
در این چند سال اخیر، سوال هایی در مورد تفاوت بین Sql و NoSql ذهن بسیاری از توسعه دهندگان را به خود مشغول کرده است. تعریف دقیق Sql و NoSql چیست؟ پایگاه دادههای NoSql مانند MongoDb با پایگاه داده های Sql مانند MySql چه تفاوتی با هم دارند؟ چه زمانی باید از پایگاه داده های NoSql استفاده کرد و چه زمانی از پایگاه داده های Sql ؟ در این نوشتار قصد داریم به این سوال ها جواب بدهیم. بنابراین ابتدا با دنیای Sql و سپس با دنیای NoSql ها آشنا می شویم و در نهایت این دو دنیا را با هم مقایسه خواهیم کرد.
💎 برای درک هرچه بهتر مطالب ارائه شده لازم است اطلاعات عمومی دربارهی پایگاه داده داشته باشید.
SQL چیست ؟
گاهی برخی توسعه دهندگان در جواب این سوال که پایگاه داده ی استفاده شده در برنامهتان چه چیزی است، جواب خواهند داد Sql! در واقع این جواب درستی نیست چون Sql یک پایگاه داده ی خاص نیست. Sql یک زبان است که از طریق این زبان می توان با پایگاه داده تعامل کرد یعنی داده های موجود در آن را خواند، داده هایی به پایگاه داده اضافه کرد و یا داده های آن را دستکاری و تغییر داد. این تعامل در قالب پرس و جویی هایی ساخت یافته و منسجم که داده ها را توصیف می کند، انجام می گیرد.
به همین دلیل است که به آن، زبان پرس و جوی ساخت یافته یا Structured Query Language گفته می شود. فرض کنید پایگاه داده ای داریم برای نگه داری داده های دانشگاه و در آن جدولی وجود دارد که داده های دانشجویان را نگه می دارد. اگر بخواهیم شماره دانشجویی، نام و سن دانشجویان را از آن استخراج کنیم باید این کوئری یا پرس و جوی زیر را روی این پایگاه داده اجرا کنیم.
SELECT Id , name , age FROM studentsزبان Sql دارای کلمات کلیدی خاصی است. درکوئری بالا، کلمات کلیدی SELECT برای تعیین فیلدهای جدول و FROM برای مشخص کردن جدولی که می خواهیم داده هایش را بخوانیم به کار برده شده اند. هم چنین در کنار کلمات کلیدی منابع داده ای مانند اسم جداول و اسم فیلد ها، که به عنوان پارامتر به کوئری ها فرستاده می شوند، باید مشخص شوند.
کوئری بالا برای واکشی داده ها از جداول پایگاه داده نوشته شده است. برای سایر اعمالی که روی داده ها قابل انجام است مانند بروزرسانی داده ها، حذف داده ها و درج داده های جدید، کلمات کلیدی دیگری در این زبان تعبیه شده است. هم چنین برای جمع آوری داده ها از جداول مختلف که با هم در ارتباط هستند، کلمه کلیدی join وجود دارد و برای ایجاد اشیای پایگاه داده ها مانند View ها ، Function ها و . . . کلمات کلیدی دیگری وجود دارند.
همان طور که گفته شد این زبان برای تعامل با پایگاه داده ها کاربرد دارد. اما سوالی که این جا ممکن است مطرح بشود این است که با چه نوع پایگاه داده ای می توان با کمک این زبان کار کرد. زبان Sql، زبان تعامل با پایگاه داده های رابطه ای است. در ادامه با پایگاه داده های رابطه ای آشنا می شویم.
تعریف پایگاه داده های رابطه ای یا Relational Databases
در این نوع پایگاه داده ها ، داده ها در ساختاری مرتب و مشخص باید ذخیره شوند. این ساختار نظام مند، از طریق مفهومی به نام جدول شکل می گیرد . در مثال پایگاه داده ی دانشگاه، داده های مربوط به دانشجویان را در جدولی به نام students نگه داری می کنیم. جداول پایگاه داده های رابطه ای را مانند یک مخزنی فرض کنید، که قرار است داده هایی مشخص و با ساختاری مرتب و از قبل تعیین شده را در خود نگه داری کنند. به این ساختار مشخص، شِما (schema) گفته می شود. از طریق شِمای جدول، محدودیت هایی در نوع و ساختار داده های جدول ایجاد می کنیم.
