
یادگیری ماشین (Machine Learning یا ماشین لرنینگ) یکی از زیرشاخههای هوش مصنوعی (Artificial Intelligence) بوده و این در حالی است که یکی از اهداف یادگیری ماشین درک ساختار دیتا و سپس قرار دادن دیتا در مدلهایی است که برای سیستم قابلفهم و استفاده باشد. در واقع، اگر سیستمی بتواند به صورت خودکار از محیط پیرامونش درس گرفته و عملکرد خود را بهبود بخشد، میگوییم یادگیری توسط آن سیستم صورت گرفته است.
هرچند یادگیری ماشین یکی از رشتههای علوم کامپیوتر است، اما با روشهای محاسباتی مرسوم و رایج در این علم تفاوتهایی دارا است. در روشهای محاسباتی رایج، الگوریتمها به صورت مجموعهای از دستورات صریح و مشخص به منظور انجام محاسبات و یا حل مسئله و با هدف اجرا در کامپیوترها نوشته میشوند اما در یادگیری ماشین سیستمها با دریافت ورودیهای مختلف و انجام تحلیلهای آماری برای ایجاد خروجیهایی در یک بازهٔ آماری مشخص، خود اقدام به یادگیری میکنند و از همین روی یادگیری ماشین این امکان را برای کامپیوترها فراهم میکند تا پس از دریافت دیتای نمونه و مدلسازی آن، به طور خودکار قادر به انجام فرایند Decision Making (تصمیمگیری) در مورد دادههای ورودی جدید باشند.
امروزه در اغلب تکنولوژیها از یادگیری ماشین استفاده میشود. برای مثال، میتوان به تکنولوژی تشخیص چهره، تکنولوژی تبدیل تصویر به متن و … اشاره نمود و به عنوان نمونه کاربردهای پیشرفتهتر هم میتوان به خودروهای خودران (بدون راننده) اشاره کرد که قادر هستند با استفاده از یادگیری ماشین مسیریابی انجام دهند و در حین رانندگی تصمیمی درست اتخاذ کنند.
سه رویکرد اصلی در یادگیری ماشین
یادگیری ماشینی یک حوزهٔ همواره در حال گسترش است و آنچه در این مقاله مد نظر خواهیم داشت، نگاهی به رویکردها و روشهای رایج در یادگیری ماشین خواهیم انداخت که در سه بخش یادگیری Supervised (نظارتشده)، Unsupervised (نظارتنشده) و Reinforcement (تقویت شده) تقسیمبندی میشوند و پس از آن رویکردهای الگوریتمی معمول در یادگیری ماشین را مورد بررسی قرار میدهیم و در انتها هم نقاط قوت هر یک از معمولترین زبانهای مورد استفاده در یادگیری ماشین را نیز مورد بررسی قرار خواهیم داد.
در یادگیری ماشین، تَسکها بر مبنای روش یادگیری و یا به عبارتی بر اساس نحوهٔ فیدبکدهی به سیستم در حین یادگیری در چند گروه عمده تقسیمبندی میشوند. به طور کلی، سه روش اصلی در یادگیری ماشین مورد استفاده قرار میگیرد که عبارتند از:
1. Supervised Learning (یادگیری نظارتشده)
به منظور آموزش الگوریتم در یادگیری ماشین نظارتشده، دیتایی به عنوان ورودی اولیه در اختیار سیستم قرار میگیرد که قبلاً توسط عامل انسانی با خروجی مطلوب و مورد انتظار به اصطلاح Labeled (برچسبزده) شده است و از همین روی ورودیها و خروجیهای مطلوب متناظر با آنها به صورت جفتهای ورودی/خروجی در اختیار سیستم قرار میگیرند.
