
یادگیری تقویتی (Reinforcement Learning) یکی از انواع روشهای یادگیری ماشین است که به یک عامل (Agent) این امکان را میدهد تا از تعامل با محیط و از طریق آزمون و خطا یاد بگیرید. عامل، بازخوردهایی از محیط میگیرد و تجربههایی از محیط کسب میکند که همه به یادگیریش کمک میکنند. در این مطلب بیشتر با این رویکرد یادگیری ماشین، کاربردهایش، الگوریتمهای معروف و چالشهای پیادهسازی آن آشنا خواهیم شد.
تفاوت یادگیری تقویتی با سایر روشهای یادگیری ماشین
یادگیری تقویتی را میتوان شاخهای مجزا در یادگیری ماشین در نظر گرفت؛ هرچند شباهتهایی هم با سایر روشهای یادگیری ماشین دارد. برای دریافتن این شباهتها و تفاوتها بهتر است نگاهی به سایر روشهای یادگیری ماشین هم نگاهی داشته باشیم.
یادگیری نظارتی (supervised learning)
در یادگیری نظارتی، الگوریتمها با استفاده از یک سری داده برچسبدار آموزش داده میشوند. این الگوریتمها فقط ویژگیهایی را یاد میگیرند که در دیتاست مشخص شده است و به آنها هدف یا target گفته میشود. در واقع «هدف» در این نوع یادگیری کاملا تعریف شده است و نمونههای از داده و پاسخ درست در اختیار مدل قرار میگیرد تا با استفاده از آنها بتواند هر دادهی جدیدی را که میبیند برچسب بزند.
یکی از رایجترین کاربردهای یادگیری نظارتی، مدلهای تشخیص تصویر است. این مدلها یک مجموعه عکس برچسبدار دریافت میکنند و یاد میگیرند بین ویژگیهای متداول آنها تمایز قائل شوند. به عنوان مثال با دریافت عکسهایی از صورت انسانها، میتوانند اجزای صورت را تشخیص دهند. یا بین دو یا چند حیوان تمایز قائل شوند.
یادگیری غیر نظارتی (unsupervised learning)
در یادگیری غیرنظارتی، فقط دادههای بدون برچسب در اختیار الگوریتم قرار داده میشود. این الگوریتمها بدون اینکه مستقیم به آنها گفته شده باشد دنبال چه ویژگیها بگردند، براساس مشاهده های خودشان آموزش میبینند. نمونهای از کاربرد این نوع یادگیری، خوشهبندی مشتریها است.
یادگیری نیمه نظارتی (semi supervised learning)
این روش، روشی بینابینی است. توسعهدهندگان، یک مجموعه نسبتا کوچک از دادههای برچسبدار و یک مجموعه بزرگتر از داده بدون برچسب آماده میکنند. سپس از مدل خواسته میشود، براساس چیزی که از دادههای برچسبدار یاد میگیرد، درمورد دادههای بدون برچسب هم پیشبینی انجام دهد و در نهایت دادههای بدون برچسب و برچسبدار را به عنوان یک مجموعه داده کل درنظر بگیرد و نتیجهگیری نهایی را انجام دهد.
یادگیری تقویتی (Reinforcement Learning)
رویکرد یادگیری تقویتی کاملا متفاوت است. در این روش، یک عامل در محیط قرار میگیرد تا با آزمون و خطا یاد بگیرد کدام کارها مفید و کدام کارها غیرمفید هستند و در نهایت به یک هدف مشخص برسد. از این جهت که درمورد یادگیری تقویتی هم هدف مشخصی از یادگیری وجود دارد، میتوان آن را شبیه یادگیری نظارتی دانست. اما وقتی که اهداف و پاداشها مشخص شدند، الگوریتم به صورت مستقل عمل میکند و نسبت به یادگیری نظارتی تصمیمات آزادانهتری میگیرد. به همین علت است که برخی یادگیری تقویتی را در دسته نیمه نظارتی جای میدهند. اما با توجه به آنچه گفته شد، منطقیتر این است که یادگیری تقویتی را به عنوان یک دسته جدا در یادگیری ماشین در نظر گرفت.
یادگیری تقویتی چگونه کار میکند؟
هدف یادگیری تقویتی این است که سعی کند با انجام عملیات مناسب در هر موقعیتی که در آن قرار میگیرد، میزان پاداش دریافتی را بیشینه کند. این روش را میتوان در نرمافزارها و ماشینهای مختلف پیادهسازی کرد تا به کمک آن بهترین مسیر یا رفتار در یک موقعیت خاص اتخاذ شود. در واقع در یادگیری تقویتی دیتاست آموزشی وجود ندارد، عامل براساس تجربههای خودش یاد میگیرد.
به عنوان مثال، مسالهای را در نظر بگیرید که در آن یک عامل، یک پاداش و تعدادی مانع در میان راه وجود دارد. عامل باید بهترین مسیر ممکن برای رسیدن به پاداش را پیدا کند.
