
شبکه عصبی بازگشتی (Recurrent neural network) یا به اختصار RNN، یکی از جدیدترین الگوریتمها برای دادههای متوالی (sequential) به حساب میآید که در دستیار صوتی سیری اپل و جستجوی صوتی گوگل هم مورد استفاده قرار گرفته است. الگوریتم RNN، اولین الگوریتمی است که به کمک حافظهی داخلی، ورودیهایش را ذخیره میکند. و همین موضوع است که آن را برای دادههای متوالی مناسب میکند. شبکه عصبی بازگشتی، در دستاوردهای فوقالعاده یادگیری عمیق در سالهای اخیر نقش بسیار مهم و موثری داشته است. با ما همراه باشید تا بیشتر درمورد RNN، کاربردها، انواع و نقاط ضعف و قوتش بیشتر بدانید.
شبکه عصبی بازگشتی چیست؟
شبکه عصبی بازگشتی یکی از انواع قدرتمند و خوش ساخت شبکههای عصبی است و به خاطر حافظه داخلیش، یکی از امیدبخشترین انواع شبکه عصبی هم به حساب میآید.
مانند بسیاری از شبکههای عصبی، RNN هم تا حدی قدیمی محسوب میشود. آنها برای اولین بار در دهه هشتاد میلادی خلق شدند، اما چند سالی بیشتر از کشف پتانسیلهای واقعی آنها نمیگذرد. افزایش توان پردازشی کامپیوترها، حجم عظیم دادهها و ابداع حافظه طولانی کوتاه مدت (long short-term memory - LSTM) بود که شبکه عصبی بازگشتی را به خط مقدم کشاند.
در حالی که در شبکههای عصبی عمیق سنتی فرض بر این است که ورودیها و خروجیهای کاملا مستقل از هم هستند، RNNها به خاطر حافظه داخلیشان میتوانند چیزهای مهمی درمورد ورودیای که دریافت کردهاند به خاطر بسپارند، که به آنها کمک میکند در پیشبینی آنچه در آینده اتفاق میافتد، دقیقتر عمل کنند. به همین دلیل است که شبکه عصبی بازگشتی برای دادههای متوالی، مانند سریهای زمانی، گفتار، متن، دادههای مالی، صوت، ویدئو و... عملکرد خوبی از خود نشان میدهد. در واقع، شبکه عصبی بازگشتی، میتواند نسبت به سایر الگوریتمها، درک عمیقتری از توالی و دانش پس زمینه (context) ورودیها کسب کند.
تفاوت شبکه عصبی بازگشتی با شبکه عصبی پیشخور (Feedforward Neural Network)
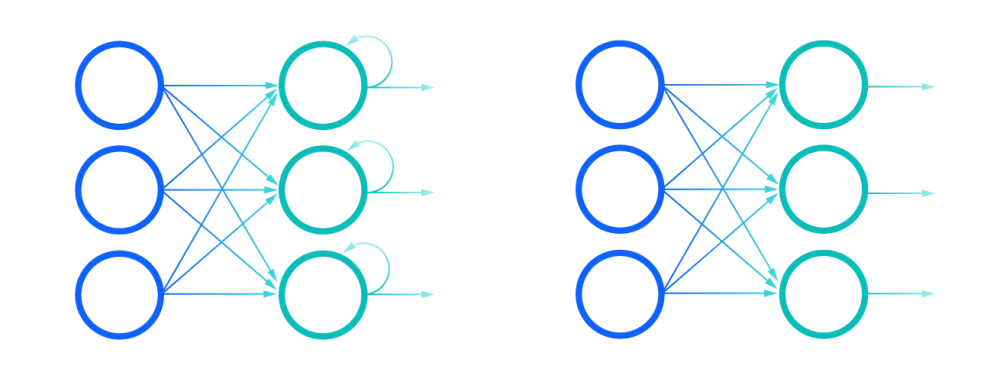
شبکههای عصبی پیشخور و بازگشتی، مطابق با اسمشان با انتقال اطلاعات برخورد میکنند. در شبکه عصبی پیشخور، اطلاعات فقط در یک جهت، از لایه ورودی، در میان لایههای پنهان و به سمت لایه خروجی حرکت میکند. اطلاعات به صورت مستقیم در طول شبکه حرکت میکنند و هرگز دوباره از یک نود (node) عبور نمیکنند. این شبکههای عصبی اصلا ورودیشان را به یاد نمیآورند و در پیشبینی آنچه در ادامه رخ خواهد داد چندان موفق عمل نمیکنند. در واقع، به این علت که شبکه عصبی بازگشتی فقط ورودی حال حاضر را در نظر میگیرد، هیچ درکی از ترتیب زمانی اتفاقات ندارد.
