در این مقاله به بررسی این موضوع خواهیم پرداخت که Deep Learning که معادلهایی همچون «یادگیری ژرف» و «یادگیری عمیق» در فارسی برایش در نظر گرفته شده چیست و چگونه کار میکند.
آشنایی با تعاریف هوش مصنوعی و یادگیری ماشین
به طور خلاصه، هوش مصنوعی عبارت است از شبیهسازی هوش انسان در سیستمهای کامپیوتری و نخستین بار که پژوهشها در زمینهٔ هوش مصنوعی آغاز شد، تلاش پژوهشگران بر این بود تا با توانمندسازی کامپیوترها آنها را قادر سازند تا وظایف تعریفشدهای مانند بازی کردن را انجام دهند که برای کسب اطلاعات بیشتر در این باره، میتوانید به مقاله هوش مصنوعی چیست؟ مراجعه نمایید.
یک تعریف ساده از یادگیری ماشین هم عبارت است از توانایی ماشین برای یادگیری با استفاده از مجموعهای از دادهها و عمل بر اساس آنها و نه صرفاً بر اساس قوانین تعریفشده و ثابتی که از قبل کدنویسی شدهاند. به زبان سادهتر، یادگیری ماشینی این امکان را برای ماشین (سیستم) فراهم میآورد تا خود به تنهایی بتواند چیزی را بیاموزد به طوری که در یادگیری ماشینی از قدرت پردازش کامپیوترهای مدرن به منظور تحلیل مجموعههای بزرگ دیتا استفاده میشود که برای آشنایی بیشتر با این موضوع، میتوانید به مقالهٔ یادگیری ماشینی چیست؟ مراجعه نمایید.
💎💎 در مورد تفاوتهای یادگیری ماشین، هوش مصنوعی و یادگیری عمیق در مقالهی مربوطه به صورت مفصل توضیح داده شده است.
مفهوم Supervised Learning و Unsupervised Learning چیست؟
Supervised Learning (یادگیری نظارتشده) عبارت از بهکارگیری دادههای تگگذاریشده و ارائهٔ خروجیهای متناسب است. به عبارت دیگر، آموزش سیستم با روش یادگیری نظارتشده بدین صوررت است که یک ورودی به سیستم وارد شده و خروجی متناسب با آن تولید میشود و سپس کامپیوتر خروجی ارائهشده را با خروجیای که خود تولید نموده مقایسه میکند و در صورت وجود مغایرت، محاسبات خود را برای تصمیمگیریهای بعدی اصلاح مینماید و این فرآیند آنقدر تکرار میشود تا سیستم دیگر دچار اشتباه نشود و قادر باشد با دریافت یک داده، خروجی متناسب با آن را ارئه نماید. یک نمونه از کاربردهای یادگیری نظارتشده را میتوان در پیشبینی وضع هوا مشاهده نمود بدین صورت که اطلاعات آموزشی از قبیل فشار، رطوبت، سرعت باد و … به عنوان دادهٔ ورودی وارد شده و دادهٔ خروجی آن پیشبینی وضع هوا خواهد بود.
Unsupervised Learning (یادگیری نظارتنشده) فرآیند یادگیری با استفاده از مجموعهای از دادهها ساختارنیافته است. هنگامی که یک سیستم مبتنی بر هوش مصنوعی با استفاده از روش یادگیری نظارتنشده آموزش میبیند، دادهها به صورت منطقی طبقهبندی شده و مورد تحلیل قرار میگیرند. یک مثال ملموس از یادگیری نظارتنشده استفاده از هوش مصنوعی در پیشبینی رفتار کاربران در یک وبسایت تجارت الکترونیک (فروشگاه آنلاین) است. در این فرآیند، هوش مصنوعی نه بر اساس یک مجموعه دیتای ورودی و خروجی بلکه بر مبنای طبقهبندی خود از دادههای ورودی آموزش میبیند و پس از آن میتواند خریدهای بعدی کاربران را پیشبینی نماید.
یادگیری عمیق چیست؟
اکنون که به تفاوت این چند اصطلاح رایج پی بردیم، میتوانیم به بررسی سازوکار Deep Learning بپردازیم. یادگیری عمیق یکی از روشهای یادگیری ماشین است که این امکان را برای یک سرویس مبتنی بر هوش مصنوعی فراهم میسازد تا هم از طریق یادگیری نظارتشده و یادگیری نظارتنشده آموزش ببیند.
