
افرادی که تازه یادگیری فناوریهایی مثل یادگیری ماشین را آغاز میکنند، هنگامی که پروژههایی مثل AlphaGo وAlphaZero که از شاهکارهای دیپمایند (DeepMind) هستند را بررسی میکنند، به سرعت مجذوب دنیای یادگیری ماشین (Machine Learning) و بهویژه یادگیری تقویتی (Reinforcement learning) میشوند. بهطوریکه تصمیم میگیرند، پیچیدگیهای یادگیری عمیق (Deep Learning) را درک کنند، دست به کار شوند و پروژههای یادگیری عمیق خودشان را بنویسند.
ساخت یک ربات تجاری سودآور کار سادهای نیست و به دانش و تلاش زیادی نیاز دارد، اما اگر محصولی ساخته شود که بتواند تخمینهایی نزدیک به واقعیت را ارائه کند به یک محصول ارزشمند تبدیل میشود. به طور کلی، یک مدل کامل وضعیت بازار را بر مبنای پارامترهای مختلفی که ممکن است در مورد برخی از آنها اطلاعات درستی نداشته باشیم، ارزیابی میکند تا بتواند تخمینی قابل قبول ارائه کند.
به طور مثال، اگر مقالههای منتشر شده در ارتباط با پروژهای مثل AlphaZero را مطالعه کنید، متوجه میشوید که این الگوریتم توانست استراتژیهایی در بازی Go ایجاد کند که توسط بازیکنان سطح بالای این بازی کشف نشده بود. اگر بتوانیم از یک چنین استراتژیهایی در حوزههای جدیتری مثل بازار سهام و ارزهای دیجیتال استفاده کنیم و یک عامل یادگیری تقویتی در یک محیط معاملاتی پیچیده ایجاد کنیم، قادر خواهیم بود، مدلی ایجاد کنیم که قابلیت استفاده در بازارهای مختلف را داشته باشد.
بیشتر مقالاتی که پیرامون این موضوع منتشر شدهاند، حول محور یک بازار مشخص هستند. به طور مثال، ربات معاملاتی بیت کوین. اگر بتوانیم عاملهای دادهای بیشتری به مدلی که قصد ساخت آن را داریم، اضافه کنیم، این توانایی را به دست میآوریم تا الگوها و مدلهای کاربردیتری ایجاد کنیم که قادر هستند در بازارهای مختلفی که در یک فضای مشابه وجود دارند به پیشبینی بپردازند. البته، این مسئله کمی پیچیدگی طراحی را بیشتر میکند و احتمال تعمیم آن را کاهش میدهد، اما در مقابل عملکرد بهتری خواهد داشت.
یادگیری تقویتی چیست؟
یادگیری تقویتی (Reinforcement Learning) یکی از شاخههای اصلی یادگیری ماشین (Machine Learning) است. یادگیری تقویتی علم تصمیمگیری است. بهطوری یک الگوریتم هوشمند بر مبنای مشاهدات و نکاتی که میآموزد با هدف دستیابی به بالاترین پاداش، رفتار بهینهای از خود نشان دهد. به بیان دقیقتر، در یادگیری تقویتی، الگوریتم هوشمند در یک موقعیت خاص، کار مناسبی انجام میدهد تا بیشترین پاداش را دریافت کند. یادگیری تقویتی، بیشتر توسط توسط نرمافزارها و ماشینهایی که قرار است یک کار خاص و مشخص را انجام دهند، مورد استفاده قرار میگیرند.
