Database Scaling به فرآیندی گفته میشود که در آن عملکرد و ظرفیت یک دیتابیس برای پشتیبانی از حجم بیشتری از دادهها و تعداد بیشتری از کاربران بهبود داده میشود. در زیر لیستی از روشهای اصلی برای Database Scaling را مشاهده میکنید که هر کدام بسته به نیاز و شرایط معماری محصولتان گزینه مناسبی برای انتخاب هستند.
1. Vertical Scaling (Scaling Up)
- افزایش منابع سختافزاری یک سرور
- استفاده از سرورهای قویتر
- محدودیتهای فیزیکی
2. Horizontal Scaling (Scaling Out)
- اضافه کردن سرورهای بیشتر برای توزیع بار
اصلی ترین تکنیک ها:
- Sharding: تقسیم دادهها به بخشهای کوچکتر
- Replication: کپی کردن دادهها روی سرورهای مختلف
3. Partitioning
- Horizontal Partitioning (Sharding)
- Vertical Partitioning: تقسیم ستونهای جدول
4. Replication
- Master-Slave Replication: یک سرور اصلی و چندین سرور جانبی
- Master-Master Replication: چندین سرور اصلی
5. Database Clustering
- استفاده از چندین سرور پایگاه داده به عنوان یک واحد یکپارچه
6. Cloud Scaling
- استفاده از خدمات ابری برای Scaling و یا Auto-scaling
- مدلهای ابری Pay-as-you-go
7. Materialized View
- ساخت جدولی از کوئری های پرمصرف
- ترکیبی از Indexing و Denormalization
8. Indexing
- ذخیره سازی داده های اضافه برای یافتن سریعتر نتایج
9. Denormalization
- ذخیره داده های تکراری برای جلوگیری از Joind
در لیست بالا 6 مورد اول در دسته ی High-Level قرار میگیرند و در طراحی اولیه یا انتخاب زیرساخت مناسب برای نیازمندی مان باید به آنها فکر کنیم. ولی سه مورد آخر یعنی موارد 7 و 8 و 9 در دسته ی Low-Level قرار میگیرند و جدای از موضوعات زیرساختی و … میتوان با این روش ها دیتابیس مان را برای پاسخ گویی به حجم بیشتری از داده ها یا درخواست ها آماده کنیم.
Vertical Scaling (Scaling Up)
Vertical Scaling یا Scaling Up به معنای افزایش ظرفیت و قدرت سختافزاری یک سرور است که میتواند درخواستها و بار بیشتری را تحمل کند. در این روش، به جای اضافه کردن سرورهای جدید، منابع سرور فعلی (مثل RAM، CPU یا فضای ذخیرهسازی) ارتقا داده میشود. این روش اغلب زمانی استفاده میشود که نیاز به بهبود عملکرد بدون تغییر در ساختار سیستم باشد.
ویژگیهای Scaling Up
به دلیل اینکه شما فقط نیاز دارید روی یک سرور تغییراتی را در سطح منابع بدهید، و نیازی به تغییرات مختلف در دیگر سرورها ندارید، در نتیجه سادگی بیشتری را نسبت به روشهای دیگر تجربه خواهید کرد.
برخلاف Scaling Out که ممکن است به تغییراتی در ساختار دادهها و معماری نیاز داشته باشد، در Scaling Up معمولاً نیازی به تغییر در برنامه یا پایگاه داده نیست.
سرورهای فیزیکی همیشه دارای محدودیتهایی هستند. برای مثال، یک سرور فقط میتواند حداکثر مشخصی RAM یا CPU داشته باشد و بعد از آن امکان ارتقا وجود ندارد.
سختافزارهای قدرتمند (مانند سرورهای با RAM یا CPU بالا) معمولاً بسیار گران هستند و با افزایش منابع، هزینهها به شکل قابل توجهی افزایش مییابد.
در Scaling Up اگر سرور اصلی خراب شود، کل سیستم متوقف میشود. برعکس Scaling Out که در آن چندین سرور وجود دارد و خرابی یک سرور باعث توقف کل سیستم نمیشود.
Horizontal Scaling (Scaling Out)
Horizontal Scaling یا Scaling Out به معنای اضافه کردن سرورهای جدید برای توزیع بار کاری و دادهها است. برخلاف Vertical Scaling که با افزایش منابع سختافزاری یک سرور بهبود عملکرد را ایجاد میکند، در Horizontal Scaling از چندین سرور استفاده میشود تا ظرفیت سیستم بهبود یابد.