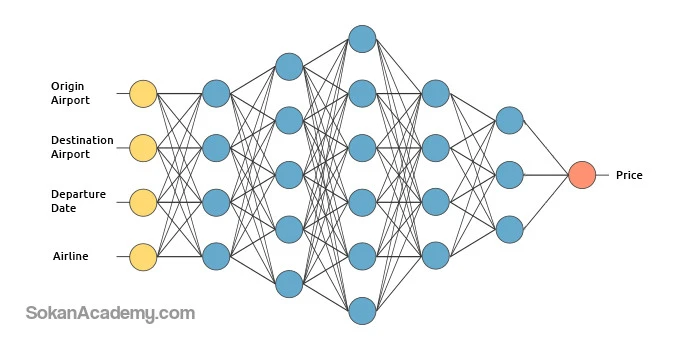
برای درک بهتر این موضوع، در ادامه با ایجاد یک سرویس فرضی تخمین قیمت بلیط هواپیما، نحوهٔ کار یک سیستم نیروگرفته از یادگیری عمیق با استفاده از یادگیری نظارتشده را تشریح خواهیم نمود. در واقع، در این مثال قصد داریم تا این سرویس قیمت بلیط هواپیما را بر مبنای چهار فاکتور زیر پیشبینی نماید:
- فرودگاه مبداء
- فرودگاه مقصد
- تاریخ پرواز
- خط هوایی
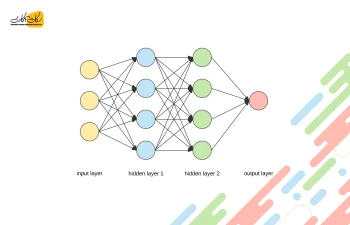
برای شروع، اجازه بدهید به ساختار درونی هوش مصنوعی نگاهی بیندازیم. هستهٔ یک سیستم مبتنی بر هوش مصنوعی، مانند مغز موجودات زنده، از نورونها (سلولهای عصبی) تشکیل شده است و همانطور که در تصویر زیر ملاحظه میکنید، نورونها به صورت دایرههایی نمایش داده شدهاند که به سه لایهٔ مختلف تقسیم میشوند:
- لایهٔ ورودی (Input Layer)
- لایههای پنهان (Hidden Layers)
- لایهٔ خروجی (Output Layer)
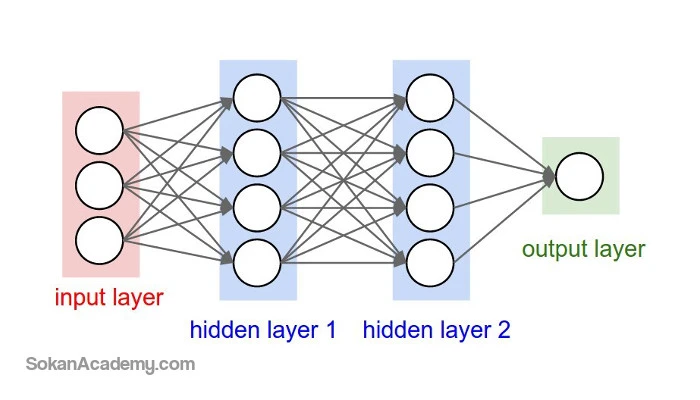
لایه ورودی، همانطور که از نام آن پیدا است، دادههای ورودی را دریافت نموده و آنها را به نخستین لایهٔ پنهان انتقال میدهد. به عنوان مثال، در سرویس تخمین قیمت بلیط چهار نورون در لایهٔ ورودی وجود دارد که هر یک از آنها یکی از دادههای ورودی فرودگاه مبداء، فرودگاه مقصد، تاریخ پرواز و خط هوایی را دریافت میکنند. لایهٔ پنهان محاسبات ریاضیاتی را بر روی دادههای ورودی انجام میدهد که در این بین یکی از چالشهای ایجاد شبکههای عصبی، تصمیمگیری در مورد تعداد لایههای پنهان و همچنین تعداد نورونهای موجود در هر لایه است. در واقع، در Deep Learning کلمهٔ Deep به معنی «عمیق» به حالتی اشاره دارد که بیش از یک لایهٔ پنهان در شبکه عصبی وجود داشته باشد. در نهایت، لایهٔ خروجی دادههای خروجی را به ما برمی گرداند که به عنوان مثال در سرویس تخمین قیمت بلیط که در بالا بدان اشاره شد، این دادهٔ خروجی چیزی نیست جز قیمت پیشبینیشدهٔ بلیط هواپیما:
یادگیری عمیق چگونه کار میکند؟
اکنون پرسش اینجا است که «این قیمت چگونه محاسبه میشود؟» و این همان جایی است که پای جادوی یادگیری ژرف به میان میآید. هر یک از کانکشنها (ارتباطات) میان نورونها دارای وزنی است و این وزن هر یک از این کانکشنها است که میزان اهمیت آن را تعیین میکند. معمولاً وزنهای اولیه به صورت تصادفی تنظیم میشوند اما عملاً برخی از کانکشنها اهمیت بیشتری داشته و باید وزن بیشتری برای آنها در نظر گرفته شود. به عنوان مثال، از آنجا که در تعیین قیمت بلیط، تاریخ پرواز نقش خیلی مهمی دارد، بنابراین کانکشن نورونی مربوط به این فاکتور وزن بیشتری باید داشته باشد.
