داده همه جا هست و هر روز هم در حال رشد است. پس تعجبی ندارد که رشتهای به اسم مهندسی داده به وجود آید؛ رشتهای که به طور مستقیم روی انتقال، تبدیل و ذخیره داده تمرکز دارد. از این گذشته، در سالهای اخیر نیاز کسبوکارهای زیادی به مهندس داده بیشتر و بیشتر شده است و این رشته را به شغلی با نیازمندی بالا و درآمد بالا تبدیل کرده است.
معنای مهندسی داده را بیشتر میتوان در بخش «مهندسی» آن یافت؛ وظیفه مهندسها طراحی و ساختن است. مهندسان داده هم روندهایی (pipeline) طراحی میکنند که دادهها به نوعی ذخیره، تبدیل و منتقل شوند که وقتی به دست دانشمندان داده میرسند، کاملا آماده و کاربردی باشند. دادهها از منابع مختلفی جمع میشوند و در یک انبارداده ذخیره میشوند که به عنوان یک منبع داده قابل اتکا مورد استفاده قرار بگیرد.
اما نکتهی قابل توجه این است که با توجه به عمر نه چندان طولانی مشاغل مرتبط با داده نسبت به سایر مهندسیها، ممکن است وظایف و لیست مهارتهای مورد نیاز برای مهندس های داده، مبهم باشد. در این مطلب به طور مفصل با مهندسی داده آشنا میشویم و پس از آن، هرکس آسانتر میتواد تصمیم بگیرد آیا میخواهد مهندس داده بشود یا خیر؟
هدف از مهندسی داده چیست؟
در طول دهه گذشته، بسیاری از شرکتها به یک تحول دیجیتال قدم گذاشتهاند. به این معنی که در حال تولید حجمهای غیرقابلباوری از انواع مختلف داده هستند؛ دادههایی پیچیدهتر از همیشه که با سرعت تولید میشوند. دانشمند داده باید بتواند از تمام داده ها سردر بیاورد و آنها را ساماندهی کنید. اما در کنار دانشمنده داده به شخصی نیاز است که نسبت به کیفیت، امنیت و کاربردی بودن داده ها اطمینان حاصل کند و آنها را برای پیدا کردن الگوها و تحلیل آماده کند.
در روزهای آغازین پیدایش Big data، ساختن زیر ساخت و pipeline برعهدهی دانشمند داده بود. اما چون این مهارت جزو مهارتهای ضروری برای دانشمند داده نبود، مدلکردن داده به خوبی انجام نمیشد و این موضوع به دوبارهکاری و ناپایدار بودن داده منجر میشد. در نتیجه شرکتها نمیتوانست از ارزشمندی دادههایشان به خوبی بهرهمند شوند و پروژههای دادهمحورشان را به خوبی پیش ببرند. اما این روزها با حجم زیاد داده ناشی از تحولات دیجیتال، اینترنت اشیا و رقابت بر سر دادهمحور شدن، کاملا واضح است که شرکتها به مهندس داده نیاز دارند تا بتوانند زیربنای موفقیت پروژههای داده و کارهای دانشمندان داده را بنا بگذارند.
گفتیم که مهندس داده روی ساختن پایپلاین برای داده کار میکند. در ادامه نمونهای از این پایپلاینها را مشاهده میکنید.
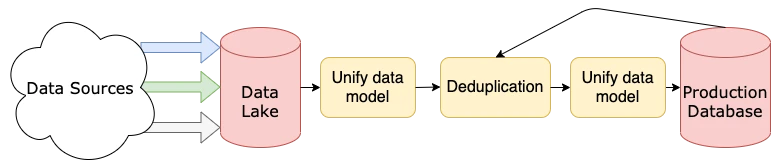
در تصویر بالا نمونهی ساده شدهای از pipeline داده را میبینید. در این pipeline، داده از منابع مختلف میآید، وارد دریاچه داده میشود، مدلداده یکپارچه ایجاد میشود، دادههای تکراری حذف میشوند، یک بار دیگر مدلداده یکپارچه ایجاد میشود و در آخر وارد پایگاه داده محصول میشود.
داده میتواند از منابع مختلفی آمده باشد:
- ابزارهای اینترنت اشیا
- تلهمتری خودروها (telemetry)
- دادههای مربوط به املاک
- فعالیت کاربران در یک اپلیکیشن وب
- هر ابزار اندازهگیری دیگری که فکرش را کنید
براساس ماهیت این منابع، دادههای ورودی در جریانهای بلادرنگ (real-time stream) یا در دستههای یکسانی پردازش میشوند.