بیایید یک اصطلاح انگلیسی را در نظر بگیریم، مثلا “feeling under the weather”. این اصطلاح وقتی به کار میرود که کسی ناخوش باشد. مثلا ممکن است بعد از چند روز مریضی بگویید “I was still feeling a bit under the weather.”. به این معنی که هنوز هم کمی احساس ناخوشی میکنم. اگر بخواهیم این عبارت را به یک شبکه عصبی پیشخور بدهیم، هنگامی که به کلمه “the” برسیم، شبکه تمام کلمات قبلی را فراموش کرده است و تقریبا غیرممکن است که بتوانند پیشبینی کند بعد از این کلمه، انتظار داریم “weather” بیاید. در حالی که شبکه عصبی بازگشتی، قادر است تمام کلمات قبلی را به خاطر بسپارد و بعد پیشبینی کند که چه کلمهای قرار است، نقش کلمه بعدی را ایفا کند. شبکه، خروجی را تولید میکند، آن را کپی میکند و بعد دوباره به حلقه شبکه برمیگرداند.
به زبان ساده، میتوان اینطور در نظر گرفت که شبکه عصبی بازگشتی، گذشته نزدیک را به زمان حال اضافه میکند. پس RNN دو ورودی دارد: حال و گذشته نزدیک. این موضوع بسیار مهم است، زیرا توالی داده، اطلاعات مهمی از آنچه قرار است اتفاق بیفتد را با خود به همراه دارد.
با استفاده از این اصطلاح میخواهیم ببینیم RNN چگونه کار میکند. برای اینکه این اصطلاح معنادار باشد، ترتیب قرار گیری کلمات آن مهم هستند. به همین دلیل است که شبکه عصبی بازگشتی باید مکان قرار گرفتن هر کلمه در اصطلاح را نگه دارد و از این اطلاعات برای پیشبینی کلمه بعدی در توالی استفاده کند.
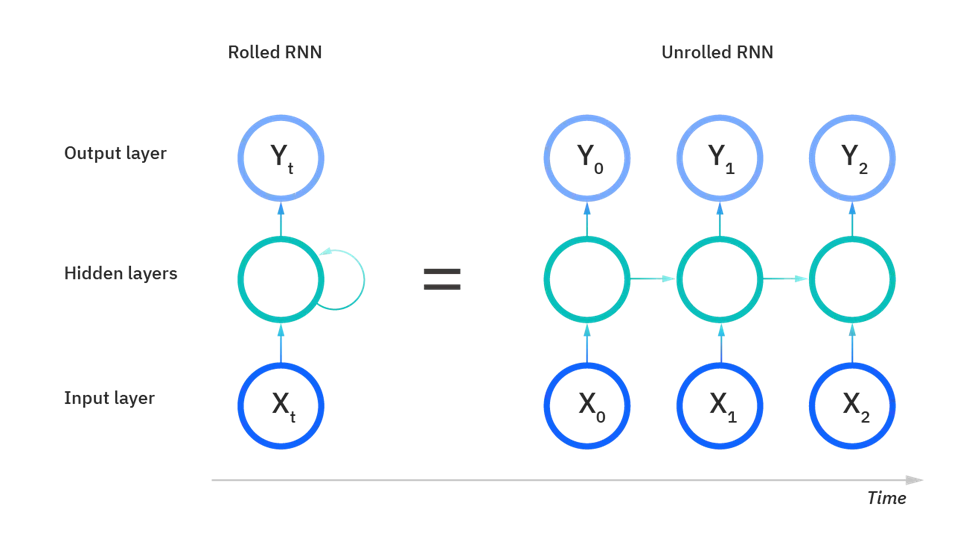
در تصویر زیر، در شکل خلاصهشده RNN که به عنوان “Rolled RNN” مشخص شده است، شمایی از کل یک شبکه عصبی را میتوان دید که در آن کل اصطلاح “feeling under the weather” به عنوان ورودی در نظر گرفته میشود. قسمت “Unrolled RNN” که در سمت راست تصویر آمده است، یک لایه منفرد، یا گامهای زمانی، در یک شبکه عصبی را نشان میدهد. هر لایه را میتوان بازنمایی از یک کلمه در اصللاح مورد نظر دانست. به عنوان مثال “weather” در لایه آخر بازنمایی میشود و ورودیهای قبل از آن مانند “feeling” و “under” هم به عنوان لایههای پنهان (hidden state) در سومین گام زمانی در نظر گرفته میشوند تا خروجی این توالی را پیشبینی کنند، که همان “the” است. در این نمایش، حلقهای که در سمت چپ وجود داشت را مشاهده نمیکنیم، چرا که گامهای زمانی به صورت بازشده نمایش داده شدهاند و اطلاعات از یک گام زمانی به گام بعدی زمانی منتقل میشوند. این تصویر نشان میدهد که چرا میتوانیم RNN را به عنوان یک شبکه عصبی توالی در نظر گرفت.