هدف از ارائهٔ این جفتهای ورودی/خروجی این است که الگوریتم با مقایسهٔ پاسخ درست که از پیش تعیین شده است و پاسخی که خود پیشبینی کرده، خطاهای موجود را شناسایی کند و به این ترتیب برای ایجاد خروجیهای بعدی آموزش دیده و مدل مورد استفادهٔ خود را بر اساس این آموزشها اصلاح نماید و فرایند آموزش تا زمانی که مدل پیشبینی الگوریتم به دقت کافی برسد و نتایج پیشبینی با نتیجهٔ از قبل تعیین شده یکسان باشند ادامه خواهد یافت و از همین روی در یادگیری نظارتشده سیستم پس از آموزش دیدن و با استفاده از الگوهایی که در طی آموزش ایجاد نموده، قادر خواهد بود تا در مواجهه با دیتای به اصطلاح Unlabeled (بدون برچسب)، خروجی مناسب را پیشبینی نماید (از جمله الگوریتمهای یادگیری نظارتشده میتوان به Regression ،Decision Tree ،Random Forest ،KNN و Logistic Regression اشاره نمود.)
به عنوان مثال، فرض کنید در این روش الگوریتم یادگیری با تصاویری از ماهی و تصاویری از اقیانوس که به ترتیب تحت عنوان Fish و Ocean برچسبدار شدهاند، مورد آموزش قرار گیرد. این الگوریتم پس از آموزش دیدن با این تصاویر و برچسبها، قادر خواهد بود تا تصاویر بدون برچسب ماهی و اقیانوس را به ترتیب به عنوان Fish و Ocean مورد شناسایی قرار داده و این تصاویر را با برچسب تصاویری که با آنها آموزش دیده یکسان قلمداد کند.
یکی از کاربردهای رایج یادگیری نظارتشده زمانی است که با استفاده از اطلاعات گذشته قرار است اتفاقات آیندهٔ نزدیک مورد پیشبینی قرار گیرند. به عنوان مثال، با این روش میتوان اطلاعات چند ماه یا چند هفتهٔ اخیر بازار سهام را برای پیشبینی نواسانات بازار در هفتهها و ماههای آتی مورد استفاده قرار داد. یک نمونهٔ دیگر استفاده از این الگوریتم نیز در تشخیص ایمیلهای اسپم (هرزنامه) از غیر اسپم است.
2. Unsupervised Learning (یادگیری نظارت نشده)
در یادگیری ماشین نظارت نشده، دیتای ورودی فاقد هرگونه برچسب است و از همین روی هم الگوریتم یادگیری به دنبال مشابهتها و ویژگیهای مشترک دیتای ورودی میگردد و از آنجا که دادههای بدون برچسب معمولتر و فراگیرتر از دادههای برچسبدار هستند، این روش یادگیری از اهمیت ویژهای برخوردار است. به عبارتی، هدف یادگیری نظارتنشده شناسایی الگویهای پنهان موجود در مجموعهٔ دادههای فاقد برچسب است. در واقع، با استفاده از الگوریتمهای یادگیری نظارتنشده، سیستم قادر خواهد بود تا ویژگیهای دادههای مختلف را شناسایی نموده و از این ویژگیها برای دستهبندی دادههای مد نظر استفاده نماید.
این روش یادگیری عمدتاً در مورد دادههای تجاری مورد استفاده قرار میگیرد. به عنوان مثال، ممکن است مجموعهای از اطلاعات مشتریهای یک شرکت شامل مشخصات فردی آنها و فهرست خریدهای ایشان در دسترس باشد. هر چند این اطلاعات ممکن است جامع و کامل باشند، اما شناسایی الگوی موجود در این دادهها حداقل به راحتی امکانپذیر نیست و برای تشخیص الگوی پنهان موجود در چنین دادههایی میتوان آنها را به یک الگوریتم یادگیری به اصطلاح Unsupervised وارد نمود (Apriori algorithm و K-means مثالهایی از الگوریتمهای یادگیری نظارتنشده هستند.)
