
Machine Learning به بیان ایدهای میپردازد که در آن یکسری الگوریتم به اصطلاح Generic (عمومی) با دریافت مجموعهای از دادهها، نتایج مورد انتظار را به عنوان خروجی ارائه میدهند. در مدلهای ML اصلاً نیازی نیست تا برای هر مسئلهٔ خاصی کدنویسی اختصاصی انجام شود؛ بلکه دولوپرها دیتا را در اختیار الگوریتم جنریک قرار داده و این خودِ الگوریتم است که با فرایندهای یادگیریاش، منطق موجود در دیتا را مییابد. در این آموزش، قصد داریم تا به صورت کلی مفهوم الگوریتمهای یادگیری ماشینی و انواع آن را با ذکر مثالی از دنیا واقعی شرح دهیم.
مفهومی کلی از ماشین لرنینگ (یادگیری ماشین)
پیش از این، با کلیت ماشین لرنینگ آشنا شدید و اگر علاقمند به کسب اطلاعات بیشتر در مورد ماهیت آن هستید، میتوانید به مقالهٔ یادگیری ماشینی چیست؟ مراجعه نمایید. حال اگر مجدد به بحث الگوریتمهای جنریک باز گردیم و بخواهیم بیشتر وارد جزئیات شویم، به عنوان مثال، میتوان الگوریتم Classification (طبقهبندی) را نام برد که با استفاده از این الگوریتم میتوان دیتا را به گروههای مختلف تقسیمبندی کرد.
برای مثال، یک الگوریتم Classification هم برای طبقهبندی به منظور تشخیص ارقام دستنویس مورد استفاده قرار میگیرد و هم میتوان آن را برای طبقهبندی ایمیلها به دو دستۀ اسپم (هرزنامه) و غیراسپم به کار برد و این در حالی است که حتی یک خط از سورسکد این الگوریتم جنریک نیاز به تغییر نخواهد داشت! بلکه خود الگوریتم منطق موجود در دیتای به اصطلاح Train (آموزشی) را یاد گرفته و بر اساس همان منطق نیز دادههای ورودی جدید را طبقهبندی میکند.
انواع الگوریتم های یادگیری ماشین
به طور کلی، الگوریتم های یادگیری ماشینی را میتوان در دو دستۀ یادگیری به روش اصطلاحاً Supervised (تحت نظارت) و یادگیری به روش Unsupervied (بدون نظارت) طبقهبندی کرد:
Supervised Learning (یادگیری تحت نظارت)
فرض کنید صاحب یک بنگاه املاک به دلیل توسعهٔ کسبوکارش، تصمیم به استخدام چند کارآموز میگیرد تا او را در انجام کارها کمک کنند و این در حالی است که صاحب بنگاه در یک نگاه میتواند قیمت خانه و ارزش آن را حدس بزند؛ اما کارآموزان به دلیل نداشتن تجربهٔ کافی، توانایی قیمتگذاری روی خانههای مختلف را ندارند. در همین راستا، بنگاهدار قصد تهیۀ اپلیکیشنی را برای کمک به کارآموزان خود دارا است به طوری که این اپلیکیشن قادر خواهد بود تا قیمت یک خانه را بر اساس معیارهایی همچون منطقه و محلهای که خانه در آن واقع شده است، قیمت سایر خانههای به فروش رفته در آن محله، اندازۀ خانه و غیره برآورد کند. بنابراین به منظور جمعآوری دیتا، بایستی برای مدتی مشخص اطلاعاتی همچون قیمت خانههای به فروش رفته در یک بازۀ زمانی خاص، محلۀ مربوط به آن خانه، اندازۀ خانه، تعداد اتاقخوابها و غیره را ثبت کرد.
حال این دیتا را تحت عنوان Training Data (دیتای آموزشی) به یک برنامه مبتنی بر هوش مصنوعی میدهیم تا ارزش یک خانۀ بناشده در یک منطقۀ خاص را برآورد کند که این نوع برآورد بر اساس الگوریتم یادگیری نظارتشده انجام میشود که در آن قیمت نهایی فروش هر خانه مشخص است. به عبارت دیگر، ورودی چنین الگوریتمهایی یکسری دیتای برچسبدار بوده و پاسخ مسئله مشخص است اما الگوریتم با بررسی پاسخها، منطق بهکاررفته در معادلۀ حل آن را نیز تشخیص داده و همان منطق را برای حل مسئله در مورد دادههای جدید به کار میگیرد.