نکته مهمی که باید به آن دقت کنید این است که یادگیری تقویتی با یادگیری نظارت شده (supervised learning) تفاوتهایی دارد، به گونهای که در یادگیری نظارت شده دادههای آموزشی دارای کلید پاسخ هستند. بنابراین، مدل پاسخی که میدهد را با کلیدهای پاسخ مقایسه میکند تا متوجه اشتباهات خود شود و در آینده همان اشتباهات را تکرار نکند، در شرایطی که در یادگیری تقویتی، پاسخی وجود ندارد و عامل تقویتی تصمیم میگیرد که چه کاری انجام دهد یا وظیفه محوله را به چه صورتی انجام دهد. در این حالت، در غیاب یک مجموعه داده آموزشی، مدل یادگیری تقویتی باید از تجربیات خود درس بگیرد. برای کسب اطلاعات بیشتر در ارتباط با یادگیری تقویتی، پیشنهاد میکنیم، حتما مقالات "یادگیری تقویتی چیست" و همین طور "یادگیری ماشین چیست" را در سکان آکادمی بررسی کنید.
ساخت یک ربات معامله گر ساده ارزهای دیجیتال با پایتون
در دنیای سهام، بورس و ارزهای دیجیتال، انجام معامله، فرایند پیچیدهای است که به تجربه، توانایی و آموزش زیادی نیاز دارد. با توجه پیچیده شدن معاملات تجاری به ویژه در حوزه ارزهای دیجیتال، شرکتهای بزرگ و کوچک تصمیم گرفتهاند از برنامههای کاربردی و الگوریتمهای هوشمند برای پیشبینی نوسانات بازار ارزهای دیجیتال استفاده کنند. با اینحال، طراحی یک سیستم معاملاتی درست که بتواند پیشبینیهایی نزدیک به واقعیت ارائه کند و توانایی انجام محاسبات با کمترین دخالت عامل انسانی را داشته باشد، کار سادهای نیست. بخش زیادی از مشکل توسعهدهندگان الگوریتمهای هوشمند، طراحی و پیادهسازی مدلهایی است که توانایی پیشبینی درست نوسانات قیمت بازار ارزهای دیجیتال را داشته باشد. رباتهای معاملهگر (Autotrader Bots) میتوانند با یادگیری رفتار بازار و تحلیل دادهها با سرعت و دقت بالاتری نسبت به انسانها به پیشبینی بپردازند. از اینرو، شرکتها به فکر افتادهاند تا از علم داده (Data Science)، هوش مصنوعی (Artificial Intelligence) و علم تحلیل تکنیکال یا همان فنی (Technical Analysis) برای این منظور استفاده کنند تا بیشترین سود از معامله در این بازار را به دست آورند.
در این مطلب قصد داریم، نحوه ساخت یک ربات معاملهگر ساده ارزهای دیجیتال با استفاده از پایتون بر مبنای یادگیری تقویتی را بررسی کنیم. اما قبل از آن اگر علاقه مند هستید که در مورد بازار های مالی اطلاعات خود را تکمیل کنید، پیشنهاد میکنیم ابتدا مقالهی بازار های مالی را مرور کنید.
مرحله اول برای ساخت ربات معامله گر: ساخت محیط کاربردی
ما در این مقاله از Tensorflow برای تعامل با محیط استفاده خواهیم کرد (همانطور که میدانید تنسورفلو یکی از کتابخانه های یادگیری ماشین است)، اما در این مرحله قصد داریم یک کلاس محیطی سفارشیسازی شده ایجاد کنیم که کلاس py_environment ارائه شده توسط کتابخانه محیطی تنسورفلو را گسترش میدهد.
import numpy as np
import pandas as pd
from tf_agents.environments import py_environment
from tf_agents.specs import array_spec
from tf_agents.trajectories import time_step as ts
from Visualization import TradingGraph as tg
tf.compat.v1.enable_v2_behavior()
class CryptoTradingEnv(py_environment.PyEnvironment):
def __init__(self, fee = 0.001, starting_date = "2018-05-29", initial_balance = 10000, look_back_window = 40):
مشخصات عمل و مشخصات مشاهده را مقداردهی اولیه میکنیم. این دو مولفه اصلی، برای کارکرد درست محیط ضروری است.