مهندس داده چه وظایفی برعهده دارد؟
مسئولیت اصلی مهندس داده به طور خلاصه این است که به نیازهای دادهای مشتری پاسخ دهد. اما چندین رویکرد برای انجام این کار وجود دارد که در ادامه با آنها آشنا میشویم.
جریان داده (Data Flow)
برای انجام هر کاری با داده در یک سیستم، باید اول اطمینان حاصل کنیم که داده، به طور قابل اعتمادی به سیستم وارد میشود و حرکت میکند. ورودیها میتوانند هرچیزی، از جمله دادههای JSON یا XML، آپدیتهایی به صورت ویدئو، تصورهای برچسبدار، دادههای مربوط به آزمایشهای پزشکی، یا سنسورهای دما باشند.
مهندس داده مسئولیت دارد، سیستمی طراحی کند که این دادهها به عنوان ورودی از منابع مختلف وارد شوند، تغییرات لازم روی آنها انجام شود و سپس ذخیره شوند. به چنین سیستمی معمولا پایپلاین ETL میگویند که مخفف استخراج (Extract)، تبدیل(Transform) و بارگذاری (Load) است.
جریان داده معمولا در همان بخش اول، یعنی مرحله استخراج اتفاق میافتد. اما کار مهندس داده فقط این نیست که داده را وارد پایپلاین کند. بلکه لازم است اطمینان پیدا کند که پایپلاین به اندازه کافی پایدار است که در مواجه با دیتاهای ناهنجار، هنگام آفلاین شدن منابع و باگهای بحرانی، همچنان سرپا میماند. زمان به کار (Uptime) بسیار مهم است، به خصوص وقتی که با داده حساس به زمان سروکار داشته باشید.
نرمالسازی داده و مدلسازی
بعد از به راه افتادن جریان داده، نیاز است که داده به یک معماری استاندارد تغییر کند. نرمالسازی داده شامل تسکهایی میشود که داده را برای کاربران قابل استفادهتر میکند. این تسکها معمولا شامل موارد زیر میشوند:
- حذف دادههای تکرای (deduplication)
- حل مشکلات دادههای متناقض
- تبدیل کردن داده به یک مدل دادهای مشخص
این فرآیندهای میتوانند در مراحل مختلفی اتفاق بیفتند. به عنوان مثال، فرض کنید در یک شرکت بزرگ کار میکنید که تیمهای هوش تجاری و دیتاساینس هم وجود دارد و هر کدام از این دو تیم روی دادههایی که از سمت شما میآید حساب میکنند. پس احتمالا باید دادههای غیرساختاریافته را در یک دریاچه داده (data lake) ذخیره کنید تا توسط تیم دیتاساینس برای انجام تحلیل داده مورد استفاده قرار گیرد. همچنین ممکن است لازم باشد داده نرمالشده را در یک پایگاهداده رابطهای یا یک انبار داده (data warehouse) ذخیره کنید تا توسط تیم هوش تجاری مورد استفاده قرار بگیرد یا داده به کاربر نهایی در یک اپلیکیشن نمایش داده شود. تصویر زیر شمایی از این مثال را نشان میدهد:
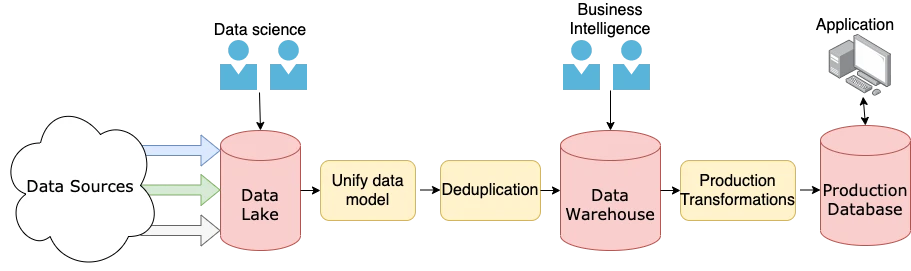
نرمالسازی داده و مدلکردن معمولا بخش تبدیل در ETL هستند، اما تنها عملیاتی نیستند که در این بخش استفاده میشوند. یک مرحله متداول دیگر در این مرحله، پاکسازی داده است.