در کل، برای ساخت چنین اپلیکیشنی بایستی Training Data در مورد هر خانه را به الگوریتم یادگیری ماشین وارد کرد و در ادامه الگوریتم سعی خواهد کرد تا معادلۀ ریاضی بهکاررفته برای به دست آمدن این اعداد را کشف کرده و آن را یاد بگیرد! در واقع، نحوۀ کار این الگوریتم مشابه این است که ما چند مورد تساوی ریاضیاتی داشته باشیم اما نمادهای محاسباتی آن پاک شده باشند. آیا با استفاده از این اعداد، میتوان معادلۀ ریاضی بهکاررفته در آنها را تشخیص داد؟ پاسخ آری است بدین صورت که بایستی یکسری کارها روی اعداد سمت چپ انجام شود تا بتوان پاسخهای سمت راست را دریافت کرد.
به طور کلی، در یادگیری نظارتشده، کشف ارتباط موجود در دیتای ورودی که منجر به یک خروجی شده است، توسط کامپیوتر انجام میشود و در صورتی که منطق بهکاررفته در Training Data برای حل این مجموعهٔ خاص از مسائل کشف شود، میتوان الگوریتم مد نظر را برای حل تمام مسائل مشابه از همان نوع نیز به کار گرفت.
Unsupervised Learning (یادگیری بدون نظارت)
حال شرایطی را در نظر بگیرید که قیمت خانههای به فروش رفته در یک منطقه را نمیدانیم و این در حالی است که سایر اطلاعات خانهها مانند اندازه، محلی که خانه در آنجا بنا شده و غیره را میدانیم؛ بنابراین در چنین شرایطی از الگوریتم یادگیری ماشین بدون نظارت برای آموزش مدل استفاده خواهیم کرد.
به طور خلاصه، یادگیری بدون نظارت به مانند این است که بخواهیم از میان لیستی از اعداد که معنا و مفهوم خاصی ندارند، الگویی خاص را استخراج کرده یا آنها را در گروههایی خاص طبقهبندی کنیم. حال چه الگویی را میتوان از چنین دیتایی استخراج کرد؟ با در نظر گرفتن دیتای مربوط به خانهها، آیا میتوان الگوریتمی را پیادهسازی کرد که به طور خودکار روی دیتای اولیه، طبقهبندیهای مختلف خانههای موجود در بازار را شناسایی کند؟
در پاسخ به سؤالاتی از این دست، فرض کنیم که میدانیم خریداران خانه در اطراف دانشگاهها غالباً خانههایی کوچک با تعداد اتاقخواب زیاد را میخرند، اما در حومۀ شهرها بیشتر خانههای سهخوابه با اندازۀ بزرگ به فروش میرسند؛ بنابراین با آگاهی از انواع مختلف مشتریان میتوان دیتا را به دستههای مختلف طبقهبندی کرد که این کار، فروشنده را در روند بازاریابی به منظور فروش خانهها کمک خواهد کرد. همچنین میتوان با بررسی کلی دیتای مربوط به خانهها، دیتای هر خانهای را که بسیار متفاوتتر از سایر آنها است شناسایی کرد و آن را کنار گذاشت چرا که این خانهها معمولاً عمارتهای مسکونی بزرگی هستند که بایستی آنها را برای یکسری مشتری خاص در نظر گرفت.
با در نظر گرفتن توضیحات فوقالذکر، ادامۀ این مقاله را با تمرکز بر الگوریتم یادگیری نظارتشده پیش خواهیم برد اما این انتخاب هرگز بدین معنا نیست که کار با الگوریتمهای یادگیری بدون نظارت مفید یا جالب نیستند؛ بلکه حقیقت امر آن است که استفاده از الگوریتمهای یادگیری بدون نظارت به دلیل عدم نیاز به برچسبگذاری دیتای آموزشی، پیادهسازی به مراتب راحتتری دارا است.