shape=(3,), dtype=np.int32, minimum=0, maximum=10, name='action')
self._observation_spec = array_spec.BoundedArraySpec(
shape=(4,5,40), dtype=np.float32, minimum=0, name='observation')
self._state = np.zeros((4,5,40), dtype=np.float32)
#parameters specific to the environment
self._episode_ended = False
self.initial_balance = initial_balance
self.wallet = [self.initial_balance]
self.look_back_window = look_back_window #how far back our agent will observe to make it's prediction
self.fee = fee #binance's commission fee per trade is 0.001
self.starting_date = starting_date
self.visual = None #used for the rendering and visualization
#set the initial step to the look back window so that our agent will have data to view on it's first step
self.current_step = self.look_back_window
self.moves = [] #stores the trades made by our agent
ef = pd.ExcelFile("data/priceData.xls") #used to get the sheets in our excel file
self.dfs = []فرآیند تکرار روی برگهها (جفتها/بازار) انجام میدهیم و:
- یک لیست خالی برای هر سکه برای ذخیره معاملات اضافه میکنیم.
- هر سکه در کیف پول را به 0.0 مقداردهی میکنیم
- هر برگه را به عنوان یک دیتافریم بارگذاری میکنیم و هر df را در لیست self.dfs ذخیره میکنیم
💎💎 اگر با مفهوم دیتافریم آشنایی کافی ندارید؛ به بخش رایگان معرفی پانداز، دیتافریم و واکاوی دادهها از دوره آموزش Pandas مراجعه کنید.
for sn in ef.sheet_names:
print("loading sheet: "+sn)
self.dfs.append(pd.read_excel('data/priceData.xls', sheet_name = sn))
print("loaded: "+sn)
self.moves.append([])
self.wallet.append(0.0)
shape=(3,), dtype=np.int32, minimum=0, maximum=10, name='action')
self._observation_spec = array_spec.BoundedArraySpec(
shape=(4,5,40), dtype=np.float32, minimum=0, name='observation')
self._state = np.zeros((4,5,40), dtype=np.float32)
#parameters specific to the environment
self._episode_ended = False
self.initial_balance = initial_balance
self.wallet = [self.initial_balance]
self.look_back_window = look_back_window #how far back our agent will observe to make it's prediction
self.fee = fee #binance's commission fee per trade is 0.001
self.starting_date = starting_date
self.visual = None #used for the rendering and visualization
#set the initial step to the look back window so that our agent will have data to view on it's first step
self.current_step = self.look_back_window
self.moves = [] #stores the trades made by our agent
ef = pd.ExcelFile("data/priceData.xls") #used to get the sheets in our excel file
self.dfs = []فرآیند تکرار را روی برگهها یا همان شیتها (جفت/بازار) انجام میدهیم و:
- یک لیست خالی برای هر سکه برای ذخیره معاملات اضافه میکنیم.
- هر سکه در کیف پول را به 0.0 مقداردهی میکنیم.
- هر برگه را به عنوان یک دیتافریم بارگذاری میکنیم و هر df را در لیست self.dfs ذخیره میکنیم.
for sn in ef.sheet_names:
print("loading sheet: "+sn)
self.dfs.append(pd.read_excel('data/priceData.xls', sheet_name = sn))
print("loaded: "+sn)
self.moves.append([])
self.wallet.append(0.0)در قطعه کد بالا دو بردار action و observation اهمیت زیادی دارند. در هر مرحله عامل ما یک سکه را برای خرید، فروش یا نگه داشتن درصدی از آنچه در حال حاضر در اختیار دارد، انتخاب میکنیم. از این رو ما آرایه numpy که shape(3) و از نوع ints است را تعریف میکنیم. اولین مقدار این آرایه یک جفت عدد است که قرار است از آن استفاده کنیم. مورد دوم، خرید، فروش یا نگهداری است و آخرین مقدار حجم معاملات است که 1 با 10%، 2 با 20% و به همین ترتیب قرار دارد.