در مثال فوق، با بهکارگیری الگوریتم یادگیری نظارتنشده ممکن است در نهایت مشخص شود که مثلاً خانمهایی که در یک بازهٔ سنی خاص قرار دارند و صابون بدونبو خریداری نمودهاند، احتمالاً باردار هستند. بدین ترتیب با شناسایی این الگو و از آنجا که این مشتریان احتمالاً به محصولات مرتبط با دوران بارداری و پس از بارداری نیاز دارند، اگر پیشنهادات مرتبط با بارداری و مراقبت نوزاد نیز در اختیار این دسته از مشتریان قرار گیرد، احتمال خرید این محصولات بالاتر خواهد رفت.
3. Reinforcement Learning (یادگیری تقویتی)
در یادگیری تقویتی، الگوریتم با وارد شدن به چرخه آزمون و خطا میآموزد که تصمیمات مشخصی را اتخاذ نماید و به این ترتیب با توجه به تصمیمات قبلی، پیشبینیها و تصمیمات بعدی خود را اصلاح نموده و به طور پیوسته در حال آموختن است (Markov Decision Process یکی از الگوریتمهای یادگیری تقویتی است.)
برای روشنتر شدن مطلب و به عنوان یک مثال کاربردی، میتوان ربات فوتبالیستی را در نظر گرفت که با قرار گرفتن در موقعیتهای مختلف و اتخاذ تصمیمهای متناسب با این موقعیتها و رفع تدریجی خطاهای خود، سرانجام میآموزد که در هر موقعیتی درستترین تصمیم را برای شوت زدن بگیرد.
درآمدی بر ارتباط مابین یادگیری ماشین و آمار
از آنجا که مقولهٔ یادگیری ماشین ارتباط نزدیکی با آمار دارد، آشنایی با مفاهیم آماری در درک و بهکارگیری الگوریتمهای یادگیری ماشین نقش بهسزایی خواهد داشت و از همین روی قبل از مطرح نمودن رایجترین الگوریتمهای یادگیری ماشین، توضیح مختصری در مورد دو مفهوم آماری Correlation (همبستگی) و Regression (رگرسیون) ارائه خواهیم داد.
Correlation (همبستگی) عبارت است از میزان وابستگی دو متغییر نسبت به یکدیگر که با ضریبی به نام ضریب همبستگی نشان داده میشود که مقدار آن عددی مابین ۱ و ۱- است. ضریب همبستگی ۰ میان دو پارامتر به این معنا است که این پارامترها هیچگونه وابستگی نسبت به یکدیگر ندارند و هر چهقدر ضریب همبستگی دو پارامتر از ۰ دورتر باشد، به معنای این است که تغییرات دو پارامتر وابستگی بیشتری به یکدیگر دارند.
مثبت بودن ضریب همبستگی هم به این معنا است که اگر یکی از دو پارامتر افزایش یابد، دیگری نیز افزایش خواهد یافت و اگر یکی از آنها کاهش یابد، دیگری نیز کاهش خواهد یافت اما منفی بودن ضریب همبستگی به معنای وابستگی معکوس میان دو پارامتر است. به عبارت دیگر، اگر یکی از آنها کاهش پیدا کند، دیگری افزایش مییابد و اگر یکی افزایش پیدا کند، دیگری کاهش خواهد یافت. به عنوان مثال، همبستگی میان قد و وزن انسانها معمولاً یک همبستگی مثبت است و هر چه قد افراد بلندتر باشد، وزن آنها نیز بیشتر است (البته همواره استثناءهایی وجود خواهد داشت.)
Regression در لغت به معنای «بازگشت» است. هنگامی که دو متغیر با یکدیگر همبستگی بالایی داشته باشند، رگرسیون پیشبینی و بیان تغییرات یک متغیر بر اساس تغییرات متغیر دیگر را امکانپذیر میسازد (برای آشنایی بیشتر با برخی مفاهیم آماری توصیه می کنیم به دوره آموزش مقدماتی آمار در پایتون مراجعه نمایید.)
آشنایی با الگوریتمهای کاربردی در یادگیری ماشین
الگوریتمها و رویکردهای بهکاررفته در یادگیری ماشین همواره در حال تغییر و پیشرفت هستند که در ادامه چند مورد از مرسومترین آنها را مورد بررسی قرار دادهایم.