پاکسازی داده (Data Cleaning)
پاکسازی داده و نرمالسازی داده ارتباط تنگاتنگی باهم دارند. حتی برخی نرمالسازی را زیرمجموعه پاکسازی میدانند. اما نرمالسازی داده بیشتر روی تبدیل دادههای مجزا به یک مدلداده تمرکز دارد، درحالیکه پاکسازی داده شامل عملیاتی است که داده را کاملتر و یکنواختتر میکند، از جمله:
- تبدیل دادههای یکسان به یک نوع واحد (مثلا، تبدیل به عدد صحیح (integer) در صورت نیاز)
- اطمینان از اینکه تمام دادهها فرمت یکسان دارند
- پر کردن مقادیر ناقص (missing value) در صورت امکان
- بردن مقادیر یک ویژگی به یک بازه مشخص
- حذف داده خراب و غیرقابل استفاده
کاری که روی داده انجام میشود تا تمیز شود، به شدت به نوع ورودی، مدلداده و خروجیهای مدنظر بستگی دارد. هرچند ممکن است مسئولیت پاکسازی داده در سطوح مختلف بر عهده تیمهای مختلف باشد، اما مهندس داده باید سعی کند تا حد ممکن روشی اتوماتیک برای پاکسازی داده ایجاد کند، داده ورودی و ذخیره شده را مدام بررسی کند.
مهارتهای مورد نیاز مهندس داده
اکثر مهارتهای مهندس داده، همان مهارتهایی است که یک مهندس نرمافزار هم به آنها نیاز دارد. اما چند حوزه هم وجود دارد که مهندسان داده باید به طور خاص روی آنها تمرکز کنند. در ادامه به مهارتهایی میپردازیم که مهندس داده برای موفقیت شغلی به آنها نیاز دارد.
مهارتهای برنامه نویسی کلی
مهندسی داده، یک تخصص در مهندسی نرمافزار به حساب میآید، پس داشتن مهارتهای مهندسی نرمافزار در صدر لیست مهارتهای آن قرار میگیرد. مهندس داده باید درک مناسبی از مفاهیم طراحی مانند DRY، برنامهنویسی شیگرا، ساختار دادهها و الگوریتمها داشته باشد.
مانند هر حوزه تخصصی دیگری، چند زبان برنامهنویسی، برای مهندسان داده محبوبتر هستند. از جمله آنها می توان پایتون، اسکالا و جاوا را نام برد. اما چرا این زبانها محبوب هستند؟
پایتون یکی از زبانهای برنامهنویسی است که میتوان گفت به طور گسترده همه جا حضور دارد. پایتون از جنبههای مختلف، بین سه زبان محبوب دنیا قرار دارد. این زبان به طور گسترده توسط تیمهای هوش مصنوعی و یادگیری ماشین استفاده میشود. تیمهایی که به طور نزدیک با یکدیگر کار میکنند لازم است برای برقراری ارتباط، به یک زبان مشترک برسند و پایتون یک زبان میانجی در این حوزه است.
یکی دیگر از دلایل محبوبیت پایتون، کاربرد آن در ابزارهایی orchestration مانند Apachi Airflow و وجود کتابخانههای محبوبی مانند آپاچی اسپارک است.
اسکالا هم به نوعی محبوب است، و مانند پایتون دلیلش، محبوبیت ابزارهایی است که از آن استفاده میکنند، مانند آپاچی اسپارک. اسکالا روی ماشین مجازی جاوا (JVM) اجرا میشود و این امکان را ایجاد میکند که به طور یکپارچه با جاوا مورد استفاده قرار بگیرد.
جاوا برای مهندسی داده چندان محبوب نیست، اما همچنان در تعدادی از شرح شغلیها مشاهده میشود. بخش از این موضوع به خاطر استفاده گسترده از جاوا در stack نرمافزارهای سازمانی است و بخشی هم به خاطر قابلیت سازگاری آن با اسکالا است.
تکنولوژیهای پایگاهداده
اگر قرار باشد همیشه در حال انتقال و جابهجایی دادهها باشید، پس با پایگاه داده هم سروکار خواهید داشت و لازم است تسلط خوبی روی یک یا چند پایگاه داده داشت باشید.
در یک دستهبندی کلی، پایگاه دادهها را میتوان به دو دسته SQL و NoSQL تقسیم کرد.
از پایگاه داده SQL معمولا برای مدلکردن دادههایی مانند داده سفارشهای مشتری، استفاده میشوند که با استفاده از رابطهها تعریف شدهاند.