آیا قدرت تخمین قیمت خانه برای یک الگوریتم، یادگیری به شمار میآید؟
برای پاسخ به این سؤال، ابتدا مثالی میزنیم. مغز انسان توانایی روبهرو شدن با وضعیتهای متفاوتی را دارا است که از هر کدام از این موقعیتها چیزی را یاد میگیرد به طوری که میتواند بدون داشتن هیچ دستورالعمل صریحی، با موقعیتهای مذکور برخورد کند و به همین دلیل نیز صاحبان املاک پس از مدتی فروش خانههای متفاوت، به طور غریزی میتوانند قیمت درست یک خانه، بهترین راه برای فروش آن، نوع مشتری که علاقهمند به خرید است و غیره را تشخیص دهند و هدف از تحقیقات #هوش مصنوعی نیز تلاش برای تقویت چنین تواناییهایی در کامپیوترها است. اما الگوریتمهای یادگیری ماشینیِ فعلی هنوز آنقدر توانایی ندارند و برای یکسری مسائل محدود و خاص پاسخ درستی ارائه میدهند؛ بنابراین شاید تعریف بهتر برای واژۀ «یادگیری» در این مورد، گزارۀ «تعیین یک معادله برای حل یک مشکل خاص بر اساس چند دیتای فرضی» باشد.
برنامه برآورد قیمت خانه با استفاده از Multivariate Linear Regression
در پاسخ به این سؤال که چگونه میتوان برنامهای نوشت که توانایی برآورد ارزش یک خانه را داشته باشد، فرض کنیم چیزی از الگوریتم های یادگیری ماشین نمیدانیم؛ بنابراین با استفاده از یکسری قوانین پایهای، سعی میکنیم تا برنامهای برای برآورد قیمت یک خانه با زبان #پایتون بنویسیم:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# In my area, the average house costs $200 per sqft
price_per_sqft = 200
if neighborhood == "hipsterton":
# but some areas cost a bit more
price_per_sqft = 400
elif neighborhood == "skid row":
# and some areas cost less
price_per_sqft = 100
# start with a base price estimate based on how big the place is
price = price_per_sqft * sqft
# now adjust our estimate based on the number of bedrooms
if num_of_bedrooms == 0:
# Studio apartments are cheap
price = price-20000
else:
# places with more bedrooms are usually
# more valuable
price = price + (num_of_bedrooms * 1000)
return priceبا صرف زمان زیاد برای نوشتن و بهبود این کد شاید بتوان نتیجۀ دلخواه را برای پیشبینی قیمت چند خانه به دست آورد اما قطعاً چنین برنامهای کامل نخواهد بود و نگاهداری آن به دلیل تغییر مداوم قیمت خانهها، کاری بس دشوار است! در همین راستا، بهتر است که امکانی را به وجود آوریم تا به وسیلۀ آن خود ماشین توانایی تشخیص به منظور پیادهسازی فانکشنی متناسب با مسئله را داشته باشد و مادامی که فانکشن مد نظر نتیجۀ دلخواه ما را در خروجی ارائه دهد، چگونگی کارکرد آن اهمیتی نخواهد داشت:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = <computer, plz do some math for me>
return priceیکی از روشهای مناسب برای آنکه کامپیوتر توانایی تشخیص و پیادهسازی فانکشن پیشبینی را داشته باشد، این است که قیمت خانه را به عنوان فاکتوری در نظر بگیریم که برای پیشبینی آن، اِعمال سایر عناصری همچون تعداد اتاقخواب، مساحت خانه و محلۀ خانه ضروری است و همچنین بایستی دریابیم که هر یک از این عناصر به چه میزان در قیمت نهایی خانه تأثیرگذارند چرا که ممکن است نسبتی مشخص برای ترکیب این عناصر به منظور دستیابی به قیمت نهایی خانه وجود داشته باشد. در واقع، این کار موجب میشود تا بتوان فانکشن اصلی نوشتهشده در مورد قبل (با تعداد بیشمار شرطهای if و else موجود در آن) را به کدی ساده کاهش داد که عبارت است از:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * .841231951398213
# and a big pinch of that
price += sqft * 1231.1231231
# maybe a handful of this
price += neighborhood * 2.3242341421
