
در این سری مقالات به سیستم های توصیه گر می پردازیم. با استفاده از لینک های زیر می توانید به بقیه ی بخش ها دسترسی داشته باشید:
- سیستم های توصیه گر
- سیستم های توصیه گر فیلتر محتوا محور (Content-based filtering - CB)
- سیستم های توصیه گر فیلتر مشارکتی (Collaborative filtering - CF)
- سیستم های توصیه گر مبتنی بر دانش (Knowledge-based)
- سیستم های توصیه گر هیبرید (Hybrid systems)
- TF-IDF
سیستم های توصیه گر فیلتر مشارکتی (Collaborative filtering - CF)
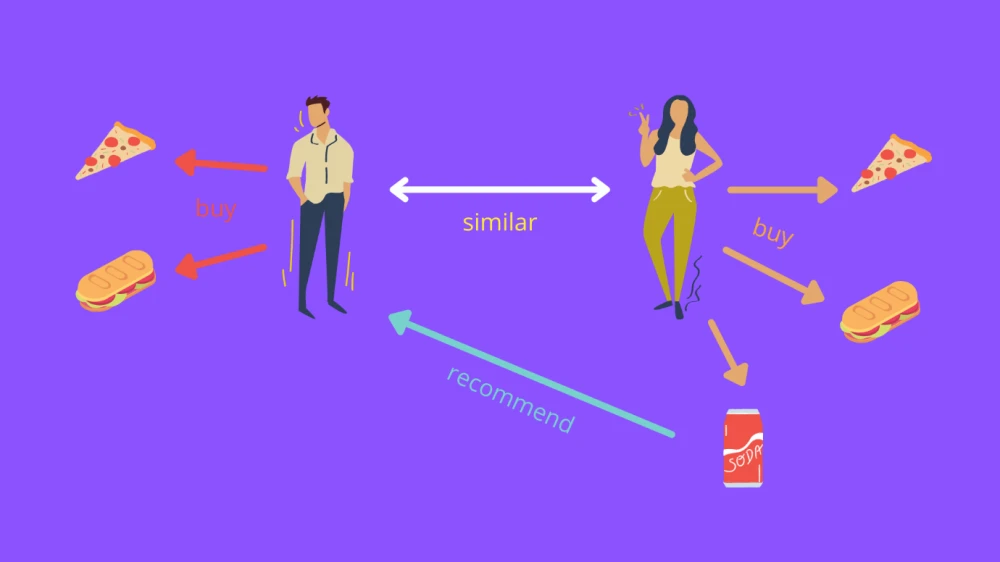
در مسائلی که ما اطلاعات خوبی از کاربر (مثل سن، جنسیت، شغل و ...) داریم اما در مورد آیتم ها دچار کمبود اطلاعات هستیم یا به دست آوردن ویژگی های آیتم ها دشوار است سیستم های توصیه گر فیلتر مشارکتی بسیار مناسب اند. دراین روش براساس شباهت رفتاری و عملکردی کاربرانی که در گذشته الگوی رفتاری مشابهی با کاربر فعلی داشته اند، پیشنهادها ارائه می شود. شاید تعریف آن کمی پیچیده باشد ولی به طور ساده روش فیلتر مشارکتی بر این فرض استوار است که کاربرانی که یک سری نظرهای مشابه درباره یک آیتم دارند، درباره آیتم های دیگر هم نظرهای مشابه دارند. فیلتر مشارکتی خود به دو دسته تقسیم می شود: مبتنی بر کاربر (User-based)، مبتنی بر آیتم (Item-based).
