection، cross-site scripting (XSS) یا XML External Entity (XXE) اعتبارسنجی شوند.
Least Privilege Principle
این اصل نشان می دهد که کاربران باید کمترین دسترسی لازم را برای تکمیل وظایف خود داشته باشند.
Security by Design
امنیت باید از ابتدا در طراحی سیستم ادغام شود، نه به عنوان یک فکر بعدی. این به معنای تفکر در مورد تهدیدات و آسیب پذیری های بالقوه در هر مرحله از فرآیند طراحی است.
Intrusion Detection and Prevention (تشخیص و پیشگیری از نفوذ)
سیستم باید بتواند فعالیت های مخرب را شناسایی کرده و به آن پاسخ دهد. این می تواند شامل ورود به سیستم، تشخیص ناهنجاری، یا سیستم های تشخیص نفوذ (IDS) باشد.
طرح واکنش به حادثه
حتی با وجود تمام اقدامات احتیاطی، باز هم ممکن است هکری موفق بشود به سیستم شما ورود کند. باید یک طرح واکنش به حادثه وجود داشته باشد تا اقداماتی را که باید در صورت وقوع یک حادثه امنیتی انجام شود، تشریح کند.
Regular Updates and Patches
سیستمها باید بهطور منظم بهروزرسانی و Patch شوند تا در برابر آسیبپذیریهای شناخته شده محافظت شوند.
Secure Defaults
سیستم ها باید به طور پیش فرض ایمن باشند. به عنوان مثال، این بدان معناست که پورت های غیر ضروری بسته می شوند، سرویسهای غیر ضروری خاموش می شوند و رمزهای عبور پیش فرض تغییر می کنند.
موارد فوق برخی از ملاحظاتی است که باید در مورد امنیت در طراحی سیستم در نظر داشت. هر سیستم نیازها و الزامات امنیتی خاص خود را خواهد داشت، بنابراین مهم است که در حین طراحی سیستم، یک تمرین مدلسازی تهدید و ارزیابی ریسک کامل انجام شود. امنیت یک رویداد یکباره نیست، بلکه یک فرآیند مداوم است.
در پایان، تسلط بر این 10 مفهوم طراحی سیستم برای هر برنامه نویسی که می خواهد برنامه های کاربردی مقیاس پذیر، در دسترس و ایمن بسازد ضروری است. به خاطر داشته باشید که این تازه آغاز کار است. چیزهای بیشتری برای یادگیری در مورد طراحی سیستم وجود دارد و این یک فرآیند مداوم است. با بهبود مستمر مهارتهای طراحی سیستم خود، میتوانید برنامههای کارآمدتر و مؤثرتری بسازید.