پایگاه دادههای غیر رابطهای، سایر پایگاه دادهها هستند که از مدل رابطهای تبعیت نمیکنند. از جمله:
- ذخیره به صورت کلید-مقدار (key-value) مانند ردیس (Redis)
- ذخیره متنمحور مانند MongoDB (مونگو دیبی) یا Elasticsearch (الاستیک سرچ)
- پایگاه داده گرافی مانند Neo4j
- و سایر پایگاه دادهها که کمتر شناختهشده هستند.
هرچند نیاز نیست زیر و بم تمام این دیتابیسها را یاد بگیرید، اما لازم است مزایا و معایب آنها را بدانید و در صورت نیاز بتوانید به سرعت، کار کردن با آنها را یاد بگیرید.
سیستمهایی که مهندسان داده با آنها کار میکنند، با سرعت زیادی در حال انتقال به سیستمهای ابری هستند، و پایپلاینهای داده معمولا روی چندین سرور یا خوشه مختلف پخش شدهاند. پس مهندس داده لازم است درک خوبی از سیستمهای توزیعشده و مهندسی ابری هم داشته باشد.
سیتسمهای توزیعشده و مهندسی ابری
یکی از الگوهای رایج در ETL، راهاندازی یک pipeline روی سرورهای جداگانه استکه توسط یک صف پیغام مانند RabbitMQ یا آپاچی کافکا هدایت میشوند.
ضروری است که نحوه طراحی این سیستمها را بدانید و با مزایا و ریسکهایشان آشنا باشید و بدانید چه زمانی باید از آنها استفاده کنید.
تامینکننده سرویسهای ابری از جمله، وبسرویسهای آمازون، Google Cloud و Microsoft Azure از ابزارهای محبوبی هستند که برای ساختن و پیادهسازی سیستمهای توزیعشده از آنها استفاده میشود.
چطور مهندس داده شویم؟
هیچ راه شفاف و مشخصی برای تبدیل شدن به مهندس داده وجود ندارد. بلکه اکثر مهندسان داده مهارتهای موردنیازشان را در حین کار گسترش میدهند، و برخی از مهارتها را در دورههای آموزشی، دانشگاهها و به صورت پروژه محور یاد میگیرند.
۱. مدرک دانشگاهی
برای مهندس داده شدن، معمولا نیازی به مدرک دانشگاهی ندارید. هرچند داشتن مدرک مناسب به شما کمک خواهد کرد؛ به عنوان مثال، لیسانس مهندسی نرمافزار، علوم کامپیوتر یا ریاضی کاربردی مناسب هستند. برای تحصیلات تکمیلی هم مهندسی نرمافزار یا علوم کامپیوتر مناسب خواهد بود. این مدارک به شما کمک میکند که در میان داوطلبان شغلهای مهندسی داده، جلوتر باشید؛ به خصوص اگر سابقه کاری نداشته باشید.
۲. دورههای آنلاین رایگان و ارزان
برخی از بهترین مهندسان داده، به صورت خودآموز و از طریق دورههای رایگان مسیر یادگیریشان را طی کردهاند. شاید باورش سخت باشد، اما بیشتر چیزی که باید بدانید را از ویدئوهای یوتیوب میتوانید یاد بگیرید. همچنین دورههای Coursera، Edx، Udemy، Udacity میتوانند در مسیر یادگیری بسیار مفید واقع شوند. کتابهای الکترونیک oreilly هم معتبر و راهگشا هستند.
۳. یادگیری پروژه محور
گاهی به اتمام رساندن دورههای آنلاین کار چندان آسانی نیست و ممکن است در میانه راه با از دست دادن انگیزه مواجه شویم. میتوانید یک پروژه که به آن علاقمند هستید را انتخاب کنید و برای انجام آن مهارتهای لازم را کسب کنید. با نوشتن گزارش و منتشر کردن آن در قالب یک پست بلاگ یا مطلب لینکدین، همچنین قرار دادن پروژههایتان در گیتهاب، علاوه بر انگیزه بیشتر، به اعتبار شما هم کمک خواهد شد.
نتیجهگیری
همانطور که گفته شد مهندسی داده یکی از شغلهایی است که نیازمندی به آن در بازار کار زیاد است. اگر فکر میکنید، مهارتهای گفته شده و شرح شغلی عنوان شده، مورد علاقه شماست، منابع زیادی وجود دارد که میتوانید با یادگیری آنها قدم در این راه بگذارید. همچنین اگر در این راه تجربهای دارید، به اشتراک گذاشتن آن به دوستان علاقمند این حوزه کمک زیادی خواهد کرد.