
در این سری مقالات به سیستم های توصیه گر می پردازیم. با استفاده از لینک های زیر می توانید به بقیه ی بخش ها دسترسی داشته باشید:
- سیستم های توصیه گر
- سیستم های توصیه گر فیلتر محتوا محور (Content-based filtering - CB)
- سیستم های توصیه گر فیلتر مشارکتی (Collaborative filtering - CF)
- سیستم های توصیه گر مبتنی بر دانش (Knowledge-based)
- سیستم های توصیه گر هیبرید (Hybrid systems)
- TF-IDF
سیستم های توصیه گر فیلتر محتوا محور (Content-based filtering - CB)
در این روش فرض بر این است که کاربر محتواهایی را می پسندد که شبیه به محتواهایی است که قبلاً استفاده کرده است. در این روش از دو نوع داده استفاده می شود؛ سلیقه ی کاربر و توضیحات محتوا. این روش برای مواردی که اطلاعات مشخصی از آیتم ها و سابقه ی رفتاری آن ها با سیستم توصیه گر داریم اما اطلاعات شخصی از کاربر نداریم، مناسب است. برای مثال اگر محتواهای ما فیلم هستند، توضیحات آیتم ها می تواند شامل ژانر فیلم، بازیگران اصلی و سال اکران آن ها باشد یا حتی شرح مختصری از آن نیز می تواند به مجموعه اطلاعات آن اضافه شود. برای کابران نیز با توجه به سابقه ی آن ها در استفاده از توصیه گر یک پروفایل تشکیل می دهیم که شامل سلیقه های کاربر است و در صورت وجود اطلاعات شخصی کاربر همچون سن و موقعیت مکانی و شغل، آن ها را نیز در بر می گیرد. در واقع در این روش، ما به اطلاعات گسسته نیاز داریم و برای گسسته سازی اطلاعاتی مثل شرح یک فیلم از روش هایی مثل TF-IDF (Term Frequency-Inverse Document Frequency) می توان استفاده کرد که توضیحات مربوط به این روش در بخشی جدا آورده شده است. سیستم های توصیه گر محتوا محور می توانند دو روند را در پیش گیرند:
- فقط توضیحات محتوا و اطلاعات مربوط به آن را بررسی کنند.
- با توجه به سابقه ی کاربر پروفایل کاربر و آیتم را بسازد و از آن ها استفاده کند.
روش اول: بررسی توضیحات محتوا
در این روش سیستم توصیه گر میزان مشابهت تمام محتواها با یکدیگر را محاسبه می کند و سپس به کاربر محتوایی را پیشنهاد می دهد که بیشترین شباهت را به محتواهایی دارد که کاربر تا به الآن امتیاز بالایی به آن ها داده است یا آن ها را مشاهده کرده است. برای محاسبه ی میزان شباهت، ابتدا ویژگی های هر آیتم باید به صورت گسسته مشخص شود. این کار با روش هاش مختلفی می تواند انجام شود. ممکن است آیتم ها برچسب داشته باشند که در این صورت این اطلاعات گسسته اند. یا از توضیحات هر آیتم استفاده کنیم و با استفاده از روش هایی مثل TF-IDF ویژگی های هر آیتم و مقدار اهمیت آن را به دست آوریم. روش TF-IDF در قسمتی جدا توضیح داده شده است. در آخر هم میزان شباهت آیتم ها با هم با استفاده از روش هایی مثل تشابه کسینوسی (Cosine similarity)، فاصله ی اقلیدسی (Euclidean distance) و یا همبستگی پیرسون (Pearson’s correlation) محاسبه می شود.
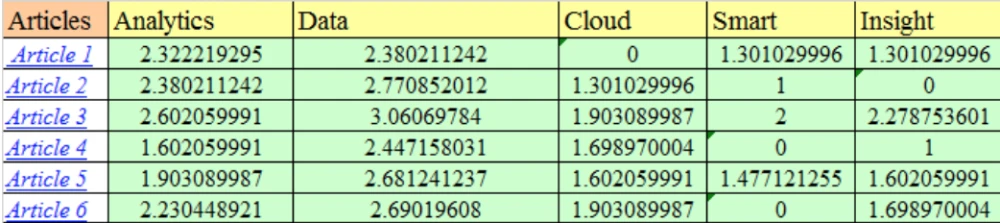
در شکل زیر ویژگی های مقالات به صورت میزان اهمیت هر کلمه در آن ها آورده شده است. این ویژگی ها با استفاده از روش TF-IDF به دست آمده است.