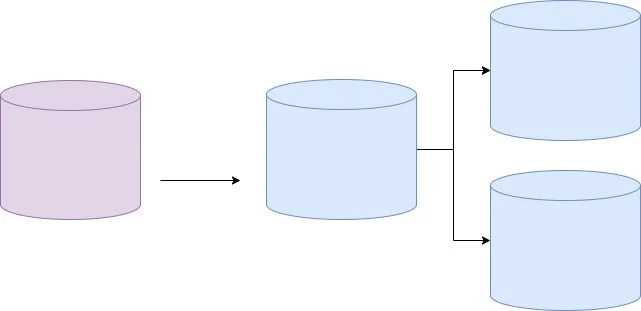
ویژگیهای Horizontal Scaling
در این روش، تعداد سرورها افزایش مییابد و در نتیجه برعکس روش Scaling Up در این روش محدودیتی نداریم.
با اضافه شدن سرورهای جدید، درخواستها به صورت یکسان بین آنها تقسیم میشوند و بار روی هر سرور کاهش مییابد. این توزیع معمولاً توسط یک Load Balancer مدیریت میشود.
در این روش اگر یکی از سرورها از کار بیفتد، سیستم همچنان به کار خود ادامه میدهد، زیرا دادهها و درخواستها بین سرورهای دیگر توزیع شدهاند. این ویژگی باعث افزایش دسترسپذیری (High Availability) میشود.
مدیریت چندین سرور به مراتب پیچیدهتر از یک سرور است. برای هماهنگی دادهها بین سرورها و تضمین صحت دادهها، به تکنیکهایی مانند Replication یا Sharding نیاز است. این میتواند مدیریت سیستم را دشوارتر کند.
این روش به شما اجازه میدهد هر زمان که نیاز به افزایش ظرفیت دارید، سرورهای جدید اضافه کنید و بدون تغییر زیاد در سیستم، به تعداد زیادی از کاربران خدمترسانی کنید.
تکنیکهای اصلی در Horizontal Scaling
Sharding
در این روش، دادهها به بخشهای کوچکتری (shards) تقسیم شده و هر بخش روی یک سرور مجزا قرار میگیرد.
Replication
در این روش، دادههای پایگاه داده روی چندین سرور کپی میشود.
Load Balancing
در این تکنیک، یک Load Balancer بین کاربران و سرورها قرار میگیرد و درخواستها را به صورت یکسان بین سرورها تقسیم میکند.
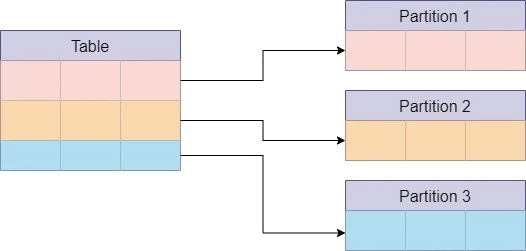
Partitioning
روش بعدی Partitioning است که به تقسیم پایگاه داده به بخشهای کوچکتر برای بهبود عملکرد و مدیریت بهتر دادهها اشاره دارد. این روش میتواند بخشی از استراتژی Horizontal Scaling باشد و به سیستمهای بزرگی که حجم زیادی از داده را مدیریت میکنند کمک کند تا سریعتر و کاراتر عمل کنند.
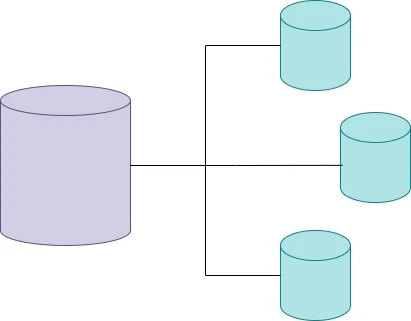
ویژگیهای Partitioning
دادهها به بخشهای جداگانهای به نام "پارتیشن" تقسیم میشوند که هر بخش میتواند به صورت مجزا مدیریت و ذخیره شود.
با تقسیم دادهها، حجم پردازش برای هر درخواست کاهش مییابد که منجر به سرعت بیشتر در جستجو و بازیابی اطلاعات میشود.
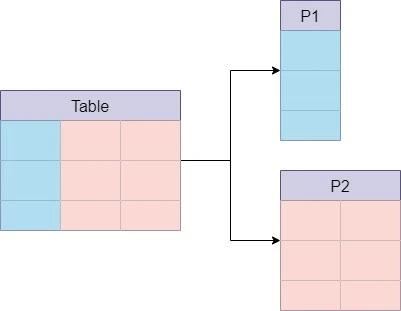
این روش به شما اجازه میدهد دادهها را در سرورهای مختلف توزیع کنید و از مزایای Horizontal Scaling بهرهبرداری کنید.
اگر دادهها به بخشهای کوچکتر و مجزا تقسیم شوند، مدیریت آنها از نظر Backup گیری، نگهداری و حتی اعمال سیاستهای امنیتی سادهتر میشود.