در ارتباط با فضای مشاهده (observation)، در نظر داریم نمایندهای که ایجاد کردهایم، بازار را بهعنوان یک کل مشاهده کند و محدود به سکهای نباشد که به تازگی معامله کرده است. از اینرو، در لیستی که برای عامل تعریف میکنیم، مقادیر (4,5,40) را قرار میدهیم، جایی که مقدار 4 به چهار حالت باز (open)، زیاد (high)، پایین (low) و بسته (close) و مقدار 5 اشاره به عمق فضای مشاهده اشاره دارد. مقدار 40 نیز به دادههای تاریخی (سوابق قبلی) اشاره دارد که عامل باید به آنها مراجعه کند. شاید این فضای رصد مطلوبی نباشد که ما میخواهیم، اما تمرکز ما در این مقاله روی ساخت یک محیط پیشرفته است که اجازه دهد، فرآیندهای آزمایش و مهندسی را روی هر مولفه انجام دهیم.
همچنین، کیف پول خود را به عنوان لیستی تعریف کردیم که موجودی اولیه USD دارد. توجه داشته باشید که من از دادههای ذخیرهشده محلی به شکل صفحهگسترده اکسل استفاده میکنم، از واسطهای برنامهنویسی کاربردی (API) بایننس برای دانلود دادههای بازار برای هر جفت مجزا در صفحه گسترده استفاده میکنم:
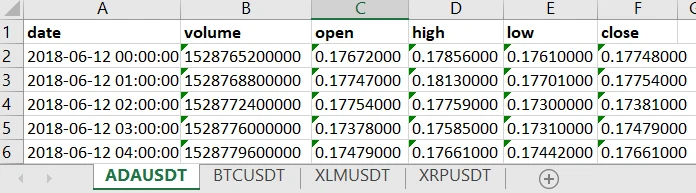
برای اجتناب از طولانی شدن بحث، اسکریپتی که برای استخراج دادهها در این قالب استفاده کردیم را بررسی نمیکنیم. در مرحله بعد، ما متد ()reset را برای بازنشانی محیط با هر بخش به شرح زیر تعریف میکنیم:
def reset(self):
"""start_time_step بازگشت به """
self.initial_time_step = ts.restart(self._state)
self.wallet = [self.initial_balance]
ef = pd.ExcelFile("priceData.xls")
for sn in ef.sheet_names:
self.wallet.append(0.0)
self.current_step = self.look_back_window
return ts.restart(self._state)مشابه عملکردی که سازنده متد ()reset دارد، دومرتبه همه چیز را از ابتدا آغاز میکنیم، به غیر از ثابتهایی مانند دادههای قیمت که در اختیار داریم. اکنون، به سراغ تابعی میرویم که عامل یک عمل (action) را انجام میدهد و یک شی گام زمانی (timestep) حاوی پاداش، وضعیت و تخفیف در هر مرحله را دریافت میکند.
def step(self, action):
"""Apply action and return new time_step."""
data = []
for df in self.dfs:
data.append(np.array([df['volume'].values[range(self.current_step-self.look_back_window, self.current_step)],
df['open'].values[range(self.current_step-self.look_back_window, self.current_step)],
df['high'].values[range(self.current_step-self.look_back_window, self.current_step)],
df['low'].values[range(self.current_step-self.look_back_window, self.current_step)],
df['close'].values[range(self.current_step-self.look_back_window, self.current_step)]]))
self._state = np.array(data)
coin = action[0]
action_type = action[1]
amount = action[2]/10.0
reward = 0
if self.wallet[0]<0.01*self.initial_balance:
self._episode_ended = True
return ts.termination(self._state, reward)
if action_type==0:
#Buy coin
current_price = data[coin][1, self.look_back_window-1]
usd_val = amount*self.wallet[0]
self.wallet[0] -= usd_val
self.wallet[coin+1] += usd_val/current_price
self.moves[coin].append(['buy', self.current_step, current_price])
if action_type==1:
#Sell coin
current_price = data[coin][1, self.look_back_window-1]
coin_val = amount*self.wallet[coin+1]
self.wallet[coin+1] -= coin_val
self.wallet[0] += coin_val*current_price
self.moves[coin].append(['sell', self.current_step, current_price])
self.current_step+=1
return ts.transition(self._state, reward, 1.0)ابتدا فهرستی از دادهها را مقداردهی اولیه کردیم که شامل دیتافریمهای موردنیاز برای وضعیت آن مرحله است. به عبارت دقیقتر، ردیفهایی در محدوده مرحله فعلی و 40 مرحله عقبتر را انتخاب کردیم. در ادامه، شرط پایان این بخش را اضافه کردیم، یعنی زمانی که عامل ما تمام پول خود را از دست میدهد.