پس انتشار (Backpropagation) در طول زمان
در شبکههای عصبی، معمولا به این صورت عمل میکنیم که یک انتشار رو به جلو انجام میدهیم، خروجی مدل را میگیریم و با برچسبهای واقعی مقایسه میکنیم تا ببینیم مدل درست عمل کرده است یا خیر و خطای مدل را محاسبه میکنیم. پس انتشار هم عملکردی مشابه دارد؛ با این تفاوت که در شبکه عصبی در جهت عکس حرکت میکند.
پس انتشار به الگوریتم بسیار زحمتکش در یادگیری ماشین شناخته میشود، که به اختصار به آن BP یا backprop هم میگویند. پس انتشار ، برای محاسبه گرادیان تابع خطا نسبت به وزنهای شبکه عصبی مورد استفاده قرار میگیرد. این الگوریتم راهش را به صورت حرکت رو به عقب در طول لایههای مختلف طی میکند تا مشتق جزیی خطا نسبت به وزنها را پیدا کند. سپس این وزنها توسط گرادیان کاهشی مورد استفاده قرار میگیرند: الگوریتمی که در تکرارهایی سعی میکند تابع مورد نظر را کمینه کند. سپس وزنها تنظیم میشوند. و به این ترتیب آموزش شبکه عصبی انجام میشود.
پس به طور خلاصه، با پس انتشار، سعی میکنیم وزنهای مدل را در طول آموزش تنظیم کنیم.
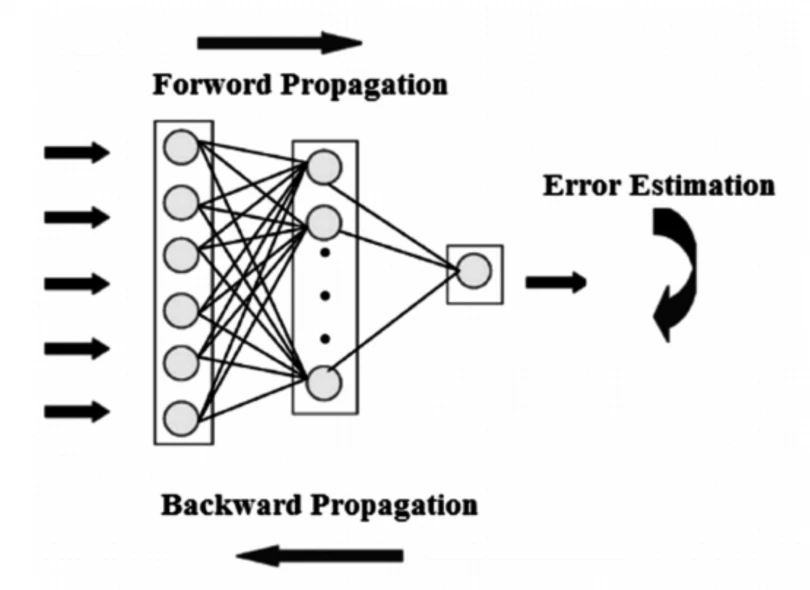
در شکل زیر شمایی از یک شبکه عصبی پیشخور مشاهده میکنید. که در آن، ابتدا انتشار رو به جلو انجام میشود، سپس خطا محاسبه میشود، پس از آن هم پس انتشار اتفاق میافتد.