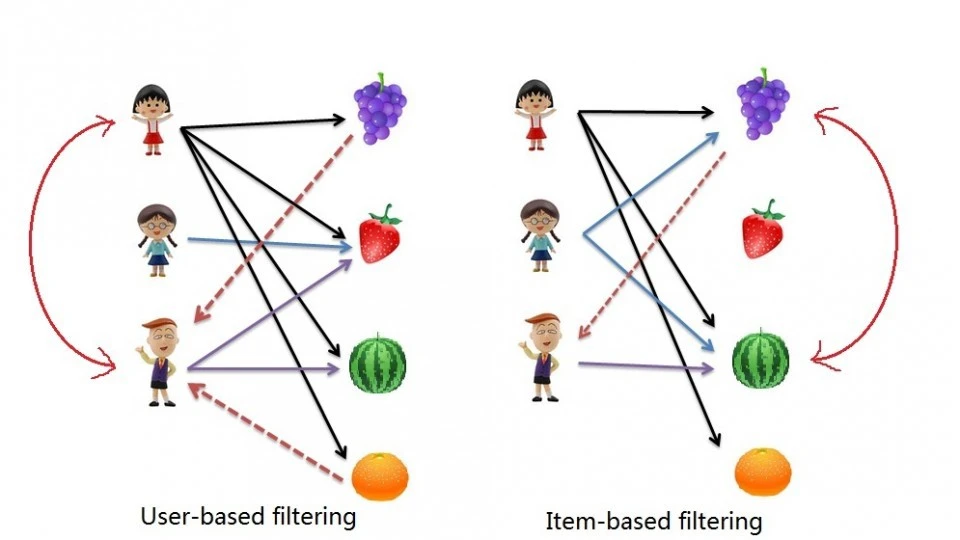
سیستم های توصیه گر فیلتر مشارکتی مبتنی بر کاربر
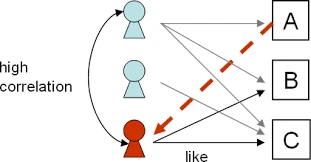
در این روش میزان شباهت سلیقه ی کاربران مشخص می شود و با توجه به آن، مقدار علاقه مندی کاربر به یک آیتم که تا به حال ندیده است مشخص می شود. در این سیستم از تشکیل بردار کاربر، که شامل تمام آیتم هایی است که کاربر امتیاز دهی کرده است به همراه امتیاز داده شده به آن ها، شروع می کنیم. سپس میزان تشابه کاربرها در یک ماتریس n*n که n تعداد کاربران است محاسبه می شود. برای محاسبه ی میزان تشابه می توان از تشابه کسینوسی استفاده کرد. حال ماتریس پیشنهادها می تواند تشکیل شود. امتیاز داده شده به آیتم ها در میزان شباهت کاربری که آن آیتم را امتیاز دهی کرده است با کاربر فعال ضرب می شود و به عنوان امتیاز پیشبینی شده در ماتریس پیشنهادها گذاشته می شود. این کار برای تمام آیتم هایی که کاربر ندیده است انجام می شود و سپس امتیاز ها مرتب می شوند و پیشنهادهای با بیشترین امتیاز، به کاربر هدف توصیه می شوند.
سیستم های توصیه گر فیلتر مشارکتی مبتنی بر آیتم

در این روش وقتی یک کاربر یک آیتم را می بیند، سیستم بررسی می کند که کاربرانی که قبلا این آیتم را دیده اند بعد از آن به سراغ چه آیتم های دیگری رفته اند. سپس سیستم آن آیتم ها را به کاربر پیشنهاد می دهد. مثلا در سایت دیجیکالا اگر یک گوشی بخرید بعد از آن، سیستم توصیه گر قاب گوشی و محافظ صفحه نمایش و چیزهایی مربوط به گوشی را توصیه می کند زیرا اکثر افرادی که آن گوشی را خریداری کرده اند بعد از آن، وسایل جانبی آن را خریده اند.
مزایا
- آیتم هایی می توانند به کاربر پیشنهاد شوند که شباهتی به آیتم هایی که کاربر قبلا مشاهده کرده است نداشته باشد. بنابراین این موضوع می تواند امکان گسترش را برای کسب و کارها فراهم کند.
- در صورتی که اطلاعات کافی از کاربر جدید داشته باشیم، مشکل شروع سرد برای او به وجود نمی آید و می توان به کاربر جدید متناسب با اطلاعاتی که از او داریم پیشنهادهای مناسبی بدهیم.
معایب
- برای آیتم های جدید مشکل شروع سرد وجود دارد زیرا سابقه ای از تعامل کاربران با آیتم وجود ندارد تا به بقیه پیشنهاد شود.
- برای آیتم هایی که کاربران کمی با آن ها تعامل داشته اند پراکندگی داده (Data sparsity problem) رخ می دهد که باعث می شود سیستم توصیه گر فیلتر مشارکتی نتواند توصیه های دقیقی ارائه کند. سیستم زمانی با این مشکل مواجه می شود که اطلاعات موجود ناکافی اند. برای مثال اگر از بین تمام آیتم های موجود در سیستم فقط تعداد محدودی توسط کاربران امتیازدهی شده باشند، آن وقت نمی توان از ارتباط میان رفتار کاربرها استفاده کرد و توصیه ای با کیفیت و همچنین فراگیر روی کل آیتم ها ارائه کرد.