K-nearest Neighbor (نزدیکترین همسایه)
الگوریتم K-NN یا نزدیکترین همسایه، یک مدل شناسایی الگو است که هم در مورد طبقهبندی و هم در مورد تعیین رگرسیون دادهها قابلاستفاده است. برای استفاده از این الگوریتم لازم است تا یک مجموعهٔ داده و یک معیار برای محاسبهٔ شباهتها در دست داشته باشیم (همچنین مقدار K نیز باید تعیین شود.) K در این الگوریتم یک عدد صحیح مثبت و معمولاً کوچک است و این در حالی است که معمولاً در نظر گرفتن مقادیر فرد برای K مناسبتر است. برای روشنتر شدن مطلب به این مثال توجه کنید.
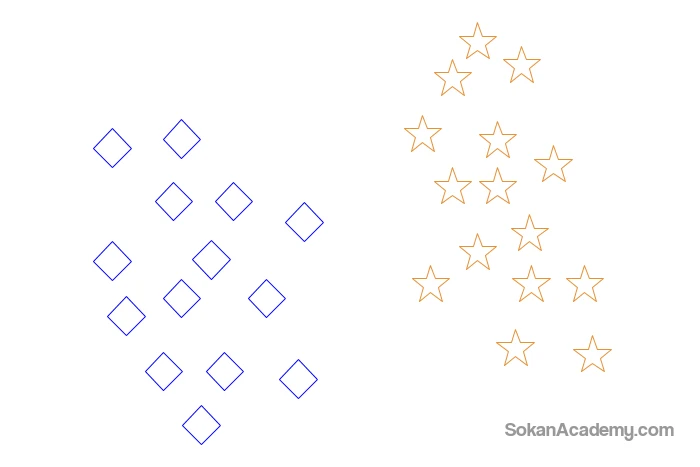
در نمودار زیر دو دسته وجود دارد؛ یکی مربعهای آبی رنگ و دیگری ستارههای نارنجی رنگ. این اشکال در دو دستهٔ مجزا طبقهبندی شدهاند که این دستهها عبارتند از دستهٔ مربع و دستهٔ ستاره:
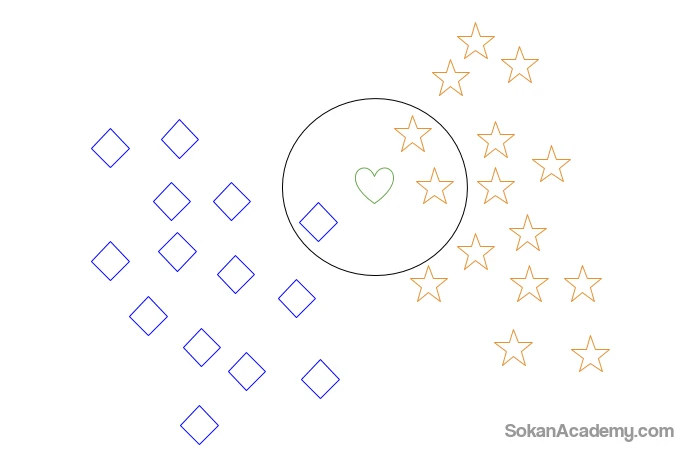
فرض کنیم مانند آنچه که در نمودار زیر دیده می شود، یک دادهٔ جدید به مجموعهٔ دادهها اضافه شود که در اینجا به شکل قلب سبز رنگ نشان داده شده است:

حال میخواهیم با استفاده از الگوریتم K-NN، این دادهٔ جدید را در یکی از دو دستهٔ موجود قرار دهیم. اگر K را برابر با ۳ در نظر بگیریم، این بدین معنا است که به الگوریتم گفتهایم که ۳ مورد از نزدیکترین همسایههای این دادهٔ جدید را شناسایی کرده و سپس با توجه به اینکه در بین این ۳ مورد اعضای کدام دسته غالب است، دادهٔ جدید را در همان دسته قرار بدهد. با توجه به نمودار زیر میبینیم که نزدیکترین همسایههای این دادهٔ جدید عبارتند از ۲ ستاره و ۱ مربع و از همین روی این دیتای جدید در دستهٔ ستاره طبقهبندی خواهد شد:
Decision Tree (درخت تصمیم)
در کاربردهای عمومی، درخت تصمیم به منظور نمایش دادن روند تصمیمگیری مورد استفاده قرار میگیرد اما این رویکرد در یادگیری ماشین و کار با دادهها به عنوان یک مدل پیشبینی نیز به کار میرود. هدف از بهکارگیری درخت تصمیم ایجاد مدلی است که بتواند بر مبنای دادههای ورودی، تصمیم مورد نظر را اتخاذ نماید. به عبارتی، در درخت تصمیم دادهٔ اصلی بر مبنای شرایط مختلف به زیرشاخههایی تقسیم میشود و این زیرشاخهها نیز بسته به شرایط فرعیتر به زیرشاخههای دیگری تقسیم میشوند و پروسهٔ تقسیم شدن تا زمانی ادامه مییابد که در یکی از شاخهها، نتیجهٔ ایجاد شده با نتیجهٔ مورد نظر برابر شود.