انواع شبکه عصبی بازگشتی
شبکههای پیشخور (feed forward) یک ورودی را به یک خروجی نگاشت میدهند، در حالی که در شبکه عصبی بازگشتی چنین قیدی وجود ندارد. در این شبکهها، طول ورودیها و خروجیها هم میتوانند متفاوت باشند. انواع مختلف شبکههای RNN برای کاربردهای مختلفی مانند تولید موسیقی، تشخیص احساسات و ترجمه ماشینی مورد استفاده قرار میگیرند. انواع مختلف شبکه RNN را میتوان به صورت زیر دستهبندی کرد:
یک به یک
یک به چند
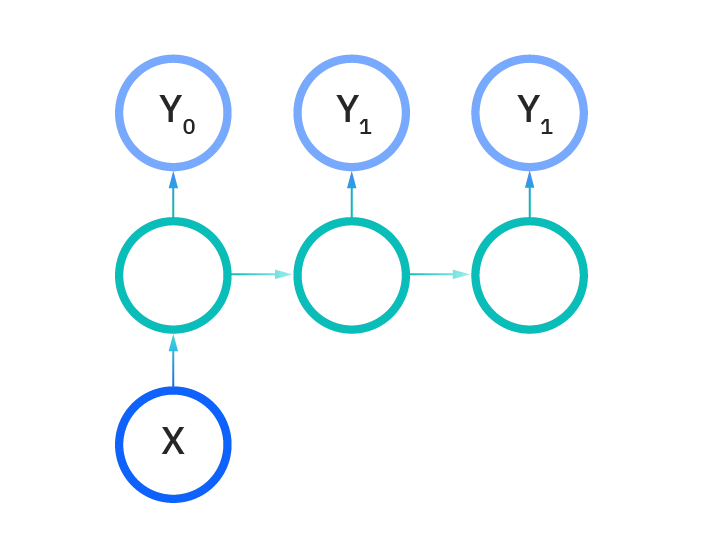
چند به یک

چند به چند
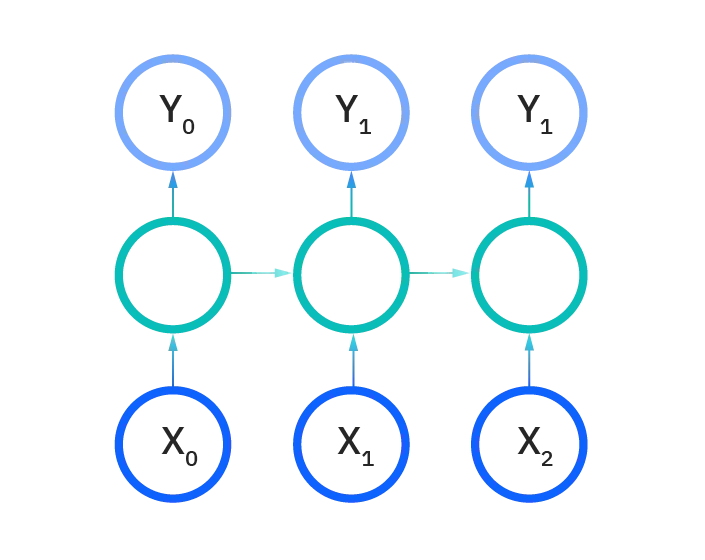
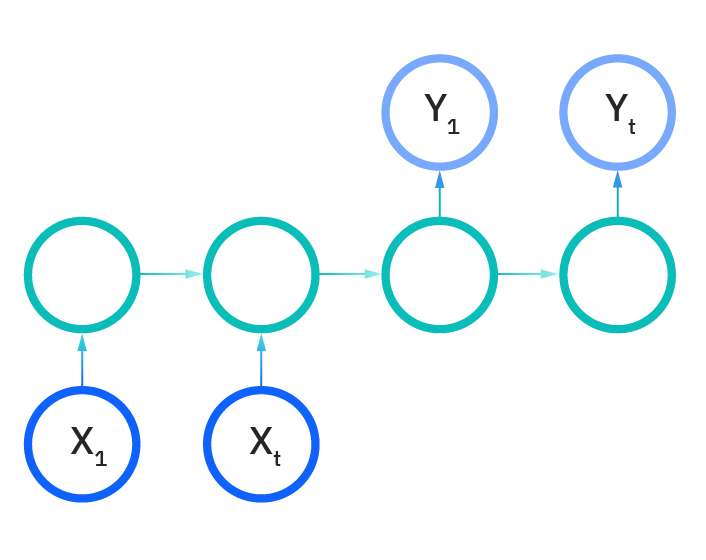
مشکلات شبکه عصبی عمیق بازگشتی
دو مشکل عمده در ارتباط با RNNها وجود دارد. اما برای درک بهتر آنها بهتر است ابتدا نگاهی به مفهوم گرادیان بیندازیم.