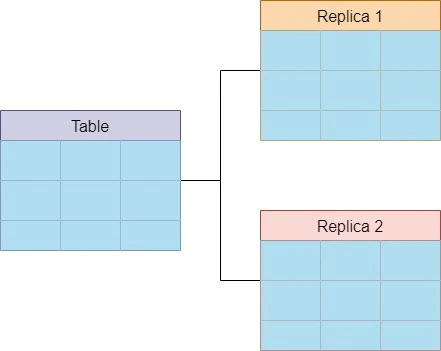
Replication
Replication به فرآیند کپی کردن دادهها از یک پایگاه داده اصلی به یک یا چند پایگاه داده جانبی گفته میشود. هدف اصلی از این روش، بهبود دسترسپذیری (Availability)، قابلیت اطمینان (Reliability)، و افزایش عملکرد (Performance) سیستم است.
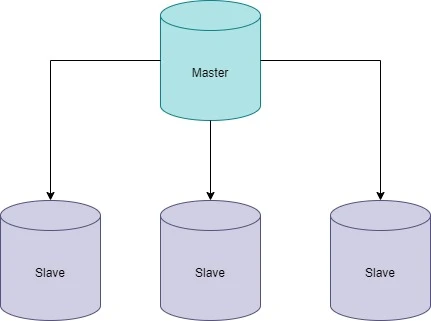
انواع Replication
Master-Slave Replication
در این مدل، یک سرور اصلی (Master) وجود دارد که تمام دستورات نوشتن را انجام میدهد و دادهها از سرور اصلی به سرورهای Slave کپی میشوند.
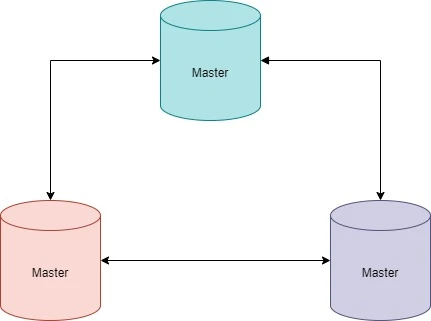
Master-Master Replication
در این مدل، چندین سرور اصلی وجود دارند که هر یک میتوانند هم عملیات خواندن و هم عملیات نوشتن را انجام دهند.
Database Clustering
Database Clustering یکی از روشهای مهم و مؤثر در مقیاسپذیری پایگاههای داده است که به کمک آن میتوان چندین سرور پایگاه داده را به عنوان یک واحد یکپارچه مدیریت کرد. این روش به خصوص در شرایطی که حجم بزرگی از دادهها و درخواستهای همزمان وجود دارد، اهمیت زیادی پیدا میکند.
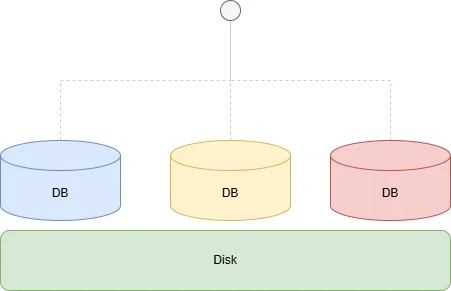
ویژگیهای Database Clustering
اگر یک سرور دچار مشکل شود، بقیه سرورها میتوانند به عملکرد خود ادامه دهند و اینطور میتوانیم مطمئن شویم دادهها از دست نمیروند.
با توزیع بار بین چندین سرور، عملکرد کلی سیستم بهبود مییابد.
این ویژگی به سازمانها اجازه میدهد که به سرعت و به طور مؤثر به نیازهای در حال تغییر با اضافخ کردن به خوشه ی دیتابیس ها پاسخ دهند.
Cloud Scaling
در دنیای فناوری ابری، Cloud Scaling یا مقیاسپذیری ابری به مفهوم افزایش یا کاهش منابع برای تطابق با نیازهای متغیر است.
انواع Cloud Scaling
1. Vertical Scaling: در این روش، منابع سیستم، مانند حافظه (RAM) و پردازنده (CPU)، به یک سرور واحد اضافه یا از آن کم میشوند.
2. Horizontal Scaling: در این روش، به جای افزایش منابع یک سرور، سرورهای بیشتری به سیستم اضافه میشود.
3. Diagonal Scaling: این روش ترکیبی از مقیاسپذیری عمودی و افقی است.
Materialized View
Materialized View یکی از روشهای کارآمد در دیتابیس برای افزایش کارایی و مقیاسپذیری در دسترسی به دادهها است. در این روش، نتایج یک Query پیچیده و سنگین به صورت ایستا ذخیره میشوند تا در دسترسیهای بعدی به سرعت از آنها استفاده شود. تفاوت آن با View معمولی در این است که در View معمولی هر بار که به دادهها دسترسی پیدا میکنید، Query اجرا میشود. اما در Materialized View، نتایج قبلاً محاسبه و ذخیره شده و بهسرعت قابل بازیابی هستند.
