

وب اسکرپینگ چیست و به چه معناست؟
یکی از روشهای جمعآوری داده از اینترنت برای ایجاد دیتاست مورد نظر، استخراج دادهها از صفحات وب (web scraping) است. با استفاده از این روش، میتوانیم اطلاعات ساختاریافته را از میان صفحات مختلف استخراج کرده و سپس آنها را بر اساس ساختاری که تعیین کردهایم، ذخیره کنیم. به عنوان مثال، میتوانیم دادهها را در قالب فایل CSV ذخیره کنیم.
برای روشنتر شدن این موضوع، فرض کنید که قصد داریم اطلاعات آب و هوایی دو ماه آینده را از یک سایت هواشناسی جمعآوری کنیم. یا اینکه میخواهیم اخبار روزانه یک سایت خبری را بر اساس دستهبندیهای موضوعی، میزان بازدید یا واکنش کاربران ذخیره کنیم. یکی از ابزارهای کلیدی که در این فرایند به کار میآید، وب اسکرپینگ است.
وب اسکرپینگ به ما این امکان را میدهد که به مستندات HTML صفحات وب دسترسی پیدا کنیم و دادههای مورد نظر را از آنها استخراج کنیم. این در حالی است که در روش دیگری که در فصل بعد به آن خواهیم پرداخت، اطلاعات از طریق APIها دریافت میشود.
آشنایی با HTML و نقش آن در وب اسکرپینگ
HTML که مخفف عبارت Hyper Text Markup Language است (به معنای زبان نشانهگذاری متن) ، برای طراحی مستنداتی به کار میرود که در مرورگرهای وب، مانند گوگل کروم یا فایرفاکس، قابل مشاهده هستند. به عنوان مثال، صفحه وبی که ما مشاهده میکنیم، در واقع یک سند HTML مانند “Index.html” است.
درواقع HTML شامل مجموعهای از ساختارهاست که به آنها «تگ» (tag) گفته میشود و اطلاعات غیرساختاری مانند متن و دیگر عناصر قابل مشاهده را در بر میگیرد. تمام این اطلاعات برای مرورگر قابل خواندن است و به ما این امکان را میدهد که محتوای صفحات وب را مشاهده کنیم.
💎 برای آموزش کامل و درک عمیق تر HTML به دوره آموزش رایگان HTML سکان آکادمی مراجعه کنید.
ابزارهای وب اسکرپینگ در پایتون برای استخراج داده از HTML
برای استخراج داده از اسناد HTML که از صفحات وب با استفاده از درخواستهای GET دریافت میکنیم، میتوانیم از چند ابزار مؤثر در زبان برنامهنویسی پایتون استفاده کنیم. در اینجا به سه ابزار عمده اشاره میشود:
1. کتابخانه BeautifulSoup
اولین ابزار (که در این دوره با آن کار خواهیم کرد)، کتابخانه Beautiful Soup است. این کتابخانه بهطور خاص برای تجزیه و استخراج دادهها (Parse و Extract) از اسناد HTML و XML طراحی شده است. در واقع، Beautiful Soup متن HTML را بهصورت رشتهای از درخواست (Request) دریافتی پردازش میکند و آن را به یک Parser تبدیل میکند که ما میتوانیم با استفاده از متدهای آن، اطلاعات موجود در ساختار HTML را دریافت کنیم.
2. فریمورک Scrapy
ابزار بعدی که در اختیار ما قرار دارد، فریمورک Scrapy است. این فریمورک بسیار پرکاربرد بوده و عمدتاً برای وبکراولینگ (web crawling) استفاده میشود که با وباسکرپینگ تفاوتهایی دارد. برای آگاهی بیشتر در این مورد میتوانید مقالهی تفاوت بین Web Scraping و Web Crawling را مطالعه کنید.
Scrapy بهویژه در پروژههای اسکرپینگ و حتی زمانی که با APIها سروکار داریم، برای استخراج دادهها بسیار مفید است.