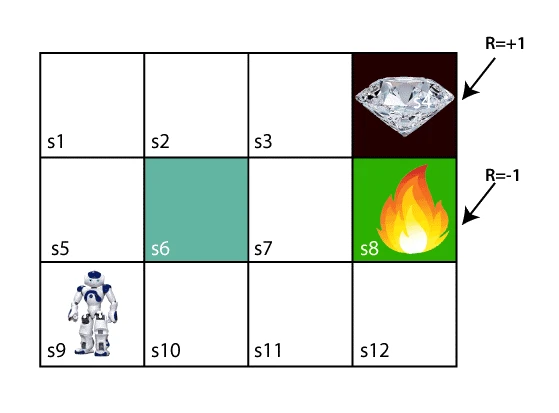
تصویر بالا یک ربات، الماس و چند آتش را نشان میدهد. هدف ربات این است که به الماس برسد و از آتشها اجتناب کند. در این تصویر هر سلول از s1 تا s12 نامگذاری شده است که هر کدام بیانگر یک حالت یا همان state است. همچنین R=1 به این معنی است که با رفتن به آن سلول یک واحد پاداش دریافت میشود و R=-1 به این معنی که با رفتن به آن سلول یک واحد از پاداش کم می شود. روش یادگیری ربات به این صورت است که تمام راههای ممکن را امتحان میکند، سپس راهی را انتخاب کند که با کمترین برخورد با موانع به الماس دست پیدا کند. هر قدم درستی که ربات بردارد، پاداش دریافت میکند و هر قدم اشتباه از پاداشش کم میکند. پاداش نهایی همان الماس است و هنگامی که ربات به الماس برسد، پاداش کل محاسبه میشود.
کاربردهای یادگیری تقویتی
در حال حاضر یادگیری تقویتی یکی از جالبترین مباحث در حوزه هوش مصنوعی به حساب میآید، اما میتوان گفت که هنوز استفاده آن در کاربردهای تجاری محدود مانده است و بیشتر مقالههایی که در این باره منتشر میشوند، جنبه تئوری دارند و تنها چند نمونه کاربردی عملی گزارش شده است.
برخی از کاربردهای عملی یادگیری تقویتی در ادامه آمده است. هرچند لازم است بدانیم کاربردهای یادگیری تقویتی به این موارد محدود نمیشود:
- بازی
- مدیریت منابع
- سیستمهای توصیهگر شخصیسازی شده
- رباتیک
- بازارهای مالی
بازی یکی از متداولترین کاربردهای یادگیری تقویتی است؛ چرا که میتواند عملکردی فرا انسانی در بازیهای زیادی از خودش نشان دهد. یکی مثال معروف از این بازیهای، بازی پکمن (Pac-Man) است. الگوریتم یادگیرنده بازی پکمن میتواند به چهار جهت حرکت کند؛ به غیر از مواردی که یک یا چند جهت توسط موانع مسدود شده باشد. براساس دادههای پیکسلی بازی، عامل میتواند برای هر یک واحد حرکت در مسیر این پاداشها را دریافت کند: ۰ برای فضای خالی، ۱ برای گویها، ۲ برای میوه، ۳ برای گویهای قدرتی، ۴ برای روحشدن، ۵ برای جمع کردن تمام گویها و به پایان رساندن مرحله، و یک ۵ امتیازی دیگری برای برخورد با یک روح از او کم میشود. عامل با بازی کردن به صورت تصادفی شروع میکند و بعد کمکم یاد میگیرد طوری بازی کند که به هدف نهایی، یعنی جمع کردن تمام گویها و به پایان رساندن مرحله نزدیک شود. بعد از مدتی، عامل حتی ممکن است تاکتیتکهایی مانند نگه داشتن گویهای قدرتی برای زمان مبادا و استفاده از آن برای دفاع از خود را یاد بگیرد.

یادگیری تقویتی را میتوان در هر موقعیتی که امکان تعریف یک پاداش مشخص وجود دارد، به کار برد. مثلا در مدیریت منابع سازمانی، الگوریتمهای یادگیری تقویتی میتوانند با این هدف به کار گرفته شوند که با استفاده از منابع محدود سعی کنند کارهای مختلف را به انجام برسانند؛ البته با در نظر گرفتن اینکه باید به هدف نهاییشان هم برسند. هدف نهایی در این شرایط صرفهجویی در زمان و مصرف منابع است.
در رباتیک هم یادگیری تقویتی توانسته در آزمونهای محدودی سربلند بیرون بیاید. این نوع از یادگیری ماشین میتوانند به رباتها کارهایی را یاد بدهد که یک انسان نمیتواند به راحتی آنها را نمایش و آموزش دهد. رباتها با این روش یاد میگیرند که بدون در اختیار داشتن فرمولاسیون خاصی، عملیات و کارهای جدید را یاد بگیرند.
در بازارهای مالی هم، از یادگیری تقویتی برای اجرای استراتژیهای معامله استفاده میشود.
از یادگیری تقویتی همچنین میتوان در حوزههایی مانند تحقیق در عملیات، تئوری اطلاعات، تئوری بازی، تئوری کنترل، بهینهسازی براساس شبیه سازی، سیستمهای چند عاملی، آمار و الگوریتمهای ژنتیک، بهره برد.