در Queryهای پیچیده که نیاز به محاسبات سنگین دارند، مانند گزارشات تحلیلی و جداول بزرگ، استفاده از Materialized View باعث افزایش سرعت دسترسی به نتایج میشود.
وقتی تصمیم به استفاده از Materialized View بگیرید یکی از مهمترین سوال هایی که باید پاسخ دهید این است که به روزرسانی داده های ذخیره شده در Materialized View را چه کنم؟
در نتیجه یکی از چالشهای استفاده از Materialized View، بهروز نگهداشتن دادهها است. در دیتابیس، دادهها همواره در حال تغییر هستند و Materialized Viewها بهطور پیشفرض بهروزرسانی نمیشوند. بنابراین باید راهی برای بهروزرسانی دورهای یا خودکار Materialized View فراهم شود.
روشهای بهروزرسانی:
- Refresh on Demand: در این روش، تنها زمانی که نیاز به بهروزرسانی دارید، میتوانید با دستور REFRESH آن را بهروز کنید.
REFRESH MATERIALIZED VIEW view_name;- Refresh Automatically (بهروزرسانی زمانبندیشده): در برخی سیستمها میتوانید Materialized View را طوری تنظیم کنید که بهصورت خودکار در زمانهای خاصی بهروزرسانی شود. برای مثال در PostgreSQL، میتوانید یک Job یا Task زمانبندیشده برای بهروزرسانی منظم Materialized View تعریف کنید.
Indexing
Indexing یکی از روشهای کلیدی برای بهبود عملکرد دیتابیس است و نقش مهمی در سرعت بخشیدن به Queryها و دستیابی به دادهها ایفا میکند.
Indexing به معنی ایجاد یک ساختار دادهای اضافی در پایگاهداده است که به سیستم کمک میکند تا با سرعت بیشتری دادهها را جستوجو و بازیابی کند. بهعبارت دیگر، Index مانند یک فهرست در یک کتاب عمل میکند و باعث میشود بهجای جستوجوی کل صفحات، بهسرعت به صفحهی موردنظر دسترسی پیدا کنید.
بدون Index، هر Query باید کل جدول را اسکن کند تا نتیجه را بیابد (Full Table Scan)، اما با استفاده از Index، سیستم میتواند مستقیماً به دادههای هدف برسد، که باعث صرفهجویی در زمان و منابع میشود.
ویژگی های Indexing
با استفاده از Index، دسترسی به دادهها سریعتر میشود و Queryها بهینهتر اجرا میشوند. به دلیل حذف نیاز به Full Table Scan، ایندکس ها بار پردازشی پایگاهداده را کاهش میدهند. و در جدول های بزرگ، Indexing میتواند به مقیاسپذیری بیشتر و بهینهتر کمک کند.
یکی از اصلی ترین معایب Indexing این است که ایجاد Indexها نیاز به فضای اضافی دارد. و هر بار که دادهها درج یا بهروزرسانی میشوند، باید Indexها نیز بهروز شوند، که باعث کند شدن عملیات نوشتن در دیتابیس میشود. و البته ایجاد Indexهای زیاد و نامناسب میتواند به جای بهبود کارایی، باعث کاهش عملکرد پایگاهداده شود.
Denormalization
Denormalization یکی از تکنیکهای بهینهسازی دیتابیس است که به ویژه در راستای افزایش سرعت و کارایی دیتابیس در مقیاسهای بزرگ استفاده میشود.
در طراحی دیتابیس، نرمالسازی یا Normalization به معنای سازماندهی دادهها در جدول هایی بهصورت بهینه برای جلوگیری از تکرار و افزونگی است. اما Denormalization برخلاف نرمالسازی عمل میکند و دادهها را بهصورت تکراری یا Redundant ذخیره میکند تا سرعت دسترسی به آنها افزایش یابد. این روش اغلب در سیستمهایی با Queryهای سنگین و نیازمند به سرعت بالا استفاده میشود.
بهطور خلاصه، Denormalization به معنی افزودن دادههای تکراری به پایگاهداده است تا نیاز به JOIN کمتر شود و در نتیجه عملکرد Queryها بهبود یابد.
Database Scaling یک جنبه حیاتی از طراحی و مدیریت سیستمهای اطلاعاتی است. با درک روشهای مختلف Scaling مانند:
- Vertical Scaling
- Horizontal Scaling
- Partitioning
- Replication
- Database Clustering
- Cloud Scaling
- Materialized Views
- Indexing
- Denormalization
توسعهدهندگان و معماران سیستم میتوانند تصمیمات آگاهانهای در مورد بهینهسازی دیتابیس های خود بگیرند. با استفاده از این تکنیکها، سازمانها میتوانند اطمینان حاصل کنند که دیتابیس های آنها قادر به مدیریت بارهای افزایشیافته و ارائه عملکرد قابل اعتماد هستند.