گرادیان مشتق جزیی نسبت به ورودیهایش است. به عبارت سادهتر، گرادیان این را اندازه میگیرد که اگه یک تغییر کوچک در ورودی اتفاق بیفتد، خروجی تابع چقدر تغییر میکند. میتوانید گرادیان را به عنوان شیب یک تابع در نظر بگیرید. هر چه گرادیان بزرگتر باشد، یعنی شیب بیشتر است و مدل میتواند با سرعت بیشتری یاد بگیرد. اما وقتی شیب صفر باشد، مدل دیگر یاد نمیگیرد. در واقع، گرادیان تغییرات خطا را نسبت به اعمال تغییرات در وزنها اندازه میگیرد. در تصویر زیر نمونهای از محاسبات گرادیان برای شبکه RNN را مشاهده میکنید. در این شکل، L میزان خطا برای هر نمونه است. با جمع بستن روی تمام خطاها، تابع هزینه به دست میآید. yˆ خروجی شبکه عصبی، y مقدار واقعی، U وزنها و h تابع فعالسازی است.

انفجار گرادیان
انفجار گرادیان زمانی اتفاقی میافتد که وزنها مقادیر بالایی بگیرند و در نتیجه ضرب آنها به عدد بسیار بزرگی تبدیل شود. خوشبختانه این مشکل را میتوان به سادگی با محدود کردن (truncating) گرادیان حل کنیم.
محوشدن گرادیان
محوشدن گردایان هم زمانی اتفاق میافتد که مقادیر گرادیان خیلی کوچک شوند و در نتیجه یادگیری مدل متوقف یا بسیار کند شود. حل کردن این مشکل در دهه ۹۰ میلادی بسیار سختتر از مساله انفجار گرادیان بود. خوشبختانه این مشکل هم با مفهوم LSTM حل میشود.
معماریهای مختلف RNN
حافظه طولانی کوتاه مدت - Long Short-Term Memory (LSTM)
یکی از مواردی که شبکه RNN به خوبی از پس آن برنمیآید، زمانی است که حالت فعلی به حالتی در گذشته بستگی دارد که زمان زیادی از آن گذشته است. در این مقاله، راهکاری نوین برای این مشکل ارائه شد تا مدل بتواند حتی وابستگیهای طولانی مدتتر را هم در پیشبینی حالت بعدی مورد استفاده قرار دهد. علاوه بر این، همانطور که اشاره شد، مشکل محوشدگی گرادیان را هم نداشته باشد.
LSTM، توسعهای از شبکه عصبی بازگشتی به حساب میآید که در واقع حافظه را گسترش میدهد.در نتیجه، این مدل برای مواردی بسیار مهم است که لازم باشد از تجربههایی که زمان طولانی از آنها گذشته است هم یادگیری اتفاق بیفتد. LSTMها به RNN این امکان را میدهند که ورودیها را پس از یک زمان طولانی به خاطر بسپارند، تقریبا شبیه حافظه کامپیوتر. LSTM میتواند اطلاعات را از حافظهاش بخواند، بنویسید یا آنها را پاک کند.
این حافظه را میتوان به عنوان یک سلول با دروازه ورودی در نظر گرفت. دروازه ورودی به این معنی که آن سلول بعد از اینکه میزان اهمیت اطلاعات را تعیین میکند، میتواند تصمیم بگیرد که آیا اطلاعات باید ذخیره شود یا حذف شود (دروازه باز شود یا بسته بماند). میزان اهمیت اطلاعات بر اساس وزنهای شبکه تعیین میشود، که توسط الگوریتم یاد گرفته شدهاند. به زبان ساده، شبکه بعد از مدتی یاد میگیرد که کدام اطلاعات مهم هستند و کدامها مهم نیستند.