# and finally, just a little extra salt for good measure
price += 201.23432095
return priceلازم به ذکر است که اعداد موجود در کد بالا همان نسبتهای ترکیب عناصر دخیل در قیمت خانه یا به عبارتی وزنهای مدل هستند و در صورتی که الگوریتم بتواند وزنهای مناسب برای آموزش الگوریتم را پیدا کند، مدل قادر خواهد بود تا قیمت خانهها را به درستی پیشبینی کند. در همین راستا یک راه ساده به منظور تشخیص بهترین وزنهای مدل را میتوان به شرح زیر عنوان کرد:
- گام اول: در این مرحله، تمام وزنها را عدد 1 میدهیم:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * 1.0
# and a big pinch of that
price += sqft * 1.0
# maybe a handful of this
price += neighborhood * 1.0
# and finally, just a little extra salt for good measure
price += 1.0
return price- گام دوم: در این مرحله، دیتای مربوط به خانههایی را که از قیمت آنها اطلاع داریم، به فانکشن میدهیم و نتیجه پیشبینی شده را با قیمت واقعی خانه مقایسه میکنیم تا ببینیم که فانکشن مد نظر تا چه اندازه خطا داشته و قیمتهای متفاوتی را به ازای هر خانه پیشبینی کرده است (برای مثال، اگر قیمت یک خانه 250،000 دلار باشد اما مدل قیمت آن را 178،000 دلار پیشبینی کرده باشد، در اینجا فانکشن مد نظر به میزان 72،000 دلار خطا کرده است.) در ادامه، مقدار خطای انجامشده به ازای هر خانۀ موجود در دیتاست را به توان 2 رسانده و با هم جمع میکنیم و اگر فرض کنیم که 500 خانه در دیتاست وجود داشته باشد، بنابراین مربع خطا به ازای تمام خانهها چیزی حدود 86،123،373 دلار خواهد بود و این نشاندهندۀ عملکرد اشتباه فانکشن در این الگوریتم است!
اکنون جمع مربعهای خطا را بر تعداد خانهها (عدد 500) تقسیم میکنیم تا میانگین مربعهای خطا به ازای هر خانه به دست آید؛ در واقع، این مقدار اصطلاحاً Cost (هزینه) فانکشن مد نظر خواهد بود و اگر بتوانیم پارامترهای وزن را طوری تغییر دهیم که مقدار این هزینه به صفر برسد، عملکرد فانکشن عالی خواهد بود؛ به عبارتی، این فانکشن قیمت خانه را در هر مورد و بر اساس دیتای ورودی به درستی حدس زده است (بنابراین هدف ما این است که با تغییر وزنها، هزینه را به کمترین مقدار ممکن کاهش دهیم.)
- گام سوم: مرحلۀ دو را با ترکیبی از وزنهای مختلف تکرار خواهیم کرد و آن ترکیبی را انتخاب میکنیم که موجب میشود تا مقدار هزینۀ فانکشن نزدیک به صفر شود که در این صورت مسئله حل خواهد شد.
به طور کلی، اگر بخواهیم خلاصهای از آنچه که انجام شد را بیان کنیم، بایستی بگوییم که در ابتدا یکسری دیتا را جمعآوری کردیم، آنها را طی سه گامِ بسیار ساده به الگوریتم جنریک خود دادیم و در نهایت فانکشنی را به دست آوردیم که توانایی پیشبینی قیمت تمام خانههای موجود در یک منطقه را دارا است. اما چند نکته در مورد این روش وجود دارد که در ادامه تکتک آنها را بیان میکنیم:
- تحقیقات در 40 سال گذشته در حوزههایی مانند زبانشناسی و ترجمه نشان داده است که الگوریتمهای یادگیری جنریکی که سازوکار آنها بر اساس امتحان کردن ترکیبهای مختلفی از اعداد است، در مواقعی که نیاز باشد تا یکسری قوانین مشخص ارائه شوند، عملکردی به مراتب بهتر از انسان ارائه خواهند کرد و حتی غیراصولیترین رویکردهای یادگیری ماشینی نیز عملکردی بهتر از یک انسان متخصص ارائه میدهند!
- فانکشنی که در نتیجۀ چنین رویکردی به دست میآید نیز کاملاً به اصطلاح Dumb (گنگ) بوده و حتی پارامترهایی نظیر مساحت خانه و تعداد اتاقخوابها را در پیشبینی قیمت اِعمال نکرده است و تنها قابلیت چنین فانکشنی این است که ترکیبهای متفاوتی از اعداد را به عنوان وزنهای مدل امتحان کند تا در نهایت به پاسخی صحیح دست یابد.
