
در این سری مقالات به سیستم های توصیه گر می پردازیم. با استفاده از لینک های زیر می توانید به بقیه ی بخش ها دسترسی داشته باشید:
- سیستم های توصیه گر
- سیستم های توصیه گر فیلتر محتوا محور (Content-based filtering - CB)
- سیستم های توصیه گر فیلتر مشارکتی (Collaborative filtering - CF)
- سیستم های توصیه گر مبتنی بر دانش (Knowledge-based)
- سیستم های توصیه گر هیبرید (Hybrid systems)
- TF-IDF
Term Frequency-Inverse Document Frequency (TF-IDF)
TF-IDF یک روش آماری است که قصد دارد میزان اهمیت کلمه در یک مستند را محاسبه کند. TF-IDF زیر مجموعه ی پردازش زبان طبیعی است و از آن برای استخراج ویژگی های مستندات متنی استفاده می شود. به طور کلی در این روش تعداد مرتبه هایی که کلمه استفاده شده است شمرده می شود و میزان اهمیت هر کلمه مشخص می شود.
Term frequency (TF)
این معیار از تقسیم تعداد استفاده ی کلمه بر جمع تعداد کلمه های مستند به دست می آید. این ترم در واقع میزان اهمیت کلمه در متن را نشان می دهد که با تقسیم بر تعداد کل کلمات نرمال سازی شده، محاسبه می شود.
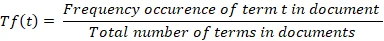
Inverse Document frequency (IDF)
این ترم از تقسیم تعداد مستندات شامل کلمه بر تعداد کل مستندات به دست می آید. در واقع این ترم میزان نادر بودن کلمه در مجموعه ی مستندات را نشان می دهد. زیرا ممکن است یک کلمه مثل «از» مرتبه ی زیادی در مستند استفاده شده باشد اما چون تقریبا در تمام مستندات وجود دارد پس ارزش آن کم است.
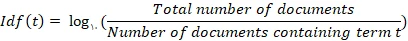
در نهایت TF-IDF از ضرب دو مقدار بالا محاسبه می شود. این روش به شدت به توضیح آیتم ها نیاز دارد. یا اینکه باید خود آیتم ها متنی باشند تا بتواند آن ها را تحلیل کند.
در این سری مقالات با سیستم های توصیه گر آشنا شدیم. اکنون این فرصت وجود دارد که برای پروژه های خودمان از آن ها استفاده کنیم و به درک عمیق تری از آن ها برسیم. امیدوارم این مقالات برای شما مفید بوده باشند و از خواندنشان لذت برده باشید.