سپس، هر یک از حالتهای خرید، فروش یا نگهداری را داریم که بر اساس آن کیف پول بهروزرسانی میشود و در نهایت گام خود را افزایش میدهیم و شی گام زمانی را به عنوان انتقال به حالت بعدی برمیگردانیم.
اگر در نظر داشته باشیم، تمامی مراحلی که الگوریتمهای یادگیری تقویتی بر مبنای آن کار میکنند را مورد استفاده قرار دهیم، محیطی که قصد ساخت آنرا داریم، پیچیده میشود و به همین دلیل از بحث پاداش صرفنظر میکنیم. هدف نهایی این است که تنها محیطی داشته باشیم که یک عامل بتواند با آن تعامل داشته باشد و بتواند به صورت بصری پردازش شود.
مرحله دوم ساخت ربات معامله گر: پردازش محیط
برای این منظور، یک شی کلاس جدید برای ترسیم نمودار دادههای قیمت و حرکت عامل به سمت نمودار شمعی که candlestick نام دارد (لازم به توضیح است که کندل استیک (Candlestick) در تحلیل فنی ارزهای دیجیتال مورد استفاده قرار میگیرد و انواع مختلفی دارد) در کلاس خود تعریف کردیم که میتوانند به شکل منظم در هر مرحله بهروزرسانی شوند.
class TradingGraph:
def __init__(self, dfs, title=None):
self.dfs = dfs
#Needed to be able to iteratively update the figure
plt.ion()
#Define our subplots
self.fig, self.axs = plt.subplots(2,2)
#Show the plots
plt.show()در حال حاضر، نمودارها را مقداردهی اولیه کردیم تا با استفاده از plt.subplots(2,2) بتوانیم چهار محور داشته باشیم که 2 سطر و 2 ستون داشته باشد.
یک کتابخانه رایج که برای نمودارهای کندل استیک استفاده میشود، mlp_finance است، اما در این مقاله تصمیم گرفتیم، تابع رسم کندل استیک خود را در کلاس TradingGraph بنویسیم:
def plot_candles(self, ax, ohlc, idx):
#iterate over each ohlc value along with the index
for row, ix in zip(ohlc, idx):
if row[3]<row[0]:
clr = "red"
else:
clr = "green"
#plots a thin line to represent high and low values
ax.plot([ix, ix], [row[1], row[2]], lw=1, color=clr)
#plot a wider line to represent open and close
ax.plot([ix, ix], [row[3], row[0]], lw=3, color=clr)تابع در یک محور، مقادیر ohlc و مقادیر شاخص را دریافت میکند، روی ردیفهای ohlc حرکت میکند تا بتواند دو خط را ترسیم کند. نمودار اول یک خط نازک است که مقادیر بالا و پایین را نشان میدهد و دومی برای باز و بسته شدن است، به طوری که در نهایت یک نمودار شمعی ترسیم شود.