اساساً آموزش دادن یک سیستم مبتنی بر هوش مصنوعی یکی از دشوارترین بخشهای یادگیری ژرف است زیرا برای این منظور، به موارد زیر نیاز خواهیم داشت:
- به یک مجموعهٔ بزرگی از دادهها
- زیرساخت کافی برای انجام محاسبات
به طور خلاصه، هنگامی که مجموعهای از دادههای ورودی از تمام لایههای شبکهٔ عصبی عبور میکند، ما یک دادهٔ خروجی و یا مجموعهای از دادههای خروجی را در لایهٔ خروجی شبکهٔ عصبی دریافت خواهیم نمود. به عنوان مثال، برای ایجاد سرویس تخمین قیمت بلیط هواپیما به دادههای قدیمی قیمت بلیط، فهرستی از فرودگاهها، فهرستی از تاریخ پروازها و فهرستی از خطوط هوایی نیاز داریم. برای آموزش دادن هوش مصنوعی هم دادههای ورودی به سیستم ارائه میشوند و از آنجا که هوش مصنوعی هنوز آموزش ندیده است، ممکن است خروجیهای نادرستی تولید نماید! سپس دادههای خروجی متناسب با دادههای ورودی به آن ارائه شده و خروجی تولیدی توسط الگوریتمهای هوش مصنوعی با خروجی درست مقایسه میشود و نتیجهٔ این مقایسه در تصمیمگیریهای بعدی اِعمال میگردد.
چگونه ضریب خطای هوش مصنوعی را به حداقل برسانیم؟
هنگامی که این فرآیند در مورد تکتک عناصر یک مجموعه داده انجام شد، میتوان فانکشنی به نام Cost Function را ایجاد نمود که نشان میدهد هوش مصنوعی تا چه حد اشتباه عمل کرده است. به طور ایدهآل، ما میخواهیم که مقدار این تابع را به صفر برسانیم به طوری که آنقدر فرآیند آموزش را ادامه دهیم تا خروجیهای سیستم کاملاً بر خروجیهای درست منطبق بوده و هیچ مورد اشتباهی وجود نداشته باشد.
برای کاهش مقدار Cost Function هم میتوان وزن هر یک از کانکشنهای میان نورونها را به طور تصادفی آنقدر تغییر داد تا زمانی که این تابع به اندازهٔ ایدهآل برسد. با این حال، این روش کارآمدی نیست بلکه به جای تغییر تصادفی وزن کانکشنها، بهتر است از روشی به نام Gradient Descent استفاده کنیم که به منزلهٔ تکنیکی است که امکان پیدا کردن کمترین مقدار Cost Function را برای ما فراهم میآورد. سازوکار این تکنیک بدین صورت است که پس از ورود هر مجموعهٔ داده، تغییر اندکی در وزن کانکشنها ایجاد نموده سپس با مُشتقگیری از Cost Function در هر دور از آموزش میتوانیم حداقل به این موضوع پی ببریم که کمترین مقدار آن در کدام جهت نمودار قرار دارد. برای روشنتر شدن موضوع، به نمودار زیر دقت کنید:
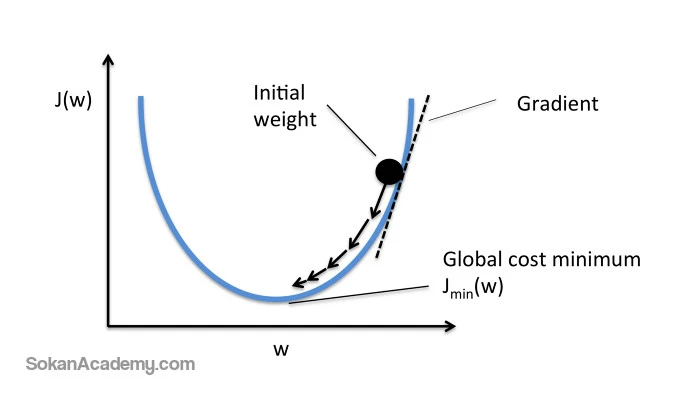
برای به حداقل رساندن میزان این تابع نیاز به تکرار چندین بارهٔ آموزش با یک مجموعه داده مشخص داریم و به همین دلیل به توان محاسباتی بالا نیاز خواهیم داشت. در واقع، تنظیم مجدد وزن کانکشنها با استفاده از تکنیک Gradient Descent به صورت خودکار انجام میشود و این همان جادوی یادگیری ژرف (دیپ لرنینگ یا همان یادگیری عمیق) است که پس از آموزش کامل، سرویس تخمین قیمت بلیط هواپیما قادر خواهد بود تا قیمتهای آینده را برای ما پیشبینی نماید.