- در چنین فانکشنی به احتمال زیاد خود توسعهدهنده نیز نمیداند که چرا یک مجموعۀ خاص از وزنها نتیجۀ صحیح را ارائه میدهند و صرفاً فانکشنی نوشته شده است که نحوۀ کار آن مشخص نیست اما میتوان ثابت کرد که کار میکند!
حال فرض کنید که به جای استفاده از پارامترهایی مانند مساحت خانه و تعداد اتاقخوابهای آن، یکسری اعداد را به عنوان ورودی به فانکشن میدهیم و این اعداد نشاندهندۀ پیکسلهای یک تصویر است که توسط دوربین نصبشده در بالای یک خودرو گرفته شده است؛ بنابراین فانکشن مذکور بایستی در خروجی به جای پیشبینی «قیمت»، یک پیشبینی تحت عنوان «میزان زاویۀ چرخشی فرمان اتومبیل» را انجام دهد. در واقع، فانکشنی را پیادهسازی کردهایم که با استفاده از آن یک خودروی بدونراننده به تنهایی هدایت میشود (برای کسب اطلاعات بیشتر در این زمینه توصیه میکنیم به مقالۀ درآمدی بر فرآیند یادگیریِ رانندگی در خودروهای Self-Driving مراجعه کنید.)
اگر بخواهیم تمام ترکیبهای ممکن در گام سوم را امتحان کنیم تا به یک ترکیبی برسیم که بهترین نتیجه را ارائه میدهد، تقریباً امری غیرممکن است چرا که به معنای واقعی کلمه مدتزمان خیلی زیادی به طول خواهد انجامید و ریاضیدانان برای حل مسائلی از این دست، برخی روشهای هوشمندانه را برای تسریع در فرآیند پیدا کردن مقادیر قابلقبولی برای وزنها کشف کردهاند که با استفاده از چنین روشهایی دیگر نیاز نیست تا چندین ترکیب مختلف از وزنها را امتحان کنیم که در ادامه یکی از این روشها را تشریح میکنیم.
ابتدا یک معادلۀ ساده را مینویسیم که این معادله در واقع بیان ریاضیاتی تابع هزینۀ مطرح شده در گام دوم است:
Cost=∑i=1500 MyGuessi-RealAnsweri2500·2
حال دقیقاً همان معادله را با استفاده از یکسری به اصطلاح Jargon (اصطلاح) ریاضیاتیِ یادگیری ماشینی بازنویسی میکنیم که در این رابطه θ نشاندهندۀ وزنهای فعلی بهکاررفته در الگوریتم و (J (θ تابع هزینه به ازای آن ترکیب از وزنها است:
Jθ=12m∑i=1m(hθxi-yi)2
این معادله نشاندهندۀ میزان خطای فانکشنِ تخمین قیمت به ازای مجموعه وزنهایی است که برای مدل در نظر گرفته شده است. حال اگر بخواهیم نمودارِ معادلۀ هزینۀ فوق را به ازای تمام مقادیر ممکن از وزنها و با در نظر گرفتن معیارهای «تعداد اتاقخوابهای خانه و اندازۀ آن خانه» رسم کنیم، نموداری به شکل زیر حاصل خواهد شد که در آن محور عمودی مقدار Cost را نشان میدهد:
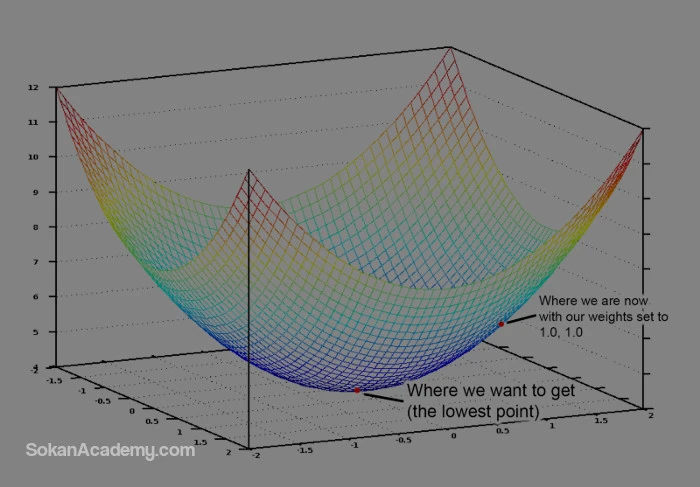