3. ابزار سلنیوم (Selenium)
ابزار دیگری که در کنار BeautifulSoup مورد استفاده قرار میگیرد، سلنیوم (Selenium) است. سلنیوم بهطور خودکار اقداماتی را که معمولاً در مرورگر انجام میدهیم، (مانند اسکرول کردن، کلیک کردن و ...) انجام میدهد. این ابزار بهویژه در مواقعی که با سایتهای پویا مانند سکان آکادمی کار میکنیم، که اطلاعات بهصورت تدریجی با اسکرول کردن بارگذاری میشود (که به آن Lazy Loading یا Infinite Loading گفته میشود)، بسیار کارآمد است. با استفاده از سلنیوم میتوانیم بهراحتی اطلاعات را از این نوع صفحات استخراج کنیم. برای آموزش کار با سلنیوم به این مقاله مراجعه کنید: چه طور با selenium یک قهرمان تست خودکار باشیم؟
👈 در این دوره، تمرکز ما بر روی استخراج داده از سایتهای استاتیک خواهد بود، که شامل صفحاتی است که تمام اطلاعات در آنها موجود است و برای دسترسی به اطلاعات بیشتر، باید به صفحات بعدی مراجعه کنیم. در جلسات آینده، با استفاده از ابزارهای مذکور، به استخراج داده از این نوع سایتها خواهیم پرداخت.
وب اسکرپینگ با BeautifulSoup
نصب و راهاندازی BeautifulSoup
همانطور که اشاره کردیم، قصد داریم با پکیج BeautifulSoup کار کنیم. برای نصب این پکیج، ابتدا باید در ترمینال خود و در محیط پایتون مورد نظر (فارغ از اینکه از Conda استفاده میکنید یا هر محیط دیگری)، دستور زیر را وارد کنید:
pip install beautifulsoup4پس از نصب موفقیتآمیز، میتوانید به سادگی این پکیج را در پروژه خود وارد کنید. لازم به ذکر است که برخلاف کتابخانههای استاندارد پایتون، BeautifulSoup یک کتابخانه استاندارد built-in نیست و بنابراین باید آن را بهطور جداگانه نصب نمایید.
پیادهسازی یک پروژه کوچک با BeautifulSoup
اکنون قصد داریم یک پروژه کوچک را با استفاده از BeautifulSoup پیادهسازی کنیم تا با روند کار این پکیج آشنا شویم. اولین قدم این است که پکیج را وارد کنیم. در پایتون، BeautifulSoup بهصورت زیر وارد میشود:
from bs4 import BeautifulSoupدر اینجا، “BeautifulSoup” با حرف بزرگ “B” نوشته میشود و این کلاس به ما امکان میدهد تا پارسر (parser) مورد نظر خود را بسازیم.
همچنین، برای این پروژه به کتابخانه requests نیز نیاز داریم که بهصورت زیر وارد میشود:
import requestsبرای شروع، باید آدرس URL صفحهای که میخواهیم اطلاعات آن را استخراج کنیم، مشخص کنیم. به عبارت دیگر، ما قصد داریم یک درخواست GET ارسال کنیم تا HTML صفحه را دریافت کنیم:
url = "https://sokanacademy.com"
r = requests.get(url)
html_doc = r.text
r.close()توجه داشته باشید که زمان بارگذاری اطلاعات ممکن است بسته به سرعت اینترنت شما متفاوت باشد. در خروجی، اطلاعات را بهصورت یک رشته تحویل میگیریم.
اکنون که یک متغیر html_doc داریم، میتوانیم آن را به کلاس BeautifulSoup پاس دهیم. در این مرحله، یک متغیر به نام soup ایجاد میکنیم و محتوای HTML را به آن منتقل میکنیم. به این ترتیب، یک “soup” داریم که شامل ساختارهای مختلف HTML، یعنی تگها، است. هدف ما این است که بتوانیم این تگها را پیدا کرده، انتخاب کنیم و اطلاعات مورد نظر خود را از آنها استخراج کنیم. به عنوان مثال به استخراج اطلاعات تگ title (تگ عنوان) میپردازیم.
استخراج اطلاعات تگ title با کتابخانه BeautifulSoup
تگ عنوان، همان تگی است که محتوای آن در بالای مرورگر نمایش داده میشود.