در مرحله بعد باید تابعی را تعریف کنیم که تمام دادهها را دریافت کند و آنرا روی 4 قطعه فرعی رسم کند. قطعه کد زیر چنین کاری را انجام میدهد:
def render_prices(self, current_step, lbw):
for splot, df in zip(self.axs.flatten(), self.dfs):
splot.clear()
step_range = range(current_step-lbw, current_step)
idx = np.array(step_range)
#prepare a 3-d numpy array to be used by our plot_candles function
candlesticks = zip(df['open'].values[step_range],
df['high'].values[step_range],
df['low'].values[step_range],
df['close'].values[step_range])
#Plot price using candlestick graph
self.plot_candles(splot, candlesticks, idx)متغیر axs در ساختار ما، نمودارهای فرعی ما را در یک آرایه دو بعدی numpy نگهداری میکند تا بتوان از طریق شاخص به آنها دسترسی داشت. به عنوان مثال، [0,0] اولین مانند بالا، [1,0] دومین و غیره است. بنابراین از تابع flatten استفاده کردیم تا یک آرایه تک بعدی با اندازه 4 داشته باشیم. در این مرحله، میتوانیم روی دیتافریمهایی که در اینجا هر دیتافریم حاوی دادههای قیمت یک سکه است، فرآیند تکرار را انجام دهیم و نمودار را ویرایش کنیم.
برای این منظور تابعی را برای پردازش معاملات انجام شده توسط عامل به شرح زیر تعریف میکنیم:
def render_trades(self, current_step, lbw, trades):
for splot, coin in zip(self.axs.flatten(), trades):
for trade in coin:
if current_step>trade[1]>current_step-lbw:
#plot the point at which the trade happened
if trade[0]=='buy':
clr = 'red'
splot.plot(trade[1], trade[2], 'ro')
else:
clr = 'green'
splot.plot(trade[1], trade[2], 'go')
#the plotted dot won't appear after the look back window is passed so a horizontal line keeps tracks at any time
splot.hlines(trade[2], current_step-lbw, current_step, linestyle='dashed', colors=[clr])مشابه تابع قبلی، روی هر نمودار فرآیند تکرار انجام میشود تا یک خط افقی برای خریدی که انجام شده با یک نقطه اضافه شود تا نشان دهد که آن عمل (action) چه زمانی انجام شده است. همچنین، از رنگ قرمز برای نشان دادن خرید و سبز برای نشان دادن اینکه فروش چه زمانی انجام شده استفاده کردیم. در نهایت ما به روشی برای کنار هم قرار دادن همه اطلاعات نیاز داریم. تابع پردازش (Render) محیطی، اینکار را برای ما انجام میدهد.
def render(self, current_step, window_size, trades):
self.render_prices(current_step, window_size)
self.render_trades(current_step, window_size, trades)
#the draw function redraws the figure after all plots have been executed
self.fig.canvas.draw()
self.fig.canvas.flush_events()
#the pause is necessary to view the frame and allow the live updating mechanism on our figure
plt.pause(0.1)کاری که در قطعه کد بالا انجام دادیم، این بود که توابع render_prices، render_trades و matplotlib’s draw را فراخوانی کردیم. به طور معمول، نحوهی کار matplotlib به این صورت است که اگر تابع plot در هر نقطه فراخوانی شود، شکل را نشان میدهد، اما ما از plt.ion در constructor خود استفاده کردیم تا بگوییم که چه زمانی باید شکل را به روز کند. بنابراین در هر مرحله، تمام نمودارهای لازم را بهروزرسانی میکنیم و سپس draw را فراخوانی میکنیم تا شکل را با تغییرات دوباره ترسیم کند. در نهایت، plt.pause(0.1) برای نشان دادن زمان بر حسب ثانیه که بین هر فریم به طول میانجامد، مورد استفاده قرار میگیرد که برای کارکرد مکانیسم بهروزرسانی طرح زنده ضروری است.