پایینترین نقطۀ آبیِ ممکن روی این نمودار جایی است که هزینه در آنجا کمترین مقدار را دارا است که اگر بخواهیم تابع هزینه را با مقدار وزنهای 1 محاسبه کنیم، میتوان از روی نمودار فوق حدس زد که تابع هزینۀ ما به مقدار اشتباه مینیممی دست یافته است و هرچه مقدار هزینۀ حاصل از حل معادلۀ فوق در نقاط بالاتری از نمودار قرار گیرد، این مسئله حاکی از آن است که فانکشن مد نظر خطای بیشتری داشته است و از همین روی بایستی وزنهایی را پیدا کنیم که مقدار فانکشن هزینه به ازای آنها در پایینترین نقطه از نمودار قرار گیرد و تنها در این صورت است که به پاسخ صحیح دست یافتهایم. بنابراین بایستی وزنهای مدل را به گونهای تنظیم کرد تا در نمودار فوق به سمت پایینترین نقطه حرکت کنیم و اگر تغییر در وزنها موجب حرکت پیوستۀ تابع هزینه به سمت پایینِ نمودار شد، در این صورت دستیابی به مقدار مینیمم صحیح برای تابع هزینه نیاز به امتحان کردن ترکیب وزنهای متفاوت زیادی نخواهد داشت و امکان رسیدن به آن ترکیب با چند تغییر کوچک در وزنها وجود دارد.
اگر در رشتهٔ ریاضی درس خوانده باشید، احتمالاً از درس حساب، دیفرانسیل و انتگرال به خاطر دارید که اگر از یک تابع مشتق بگیریم، میتوان شیب نمودار آن تابع را در نقاط دلخواه به دست آورد؛ به عبارت دیگر، با استفاده از مشتق یک تابع میتوان مشخص کرد که از هر نقطۀ نمودار چگونه میتوان به پایینترین نقطه از آن دست یافت! حال اگر مقدار مشتق جزئی فانکشن هزینه را به ازای هر یک از وزنهای مدل محاسبه کنیم و نتیجه را از هر کدام از وزنها کم کنیم، این کار موجب میشود تا فانکشن مد نظر یک گام به مقدار مینیمم خود (پایینِ نمودار) نزدیک شود و میتوانیم این پروسه را ادامه میدهیم تا در نهایت مقدار مینیمم فانکشن و همچنین بهترین ترکیب از وزنها را برای مدل خود به دست آوریم.
روش فوق خلاصهای بود از چیزی تحت عنوان Batch Gradient Descent که به منظور پیدا کردن بهترین ترکیب از وزنهای فانکشن به کار گرفته میشود (لازم به ذکر است که در صورت استفاده از لایبرریهای یادگیری ماشین برای حل مسائل واقعی، تمام کارهای ذکرشده توسط این لایبرریها انجام میشود اما توضیح آنها خالی از لطف نبوده و تا حدودی با سازوکار پشت پردۀ آنها نیز آشنا شدیم.)
آشنایی با سایر توابع به کار گرفته شده در فرآیندهای ماشین لرنینگ
الگوریتم سهمرحلهای که پیشتر توضیح دادیم، در واقع الگوریتمی است تحت عنوان Multivariate Linear Regression (رگرسیون خطی چندمتغیره) که با استفاده از آن معادلهای خطی را برآورد کرده و آن را روی تمام دیتای خانههای موجود اصطلاحاً فیت (تنظیم) کرده و معادله را آموزش دادهایم. سپس از این معادله برای حدس زدن قیمت فروش خانههای جدید (که در دیتای آموزشی موجود نیستند) استفاده کردهایم؛ بنابراین چنین ایدهای واقعاً کاربردی بوده و میتوان مسائل واقعی را با استفاده از آنها حل کرد.
