

در قسمت قبلی با روشهای نمونهبرداری تصادفی ساده و نمونهبرداری سیستماتیک آشنا شدید و یاد گرفتید چگونه از یک جامعه آماری نمونههای مناسبی انتخاب کنید. اما پس از انتخاب نمونه، سؤال اصلی این است که تخمینهایی که از این نمونه بهدست میآوریم تا چه حد دقیق هستند؟
در این فصل از دوره آموزشی نمونهبرداری با پایتون، با تمرکز بر اندازه نمونه و معرفی مفهوم خطای نسبی بررسی میکنید که افزایش حجم نمونه چگونه دقت تخمینهای نقطهای را بهبود میدهد و عدمقطعیت آماری را کاهش میدهد.
خطای نسبی در تخمین نقطهای
در این فصل، هدف ما بررسی روشهای نمونهبرداری و ارزیابی دقت آمارهای نمونهای است. این کار با استفاده از خطای نسبی و همچنین اندازهگیری میزان تغییرپذیری تخمینها از طریق توزیعهای نمونه انجام میشود. در بخش نخست، تمرکز ما بر این موضوع است که اندازه نمونه چه تأثیری بر دقت تخمینهای نقطهای دارد.
برای شروع، وارد محیط Jupyter Notebook میشویم. در این فصل نیز، همانند فصلهای قبل، بررسی خود را بر روی مجموعهدادهی Coffee Ratings ادامه میدهیم. هدف این است که بررسی کنیم اندازه نمونه چگونه میتواند بر دقت تخمینهای نقطهای که محاسبه میکنیم تأثیر بگذارد. در گام بعد، از این مجموعهداده نمونهبرداری میکنیم. در این مرحله، نوع روش نمونهبرداری اهمیت زیادی ندارد؛ با این حال، در ادامه از نمونهبرداری تصادفی ساده استفاده میکنیم. این روش در بسیاری از کاربردها عملکرد مناسبی دارد و تحلیل و استدلال دربارهی آن نسبتاً ساده است. برای انجام نمونهبرداری، مجموعهداده اصلی را در نظر گرفته و از تابع sample استفاده میکنیم. در این تابع میتوان از آرگومان n برای تعیین اندازه نمونه استفاده کرد.
#In [3]:
coffee_ratings.sample(n=300)
همچنین میتوان بهجای تعیین تعداد نمونه، از آرگومان frac استفاده کرد. برای مثال، اگر مقدار آن را برابر با 0.25 قرار دهیم، ۲۵٪ از دادهها بهصورت تصادفی انتخاب میشوند.
#In [4]:
coffee_ratings.sample(frac=0.25)
برای محاسبه اندازه نمونه، کافی است از تابع len استفاده کنیم.
در این مثال مشاهده میکنیم که اندازه نمونه برابر با ۳۰۰ مشاهده است. برای نمونهی بعدی نیز به همین روش میتوان اندازه نمونه را محاسبه کرد.
#In [5]:
len(coffee_ratings.sample(n=300))
#300در واقع، اندازه نمونهای که محاسبه میکنیم نشاندهنده تعداد مشاهدات یا همان تعداد ردیفهای مجموعهداده نمونه است.
محاسبه پارامتر جمعیتی
اکنون یک پارامتر جمعیتی را محاسبه میکنیم؛ برای مثال، میانگین امتیاز قهوهها در کل مجموعهداده. از این مقدار بهعنوان یک استاندارد طلایی برای مقایسه با تخمینهای نمونهای استفاده خواهیم کرد.
#In [7]:
coffee_ratings['total_cup_points'].mean()
#82.15120328849018تخمین نقطهای میانگین
در ادامه، یک متغیر به نام sample_size تعریف کرده و مقدار آن را برابر با ۱۰ قرار میدهیم.
سپس با استفاده از این اندازه نمونه، یک نمونهبرداری انجام داده و تخمین نقطهای میانگین ستون Total Cup Points را برای این مجموعهداده نمونه محاسبه میکنیم.