- در سیستم های با تعداد کاربر و آیتم بالا گسترش این سیستم به دلیل هزینه ی بالای محاسباتی سخت است.
حافظه محور یا مدل محور
سیستم های فیلتر مشارکتی را بر اساس اینکه آیا صرفا از تاریخچه ی تعاملات استفاده می کنند و شباهت ها را می یابند و استفاده می کنند یا اینکه از این تعاملات یاد می گیرند و یک مدل از کاربر تشکیل می دهند و رفتار او را پیشبینی می کنند به دو دسته تقسیم می کنند. حافظه محور و مدل محور.
حافظه محور
در این سری سیستم ها با استفاده از گذشته ی کاربران یا آیتم ها، شباهت ها را به وسیله ی فاصله ی کسینوسی یا همبستگی پیرسون محاسبه می کنیم و از هیچ الگوریتم بهینه سازی یا یادگیری ماشین (Machine learning) پارامتری ای بهره نمی بریم. روش های غیرپارامتریک یادگیری ماشین همچون KNN در این دسته قرار می گیرند.
از آنجایی که در این روش، از بهینه سازی و یادگیری استفاده نمی شود پیاده سازی آن ساده است اما هنگامی که پراکندگی داده ها افزایش پیدا کند کارکرد سیستم کاهش پیدا می کند که از گسترش سیستم جلوگیری می کند.
مدل محور
در این سری روش ها با استفاده از یادگیری ماشین و پروفایل کاربر، سعی می شود تا امتیاز کاربر به آیتم هایی که تا به حال ندیده است پیشبینی شود. با توجه به رفتار کاربر سعی می شود سلیقه ی او مدل سازی شده و از آن استفاده شود. روش هایی از جمله شبکه های عصبی و یادگیری عمیق می توانند در اینجا مورد استفاده قرار گیرند. یکی از روش های پرکاربرد مدل محور، ماتریس عامل بندی (Matrix factorization) است. این روش به ما این امکان را می دهد که ویژگی های پنهانی که در بین فعل و انفعالات کاربران و آیتم ها وجود دارد را کشف کنیم. از این روش برای پیشبینی امتیازها در فیلترینگ همکارانه استفاده می کنند. برای مثال دو کاربر ممکن است به فیلم های خاصی امتیاز بالا بدهند و دلیل این کار ممکن است بخاطر بازیگر، کارگردان یا ژانر آن فیلم ها باشد. با تشخیص درست این ویژگی های پنهانی ما می توانیم امتیازها را بر اساس کاربر و آیتم های خاصی پیشبینی کنیم.
در سال ۲۰۰۷ شرکت Netflix یک مسابقه برای پژوهش روی سیستم های توصیه گر و با استفاده از مجموعه داده ای از این شرکت ترتیب داد. در سال ۲۰۰۹ جایزه یک میلیون دلاری به یکی از پژوهشگران رسید. یکی از الگوریتم هایی که آن ها در روش خود استفاده کرده بودند همین روش ماتریس عامل بندی بود و این نشانه قدرت این روش است.
امیدوارم تا اینجا از این سری مقاله ها برای شما مفید بوده باشد. در بخش بعدی سیستم های توصیه گر مبتنی بر دانش را معرفی می کنیم.
منابع
G. Adomavicius and A. Tuzhilin, "Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions," in IEEE Transactions on Knowledge and Data Engineering, vol. 17, no. 6, pp. 734-749, June 2005.
Isinkaye, F., Folajimi, Y. and Ojokoh, B., 2015. Recommendation systems: Principles, methods and evaluation. Egyptian Informatics Journal, 16(3), pp.261-273.
Abhigna, B.S. and Banda, M.L., Recommendation Systems: A Review of Applications.
https://www.ted.com/talks/eli_pariser_beware_online_filter_bubbles?language=en
https://en.wikipedia.org/wiki/Cold_start_(recommender_systems)
https://www.bluepiit.com/blog/demystifying-hybrid-recommender-systems-and-their-use-cases/
https://en.wikipedia.org/wiki/Item-item_collaborative_filtering
https://www.bluepiit.com/blog/classifying-recommender-systems/
https://en.wikipedia.org/wiki/Recommender_system
https://towardsdatascience.com/various-implementations-of-collaborative-filtering-100385c6dfe0
https://en.wikipedia.org/wiki/Collaborative_filtering
https://towardsdatascience.com/brief-on-recommender-systems-b86a1068a4dd
https://towardsdatascience.com/recommendation-systems-a-review-d4592b6caf4b