با این حال، چنین رویکردی ممکن است برای حل برخی مسائل ساده کاربرد داشته باشد و قدرت حل مسائل پیچیده را نداشته باشد. برای مثال، حدس زدن قیمت خانهها همیشه آنقدر ساده نیست چرا که پیشبینی قیمت یک خانه به چندین پارامتر دیگر نیز وابسته است که در این صورت نمیتوان مسئله را با استفاده از یک معادلۀ خطی ساده حل کرد.
اما خوشبختانه روشهای زیادی برای حل مسائل پیچیده وجود دارد و الگوریتمهای ماشین لرنینگ بسیاری مانند Neural Networks و SVM وجود دارند که با استفاده از آنها میتوان دیتای غیرخطی را نیز هَندل کرد. علاوه بر این، روشهای هوشمندانهتری برای استفاده از الگوریتمهای رگرسیون خطی نیز وجود دارد که در آن امکان به اصطلاح فیت شدن جنبههای به مراتب بیشتری در الگوریتم وجود دارد که در این صورت میتوان پارامترهای بیشتری از مسئله را در الگوریتم اِعمال کرده و در نتیجه به پاسخی بهتری نیز دست یابیم. اما با این حال، در همهٔ الگوریتمها نکتۀ کلیدی پیدا کردن بهترین ترکیب از وزنها برای دستیابی به پاسخ دلخواه است.
در فرآیندهای ماشین لرنینگ بیان شده در این مقاله به مفهومی تحت عنوان Overfitting اشاره نکردیم؛ مفهومی که بیانگر این ایده است که اکثر الگوریتمهای یادگیری ماشینی روی دیتای آموزشی فیت شده و فقط برای این دیتا پاسخ دقیق و درست را ارائه میدهند و در ارائۀ پاسخ برای دیتایی به غیر از آنها، دچار مشکل شده و دقتی پایینتر را در خروجی خواهند داشت! اساساً برای مقابله با Overfitting در مدلهای یادگیری ماشینی، روشهایی همچون Regularization و همچنین استفاده از دیتاستهای به اصطلاح Cross-Validation در نظر گرفته میشود که خود این مسئله موضوع گستردهٔ دیگری است.
سخن پایانی
مفهوم اصلی مدلهای ماشین لرنینگ بسیار ساده است اما اساساً کار با آنها و دستیابی به نتایج مفید، نیازمند مهارت و تجربه است؛ مهارتی که هر دولوپری میتواند آن را یاد بگیرد. همانطور که دیدیم، تکنیکهای یادگیری ماشینی قدرت حل بسیاری از مسائل که به نظر واقعاً سخت میآیند را دارا هستند (مانند تشخیص ارقام دستنویس) و همچنین این الگوریتمها برای ارائۀ یک پاسخ مناسب در خروجی بایستی دیتای مناسبی را در ورودی دریافت کنند. برای مثال، اگر مدلی برای پیشبینی قیمت یک خانه داشته باشیم و بخواهیم این مدل را بر اساس دیتایی مانند «نوع گلهای داخل هر خانه» پیشبینی کند، هرگز پاسخی در خروجی نخواهیم داشت چرا که هیچ رابطهای بین گلهای یک خانه و قیمت فروش آن وجود ندارد و از همین روی هرچقدر هم این مدل تلاش کند، هرگز نمیتواند بین دیتای ورودی و خروجی مد نظر ارتباط معناداری ایجاد کرده و مسئلهای را حل کند. در یک کلام، تنها روابطی را میتوان مدلسازی کرد که واقعاً وجود داشته باشند.
پس به خاطر داشته باشیم که وقتی یک انسان نمیتواند رابطهای بین دیتای ورودی و خروجی مورد انتظار برقرار کند، در مدلهای ماشین لرنینگ نیز چنین کاری میسر نخواهد بود و بایستی روی مسائلی تمرکز کنیم که یک انسان توانایی حل آنها را دارا باشد که مسلماً حل آنها توسط کامپیوتر نیز با سرعت و دقت بیشتری انجام میشود.
در پایان برای آشنایی بیشتر با مقولۀ ماشین لرنینگ، دورهٔ آموزش رایگان یادگیری ماشینی در کورساِرا را به شما پیشنهاد میکنیم و همچنین میتوانید پکیج SciKit-Learn را به منظور آشنایی بیشتر با قابلیتهای صدها الگوریتم یادگیری ماشینی در پایتون، دانلود و نصب کنید.