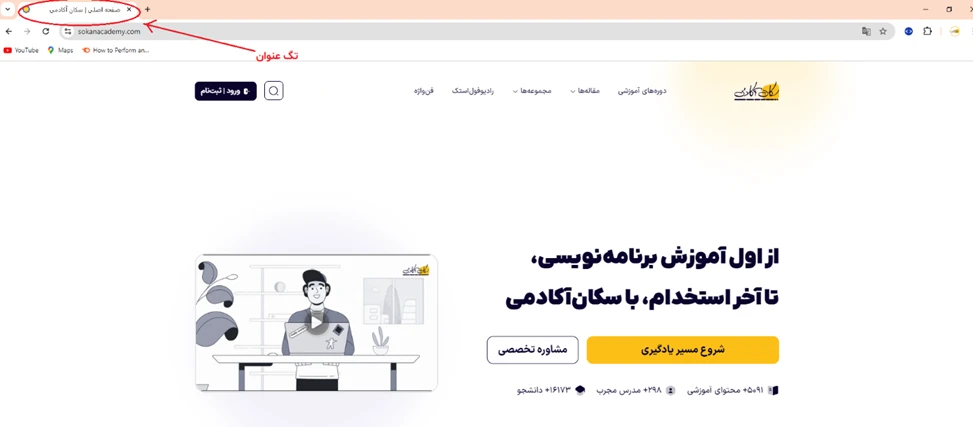
برای دسترسی به این تگ و نمایش آن، میتوانیم از متد title با کد زیر استفاده کنیم:
print(soup.title)زمانی که این کد را اجرا کنیم، عنوان سایت را در خروجی به ما نمایش میدهد:
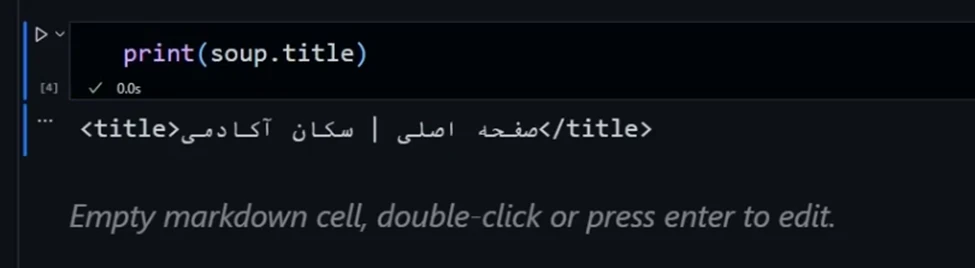
به این ترتیب، با استفاده از BeautifulSoup میتوانیم به سادگی به اطلاعات مهمی مانند عنوان صفحه دسترسی پیدا کنیم و آن را استخراج نماییم.
متدهای دیگر در BeautifulSoup برای وب اسکرپینگ
متدهای زیادی در BeautifulSoup برای دسترسی به محتوای تگهای های مختلف وجود دارد.
به عنوان مثال متد ()get_text ، تمامی متون موجود در یک صفحه HTML را استخراج کرده و بهصورت یک رشته به ما نمایش میدهد. این متد به ما این امکان را میدهد که بدون توجه به ساختار تگها، تمامی متنهای موجود در صفحه را بهراحتی مشاهده کنیم.
برای استفاده از این متد، میتوانیم بهسادگی از کد زیر استفاده کنیم:
Print(soup.get_text())با اجرای این کد، تمامی متونی که در صفحه وجود دارد، بهصورت یکجا و بدون هیچگونه فرمت خاصی نمایش داده میشود. این روش به ما کمک میکند تا به سرعت محتوای متنی صفحه را مشاهده کنیم و از آن برای تحلیلهای بعدی استفاده کنیم.
به عنوان مثالی دیگر، میتوان به متد find_all اشاره کرد که از متدهای مفید در Beautiful Soup است. با استفاده از این متد، میتوانیم به جستجوی تگهای خاص در محتوای HTML بپردازیم و آنها را در soup خود پیدا کنیم. این متد به ما این امکان را میدهد که تگهای مورد نظر را تجزیه کرده و در قالب یک لیست ذخیره کنیم.
متد find_all بهعنوان یک ایتراتور (iterator) عمل میکند و تمامی نمونههای تگ مشخصشده را در محتوای HTML جستجو میکند. بهعنوان مثال، اگر بخواهیم تمامی تگهای <a> (لینکها) را پیدا کنیم، میتوانیم از کد زیر استفاده کنیم:
links = soup.find_all('a')در اینجا، متغیر links شامل تمامی تگهای <a> موجود در محتوای HTML خواهد بود. با استفاده از این لیست، میتوانیم بهراحتی به اطلاعات موجود در هر یک از این تگها دسترسی پیدا کنیم و آنها را تجزیه و تحلیل کنیم.
بهطور کلی، متد find_all یکی از ابزارهای قدرتمند برای استخراج دادهها از HTML است و به ما این امکان را میدهد که بهصورت مؤثری با ساختارهای مختلف صفحات وب کار کنیم.