به مثال زیر که بسیار ساده و ابتدایی بوده و صرفاً جهت روشن شدن مطلب ارائه شده است دقت کنید. در این مثال، یک درخت تصمیم ساده رسم شده است که میتواند در مورد رفتن یا نرفتن به ماهیگیری تصمیم بگیرد. این درخت بر اساس شرایط مؤثر در تعیین آبوهوا به سه زیرشاخه و سپس به زیرشاخههای دیگری تقسیم شده است:
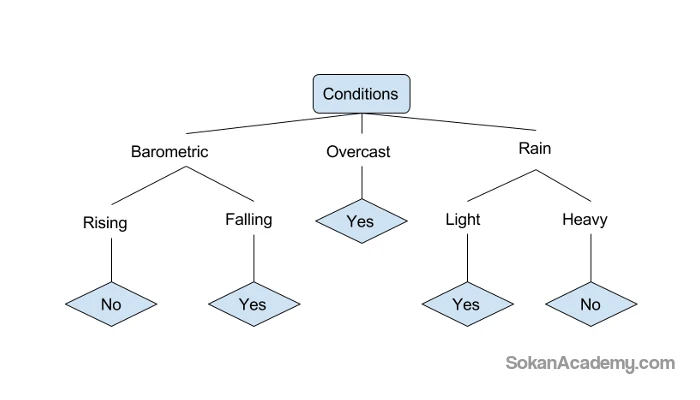
همانطور که در تصویر فوق مشاهده میشود، هنگامی که پاسخ Yes و یا No مشخص شود، شاخهها دیگر به شاخههای جدیدی تقسیم نخواهند شد چرا که به هدف دست یافتهایم.
💎💎 در مورد تفاوتهای یادگیری ماشین، هوش مصنوعی و یادگیری عمیق در مقالهی مربوطه به صورت مفصل توضیح داده شده است.
زبانهای برنامهنویسی مورد استفاده در یادگیری ماشین
به نظر میرسد که زبان برنامهنویسی Python مناسبترین زبان برای پیادهسازی الگوریتمهای یادگیری ماشین باشد و پس از آن میتوان زبانهای R ،Java و ++C را جزو گزینههای بعدی در نظر گرفت.
- پایتون: محبوبیت این زبان در زمینهٔ یادگیری ماشین شاید به دلیل افزایش تنوع فریمورکهای مرتبط با هوش مصنوعی برای این زبان باشد که از آن جمله میتوان به TensorFlow ،PyTorch و Keras اشاره کرد. همچنین دلایلی مانند سینتکس سادهٔ زبان پایتون در محبوب بودنش بیتأثیر نبوده است. از دیگر عوامل محبوبیت این زبان در زمینهٔ هوش مصنوعی میتوان به قدرت و سرعت آن در کار با دادهها و تحلیل دادهها اشاره نمود. مثلاً Scikit-learn که بر مبنای پکیجهای Numby، SciPy و Matolotlib توسعه یافته است، یکی از لایبرریهای پایتون برای استفاده در زمینهٔ یادگیری ماشین است (برای شروع یادگیری این زبان میتوانید به دورهٔ آموزش آنلاین و رایگان پایتون در سکان آکادمی مراجعه نمایید.)