#In [9]:
coffee_ratings.sample(n=sample_size)['total_cup_points'].mean()
#81.326در نمونهای با اندازه ۱۰، مقدار تخمینزدهشدهی میانگین برابر با 81.326 بهدست میآید که حدود 0.83 واحد با پارامتر جمعیتی فاصله دارد.
اکنون اندازه نمونه را به ۱۰۰ افزایش میدهیم.
#In [10]:
sample_size = 100
coffee_ratings.sample(n=sample_size)['total_cup_points'].mean()
#82.43099999999998در این حالت، مقدار میانگین نمونه برابر با 82.43 محاسبه میشود که نسبت به حالت قبل دقیقتر است، زیرا به مقدار پارامتر جمعیتی (82.15) نزدیکتر شده است.
حال اگر همین فرآیند را با اندازه نمونه ۱۰۰۰ تکرار کنیم، مقدار زیر بهدست میآید:
#In [11]:
sample_size = 1000
coffee_ratings.sample(n=sample_size)['total_cup_points'].mean()
#82.17704999999991مشاهده میکنیم که این مقدار فاصلهی بسیار کمی با پارامتر جمعیتی دارد. بهطور کلی، هرچه حجم نمونه بزرگتر باشد، دقت تخمینهای نقطهای افزایش مییابد.
محاسبه خطای نسبی
اکنون قصد داریم خطای نسبی را محاسبه کنیم. برای این کار، لازم است میانگین جامعه را با میانگین نمونه برای هر اندازه نمونه مقایسه کنیم. رایجترین معیار برای ارزیابی تفاوت بین پارامتر جمعیتی و تخمین نمونهای، خطای نسبی (Relative Error) است.
در ابتدا یک متغیر تعریف میکنیم و مقدار پارامتر جمعیتی را در آن ذخیره میکنیم. سپس همین کار را برای یکی از میانگینهای نمونهای که محاسبه کردهایم انجام میدهیم.
#In [13]:
population_mean = coffee_ratings['total_cup_points'].mean()
#In [14]:
sample_mean = coffee_ratings.sample(n=sample_size)['total_cup_points'].mean()
#In [15]:
rel_error_pct = 100 * abs(population_mean - sample_mean) / population_mean
rel_error_pct
#0.0337953522028276در این محاسبه:
- اختلاف مطلق بین میانگین جامعه و میانگین نمونه در نظر گرفته میشود.
- علامت منفی حذف میشود.
- نتیجه در عدد ۱۰۰ ضرب میشود تا مقدار خطا به صورت درصدی نمایش داده شود.
رسم نمودار خطای نسبی
در ادامه، یک نمودار خطی از خطای نسبی در مقابل اندازه نمونه رسم میکنیم تا تأثیر حجم نمونه بر دقت تخمین را بهصورت بصری مشاهده کنیم.
#In [18]:
sample_size = np.arange(1, 1339, 1)
relative_error = [100 * abs(population_mean - coffee_ratings.sample(n=samp)['total_cup_points'].mean()) / population_mean for samp in sample_size]
d = {'sample_size': sample_size, 'relative_error': relative_error}
error = pd.DataFrame(d)
#In [19]:
error.plot(x='sample_size', y='relative_error', kind='line')
#<AxesSubplot:xlabel='sample_size'>پس از اجرای کد، نمودار زیر بهدست میآید که کاهش خطای نسبی با افزایش اندازه نمونه را بهخوبی نشان میدهد.