اصطلاحات مهم در یادگیری تقویتی
- عامل (Agent): عامل موجودی است که در محیط به اکتشاف و جستجو میپردازد تا با شناخت محیط بتواند متناسب با شرایط تصمیمگیری و عمل کند.
- محیط (Environment): شرایطی است که عامل در آن حضور دارد، یا توسط آن احاطه شده است. در یادگیری تقویتی، محیط تصادفی (stochastic) است. به این معنی که محیط به خودی خود، تصادفی است.
- عمل (Action): عمل، حرکتهایی است که توسط عامل در محیط انجام میشود.
- حالت (State): حالت، شرایطی است که بعد از هر عمل، از طرف محیط بازگردانده میشود.
- پاداش (Reward): بازخوردی است که از طرف محیط به عامل داده میشود تا عملی که انجام داده ارزیابی شود.
- سیاست (Policy): سیاست یک نوع استراتژی است که عامل براساس آن، از روی حالت فعلی محیط، عمل بعدیاش را انجام میدهد.
- ارزش (Value): میزان ارزش ایجاد شده در بلند مدت است و میتواند با پاداش کوتاه مدت متفاوت باشد. به این معنی که گاهی برخی از تصمیمها در کوتاهمدت پاداشی به همراه ندارند یا حتی پاداش منفی دارند، اما در جهت رسیدن به هدف نهایی مساله هستند.
معروفترین الگوریتمهای یادگیری تقویتی
الگوریتم Q-learning
در Q-learning، الگوریتم بدون سیاست عمل میکند و به اصطلاح یک الگوریتم یادگیری تقویتی off-policy نامیده میشود. این الگوریتم تابع ارزش را یاد میگیرد؛ به این معنی که انجام عمل a در حالت s چقدر نتایج مثبت دارد. روند کار در الگوریتم Q-learning شامل مراحل زیر میشود:
- جدول Q یا Q-table ایجاد میشود. در این جدول، تمام حالتها، تمام عملهای ممکن و پاداشهای مورد انتظار آمده است.
- یک عمل انتخاب میشود.
- عمل انتخاب شده، انجام میشود.
- پاداش محاسبه میشود.
- جدول Q-table به روز میشود.
هدف نهایی از این الگوریتم بیشینه کردن مقدار Q است.
الگوریتم SARSA (State-Action-Reward-State-Action)
الگوریتم SARSA، یک الگوریتم سیاست محور محسوب میشود. در این الگوریتمها، عملی که در هر حالت انجام میشود و خود یادگیری بر اساس سیاست مشخصی است. تفاوت عمدهای که الگوریتم SARSA با الگوریتم Q-learning دارد این است که برای محاسبه پاداش حالتهای بعدی، نیازی به داشتن تمام Q-table نیست.
الگوریتم Deep Q Neural Network
همانطور که از اسمش پیداست، همان Q-learning است که از شبکههای عصبی عمیق استفاده میکند. لزوم استفاده از شبکههای عصبی هنگامی است که با محیطهای بزرگ با تعداد حالتهای زیاد سروکار داریم؛ در چنین حالتی، به روز کردن Q-table کار آسانی نخواهد بود. به همین خاطر به جای تعریف مقادیر ارزش برای هر حالت، با استفاده از شبکه عصبی مقدار ارزش را برای هر عمل و حالت تخمین میزنیم.
چالشهای استفاده از یادگیری تقویتی
با وجود پتانسیلهای یادگیری تقویتی، پیادهسازی آن میتواند دشوار باشد و به همین علت کاربردهای آن هنوز محدود مانده است. یکی از موانع پیادهسازی این نوع یادگیری ماشین، لزوم و تکیه این روش برای جستجو و کشف در محیط مورد نظر است.
به عنوان مثال، اگر بخواهیم رباتی را آموزش دهیم که در یک محیط فیزیکی حرکت کند، هر چه جلو میرود، با حالتهای جدیدی مواجه میشود که در برابر آنها باید عملهای مختلفی را باید انجام دهد. در دنیای واقعی، کار آسانی نیست که به طور پیوسته، بهترین عملها انتخاب و انجام شوند؛ چرا که محیط پیوسته در حال تغییر است.
یکی دیگر از مشکلاتی که سر راه یادگیری تقویتی وجود دارد، مدت زمان و منابع محاسباتیای است که لازم است تا اطمینان حاصل کنیم یادگیری به درستی انجام شده است. از طرفی، هرچه محیط آموزرشی بزرگتر باشد به زمان و منابع بیشتری برای فرآیند آموزش الگوریتم نیاز است.
منابع:
https://towardsdatascience.com/reinforcement-learning-101-e24b50e1d292
https://searchenterpriseai.techtarget.com/definition/reinforcement-learning
https://www.geeksforgeeks.org/what-is-reinforcement-learning
https://www.techtarget.com/searchenterpriseai/definition/reinforcement-learning