اکنون، میتوانیم به کلاس محیطی خود برگردیم، این کلاس مصورسازی (visualization) را بهعنوان tg به برنامه import میکنیم و تابع پردازشی خود را برای استفاده از آنچه که ساختهایم، تعریف کنیم.
def render(self):
#checks if the visualization object was created
if self.visual == None:
self.visual = tg(self.dfs)
else:
#the render function gets called by the agent after each step it takes to replot the graph
self.visual.render(self.current_step, self.look_back_window, self.moves)مرحله سوم ساخت ربات معامله گر: آزمایش محیط
برای آزمایش محیطی که ایجاد کردیم، یک فایل پایتون جدید برای وارد کردن (import) محیط و تعامل با آن ایجاد میکنیم:
import numpy as np
from binanceEnv import CryptoTradingEnv
import random
#initialize our environment
env = CryptoTradingEnv()
for _ in range(0,100):
random_action = np.random.choice(np.arange(0, 3), p=[0.1, 0.1, 0.8])
random_coin = random.randint(0,3)
amount = 2
action_w = np.array([int(random_coin), int(random_action), amount])
env.step(action_w)
env.render()این محیط را برای 100 مرحله با استفاده از عمل تصادفی خرید، فروش، نگه داشتن با توزیع احتمال 0.1، 0.1، 0.8 اجرا میکنیم. سپس، یک سکه تصادفی را انتخاب میکنیم و مقدار را روی 2 قرار میدهیم. در حال حاضر، مدل بصری فعلی که ایجاد کردیم نیازی به عمل در حالت تصادفی ندارد. نتیجه نهایی در شکل زیر نشان داده شده است.
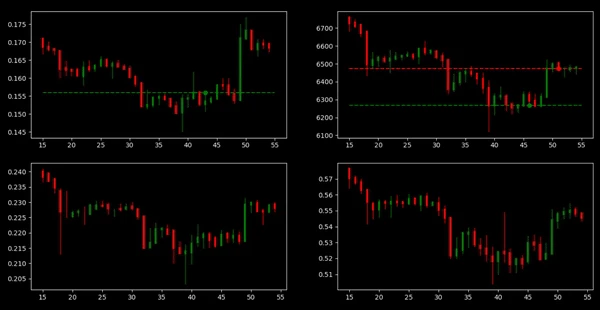
بدون شک، هنوز هم کاری زیادی برای تنظیم دقیق، اضافه کردن حاشیهنویسیها، برچسبها، مشبکسازی و غیره وجود دارد، اما با توجه به اینکه در نظر داشتیم، یک نمونه اولیه و ابتدایی ایجاد کنیم که نحوهی استفاده از تکنیکهای یادگیری تقویتی برای آموزش یک عامل را نشان دهد، محیط قابل قبولی را ایجاد کردهایم.
گام بعدی اضافه کردن یک pyenvironment tensorflow wrapper به محیط است تا مطمئن شویم که عاملهای تنسورفلو میتوانند به درستی و بدون مشکل با محیط تعامل داشته باشند که از پرداختن به این مبحث در این مقاله صرفنظر کردیم.
کلام آخر
در این مقاله، به طور اجمالی، فرآیندهایی که برای طراحی یک محیط یادگیری مبتنی بر عاملهای تقویتی تنسورفلو که قابلیت استفاده در حوزه ارزهای دیجیتال را دارند و ساخت آنها با زبان برنامه نویسی پایتون را بررسی کردیم. کد کامل این پروژه را میتوانید از این آدرس دریافت کنید.
برای آنکه بتوانید از یادگیری تقویتی در این حوزه استفاده کنید، باید دانش تئوری و عملی خود در ارتباط با پارامترها و الگوریتمهای مختلف یادگیری عمیق را افزایش دهید و در ادامه معانی اصطلاحات پر کاربرد بازار رمزارزها و نحوهی کار در این حوزه را بررسی کنید تا بتوانید یک مدل کارآمد را طراحی کنید.
پروژه فوق یکی از موضوعات جذاب و سرگرمکنندهای است که اگر وقت و زمان کافی به آن اختصاص دهید، این ظرفیت را دارد تا به عنوان یک پروژه خوب در حوزههای مالی، مورد استفاده قرار گیرد.