در شبکه LSTM سه دروازه داریم: ورودی، فراموشی و خروجی. این دروازهها تعیین میکنند که آیا یک ورودی جدید اجازه عبور پیدا کند یا خیر (دروازه ورودی)، در صورتی که اطلاعاتی بیاهمیت بود حذف شود (دروازه فراموشی)، یا اجازه دهد اطلاعات روی خروجی نهایی تاثیرگذار باشد یا خیر (دروازه خروجی). در شکل زیر شمایی از RNN با این سه دروازه میبنید:
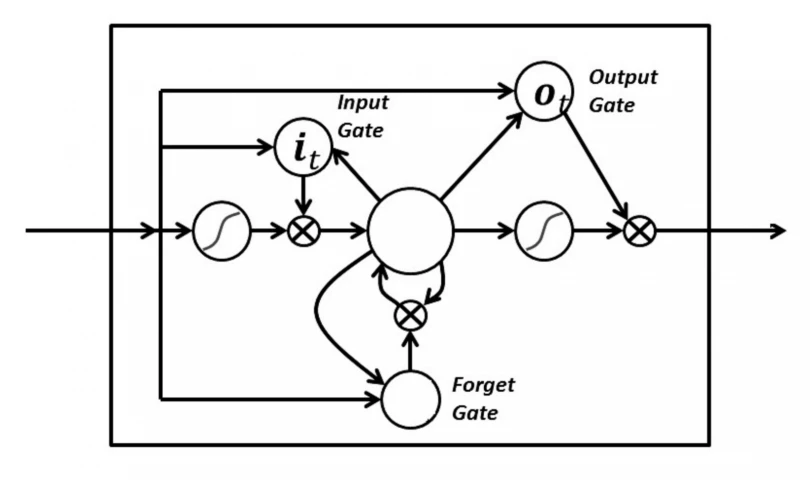
شبکه عصبی بازگشتی دو طرفه - Bidirectional recurrent neural networks (BRNN)
شبکه BRNN نوعی از معماری شبکه عصبی بازگشتی است. در شبکه عصبی بازگشتی یک طرفه، فقط از ورودیهای قبلی برای پیشبینی وضعیت بعدی استفاده میشود، در حالی که در شبکه عصبی بازگشتی دو طرفه، از دادههای آینده هم برای افزایش دقت مدل استفاده میشود. اگر به مثالی که ابتدای این مطلب مطرح شد برگردیم، در اصطلاح “feeling under the weather”، اگر مدل بداند آخرین کلمه در این توالی “weather” است، بهتر میتواند دومین کلمه در عبارت، یعنی “under” را پیشبینی کند.
شبکه عصبی بازگشتی گیتی - Gated recurrent units (GRUs)
این نوع از شبکه عصبی بازگشتی، مانند LSTM، برای این طراحی شده است که مشکل کوتاه بودن حافظه RNN را حل کند. اما در شبکه بازگشتی گیتی، به جای سلول وضعیت، از لایههای پنهان برای مدیریت و دستهبندی اطلاعات استفاده میشود. و به جای سه دروازه، دارای دو دروازه است: دروازه بازنشانی و دروازه به روز رسانی. مانند LSTMها، این دو دروازه هستند که تعیین میکنند کدام اطلاعات مفید هستند و کدامها مفید نیستند.
خلاصه
در این مطلب با شبکه عصبی RNN و مزایا و معایبش آشنا شدیم. این شبکههای عصبی برای کار کردن بر روی دادههای ورودی متوالی مناسب هستند، همچنین میتوانند ورودیهایی با طول متفاوت را بپذیرند. یکی دیگر از مزایای شبکههای RNN این است که امکان ذخیره دادههای گذشته را دارند. از معایب این شبکهها این است که انجام محاسبات آنها میتواند بسیار کند و هزینهبر باشد. همچنین احتمال اتفاق افتادن انفجار گرادیان یا محو شدگی گرادیان وجود دارد که البته راهحلهایی برای حل کردن این مشکلات وجود دارد. در نهایت با شناخت این مدل، میتوانید تصمیم بگیرید که آیا این مدل برای حل مساله شما مناسب است یا خیر.