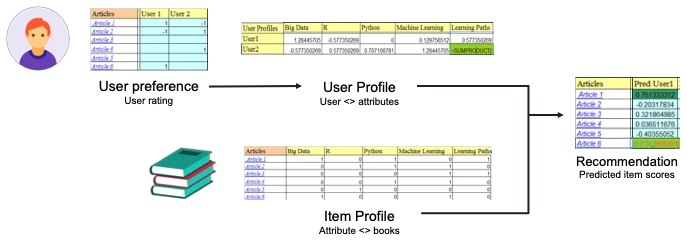
روش دوم: ساختن پروفایل کاربر و آیتم بر اساس آیتم هایی که کاربر تا کنون امتیاز دهی کرده است
در این روش مثل روش اول ویژگی های آیتم ها را مشخص می کنیم. اما صرفاً از تشابه آن ها به صورت خام استفاده نمی کنیم. در این روش بر اساس اینکه کاربر تا به حال به چه آیتم هایی علاقه داشته و چه آیتم هایی را نپسندیده است میزان اهمیت هر ویژگی برای او را بدست می آوریم و این اطلاعات پروفایل کاربر را تشکیل می دهند. حال با احتساب این داده ی جدید یعنی اهمیت هر ویژگی برای کاربر و اینکه هر آیتم آن ویژگی را دارد یا خیر می توان امتیازی که کاربر به آن آیتم می دهد را پیشبینی کرد و آیتم های با بیشترین امتیاز را به کاربر پیشنهاد داد.
مزایا
- در صورتی که آیتم ها توضیحات کافی داشته باشند، به مشکل شروع سرد (Cold start problem - این مشکل زمانی پیش می آید که سیستم توصیه گر اطلاعات مناسب برای ارائه ی پیشنهاد مناسب را ندارد. مثلا زمانی که یک کاربر جدید وارد سیستم می شود یا یک آیتم جدید اضافه می شود پروفایل آن تقریبا خالی است و توصیه گر نمی تواند درک درستی از سلیقه ی کاربر یا ویژگی های آیتم داشته باشد.) برای آیتم های جدید بر نمی خوریم.
- برای مشخص کردن ویژگی های آیتم ها محدودیت روش نداریم و می توان از روش هایی مثل پردازش زبان طبیعی (Natural language processing)، استفاده از اطلاعات دارای بار معنایی و ... استفاده کرد.
- به راحتی می توان توصیه ها را شرح داد و دلیل توصیه را به کاربر نشان داد. در واقع این روش بسیار شفاف است.
- کاربر اکثر اوقات پیشنهادها را می پسندد.
معایب
- این سیستم های توصیه گر تمایل به خصوصی سازی بیش از حد (Over-specialization problem) دارند و کاربر پیشنهادهای مختلفی دریافت نمی کند. این مشکل زمانی رخ می دهد که سیستم توصیه گر فقط پیشنهاد هایی محدود به زمینه ای خاص ارائه می کند و تنوع خود را از دست می دهد. این سیستم ها همیشه آیتم هایی را پیشنهاد می دهند که مشابه موارد استفاده شده در گذشته اند و همین موضوع امکان به وجود آوردن یک وضعیت حباب فیلتری (Filter bubble) برای کاربر را فراهم می آورد.
- بررسی محدود محتوا: ممکن است به هر دلیلی اطلاعات کافی از آیتم ها در دسترس نباشد که منجر به پایین آمدن دقت پیشنهادها می شود.
- کاربر جدید: در این روش مشکل شروع سرد برای کاربر جدید وجود دارد. از آنجا که کاربر سابقه ای از تعامل با سیستم توصیه گر نداشته است ممکن است توصیه ها به درستی ارائه نشوند و از کیفیت لازم برخوردار نباشند.
امیدوارم تا اینجا از این سری مقاله ها برای شما مفید بوده باشد و خسته نشده باشید. در بخش بعدی با سیستم های توصیه گر فیلتر مشارکتی بیشتر آشنا می شویم.
منابع
G. Adomavicius and A. Tuzhilin, "Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions," in IEEE Transactions on Knowledge and Data Engineering, vol. 17, no. 6, pp. 734-749, June 2005.
Isinkaye, F., Folajimi, Y. and Ojokoh, B., 2015. Recommendation systems: Principles, methods and evaluation. Egyptian Informatics Journal, 16(3), pp.261-273.
Abhigna, B.S. and Banda, M.L., Recommendation Systems: A Review of Applications.
https://www.ted.com/talks/eli_pariser_beware_online_filter_bubbles?language=en
https://en.wikipedia.org/wiki/Cold_start_(recommender_systems)
/https://www.bluepiit.com/blog/demystifying-hybrid-recommender-systems-and-their-use-cases
https://en.wikipedia.org/wiki/Item-item_collaborative_filtering
/https://www.bluepiit.com/blog/classifying-recommender-systems
https://en.wikipedia.org/wiki/Recommender_system
https://towardsdatascience.com/various-implementations-of-collaborative-filtering-100385c6dfe0
https://en.wikipedia.org/wiki/Collaborative_filtering
https://towardsdatascience.com/brief-on-recommender-systems-b86a1068a4dd
https://towardsdatascience.com/recommendation-systems-a-review-d4592b6caf4b