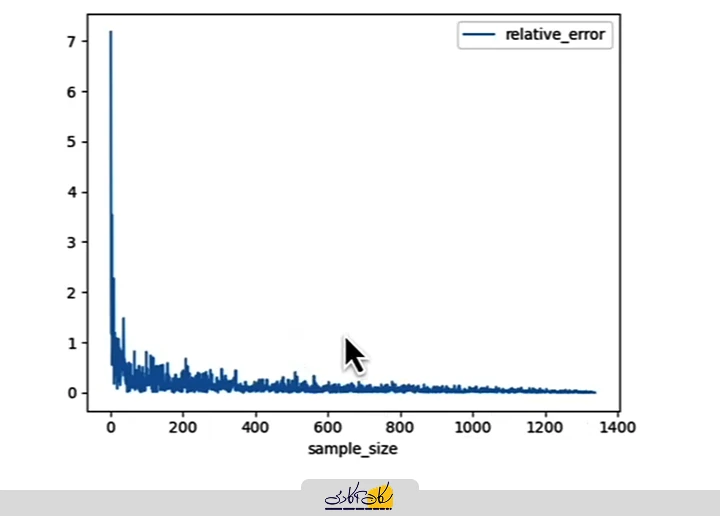
همانطور که در نمودار مشاهده میکنیم، با افزایش حجم نمونه، مقدار خطای نسبی بهتدریج کاهش پیدا میکند. خط آبیرنگ نمودار در بخش مربوط به اندازههای نمونه کوچک، نوسان زیادی دارد. این موضوع نشان میدهد که زمانی که حجم نمونه کم است، میانگین نمونهای ناپایدار بوده و با اضافه یا حذف شدن تنها چند مشاهدهی تصادفی، مقدار آن میتواند تغییر قابلتوجهی داشته باشد. به بیان دیگر، در نمونههای کوچک، تخمین میانگین بهشدت به ترکیب دادههای انتخابشده حساس است.
نکته مهم دیگر، شیب تند نمودار در ابتدای مسیر است. وقتی حجم نمونه کوچک است، اضافه کردن تعداد کمی مشاهدهی جدید میتواند باعث بهبود چشمگیر دقت تخمین شود. و در نهایت هم وقتی حجم نمونه برابر میشود با جامعه ما خطای نسبی به 0 کاهش پیدا میکنه. اما هرچه به سمت راست نمودار حرکت میکنیم و اندازه نمونه افزایش مییابد، شیب خط کمتر میشود و کاهش خطا با سرعت کمتری اتفاق میافتد.
در حجمهای نمونه بزرگ، اضافه کردن چند ردیف جدید تأثیر چندانی بر دقت تخمین ندارد.
این موضوع نشاندهندهی پدیدهی بازدهی نزولی در افزایش اندازه نمونه است؛ یعنی پس از رسیدن به یک حجم مشخص، افزایش بیشتر دادهها بهبود قابلتوجهی در دقت ایجاد نمیکند.
در نهایت، زمانی که حجم نمونه با کل جامعه آماری برابر میشود، مقدار خطای نسبی به صفر میرسد. در این حالت، دیگر تخمینی انجام نمیشود، بلکه پارامتر جمعیتی بهطور کامل محاسبه شده است.
جمعبندی
در این فصل مشاهده کردید که اندازه نمونه نقش تعیینکنندهای در دقت تخمینهای نقطهای دارد. نتایج نشان داد که در نمونههای کوچک، تخمینها ناپایدار بوده و تغییرات جزئی در دادهها میتواند باعث اختلاف قابلتوجه در نتایج شود.
همچنین دیدید که با افزایش حجم نمونه، خطای نسبی بهطور چشمگیری کاهش مییابد؛ هرچند این کاهش در ابتدا سریع است و بهمرور با بزرگتر شدن نمونه، آهنگ کندتری پیدا میکند. این رفتار بیانگر آن است که پس از رسیدن به یک حجم مناسب از دادهها، افزایش بیشتر اندازه نمونه الزاماً منجر به بهبود قابلتوجه دقت نمیشود.
در نهایت، زمانی که نمونه با کل جامعه آماری برابر میشود، خطای نسبی به صفر میرسد و تخمین جای خود را به محاسبه دقیق پارامتر جمعیتی میدهد.