- جاوا: زبان برنامهنویسی جاوا نیز توسط بسیاری از برنامهنویسان در سطوح تجاری و همچنین توسط برخی از برنامهنویسان با هدف پیادهسازی الگوریتمهای یادگیری ماشین در پروژههای خود مورد استفاده قرار میگیرد. هر چند این زبان برای دولوپرهایی که به تازگی شروع به یادگیری آن نمودهاند زبان مناسبی برای اهداف یادگیری ماشین نیست، اما برای دولوپرهایی که تسلط خوبی بر این زبان دارند انتخاب خوبی تلقی میگردد. زبان جاوا در برخی زمینههای یادگیری ماشین مانند امنیت شبکه، تشخیص تقلب و کلاهبرداری و همچنین حفاظت در مقابل حملههای سایبری کاربرد دارد و از جمله لایبرریهای این حوزه هم میتوان به Deeplearning4j و MALLET اشاره کرد (برای شروع یادگیری زبان برنامهنویسی جاوا میتوانید به دورهٔ آموزش آنلاین و رایگان جاوا در سکان آکادمی مراجعه نمایید.)
- آر: زبان آر که ابتدا به ساکن با اهداف محاسبات آماری مورد استفاده قرار میگرفت به مرور در میان دولوپرها به محبوبیت رسید و در محافل دانشگاهی نیز محبوبیت بالایی به دست آورد. هر چند این زبان در محیطهای صنعتی کاربرد زیادی ندارد اما به دلیل پررنگتر شدن اهمیت دادهکاوی، شاهد کاربرد بیش از پیش آن در اپلیکیشنهای صنعتی هم هستیم. برای استفاده از این زبان در یادگیری ماشین میتوان پکیجهایی مانند caret ،randomForest و e1071 را به کار برد.
- سیپلاسپلاس: این زبان نیز یکی از ابزارهای مناسب برای استفاده در حوزهٔ یادگیری ماشین و هوش مصنوعی در زمینههایی مانند ساخت گیم و ربات است. توسعهدهندگان سختافزار سیستمهای اِمبِدد و مهندسان الکترونیک هم به دلیل کارایی زبانهایی مانند C و یا ++C، بیشتر به استفاده از این زبانها در یادگیری ماشین علاقمندند چرا که این دو زبان به زبان ماشین (صفر و یک) نزدیکتر بوده و میتوانند ارتباط بهتری با سختافزار ایجاد کنند. برخی از لایبریهای مورد استفاده در هوش مصنوعی مناسب برای زبان ++C هم عبارتند از mlpack ،Dlib و Shark.
علاوه بر زبانهای فوقالذکر، زبانهای دیگری هم هستند که در حوزه ماشین لرنینگ یا همان یادگیری ماشین مورد توجه قرار گرفتهاند که برای آشنایی بیشتر با آنها میتوانید به مقالهٔ معرفی زبانهای برنامهنویسی مناسب برای یادگیری ماشین مراجعه نمایید. همچنین جهت آشنایی با فریمورکهای رایج در این حوزه، میتوانید به مقالهٔ معرفی برخی فریمورکهای یادگیری ماشین برای پایتون مراجعه نمایید.
نتیجهگیری
یادگیری ماشین و به طور کلی فناوری هوش مصنوعی امروزه جایگاه مهمی در علوم کامپیوتر به خود اختصاص داده و روز به روز در حال گستردهتر شدن و پیشرفت است. از آنجا که یادگیری ماشین و جنبههای مختلف آن مقولهای بسیار گسترده است، در این مقاله به ذکر خلاصهای از مفاهیم، کاربردها، روشها، رویکردها و زبانهای مورد استفاده در یادگیری ماشین بسنده نمودیم.