این محدودیت ها در ساختار یک جدول به کمک مفهوم دیگری به نام فیلد (field) پیاده سازی می شوند. مثلا جدول دانشجویان می تواند شامل فیلد های شماره دانشجویی، نام و سن باشد (برای سادگی تنها این سه فیلد را در نظر می گیریم). هر یک از این فیلد ها دارای نوع داده ی خاصی است. مثلا فیلد نام از نوع رشته و فیلد سن از نوع عددی خواهد بود. روی هر یک از این فیلدها امکان تعریف محدودیت های دیگری هم وجود دارد. مثلا داده های فیلد شماره دانشجویی باید همیشه یکتا باشند.
داده ها در جداول پایگاه داده ها، در قالب سطر ها یا رکورد ها درج می شوند. هر گاه بخواهیم رکوردی را در جدولی درج کنیم باید براساس شِمای آن عمل کنیم به این معنی که تمام محدودیت هایی که روی فیلد های آن تعریف شده است، رعایت کنیم. به علاوه این که، به جز فیلد هایی که برای جدول تعریف شده اند، نمی توان داده ی اضافه تری در جدول قرار داد. مثلا امکان پذیر نیست که رکوردی درج کرد که محل تولد دانشجو را هم داشته باشد چون فیلدی به نام محل تولد در شِمای جدول دانشجویان وجود ندارد. در نتیجه همه ی داده های یک جدول، ساختاری مشخص و با تعداد فیلد های مشخصی خواهند داشت.
جدول زیر جدول دانشجویان را نشان می دهد که دارای 3 فیلد یا ستون و 2 رکورد یا سطر می باشد . همان طور که می بینید هر یک از سطر ها دارای شِمای مشخصی هستند یعنی دارای تعداد فیلد های مشخص با نوع داده ی مشخصی هستند.
age | name | Id |
21 | علی | 1 |
22 | احمد | 2 |
21 | رضا | 3 |
مزیتی که داشتن schema دارد این است که وقتی قصد خواندن داده یا نوشتن داده روی جدول را داریم با یک ساختار مشخص رو به رو هستیم.
مواردی که تا این جا گفته شد، مربوط به یک جدول یکتا بود. در بیشتر موارد با چند جدول رو به رو هستید که ارتباط معنا داری با هم دارند. فرض کنید علاوه بر اطلاعات دانشجو که در جدول دانشجویان ذخیره شد، اطلاعات دروسی که در دانشگاه ارائه می شوند در جدول دیگری به نام دروس ذخیره می شود. در جریان انتخاب دروس توسط دانشجویان اطلاعاتی شکل می گیرد که کدام دانشجو کدام درس را انتخاب کرده است. در واقع این دو جدول با هم در ارتباط هستند. این اطلاعات در جدول دیگری ذخیره می شود و چون ارتباط بین موجودیت های دانشجو و درس، ارتباط انتخاب درس است، پس اسم آن را انتخاب رشته می گذاریم یعنی دانشجو درس را انتخاب می کند و درس هم توسط دانشجو انتخاب می شود. پس تا این جا سه جدول داریم که با هم در ارتباط هستند.
age | name | StudendId |
21 | علی | 1 |
22 | احمد | 2 |
21 | رضا | 3 |
name | CourseId |
Java | 1 |
#C | 2 |
CourseId | StudendId | Id |
1 | 1 | 1 |
2 | 1 | 2 |
1 | 2 | 3 |
در این نوشتار قصد نداریم وارد جزئیات طراحی جداول شویم اما تنها به این نکته باید اشاره کرد که یکی از دلایل جدا کردن این جداول از هم، جلوگیری از درج اطلاعات تکراری است و گرنه می توانستیم کل داده های این سه جدول را در یک جدول قرار دهیم که هر رکورد آن شامل کل اطلاعات دانشجو و درس خواهد بود. اما طراحی بهتر این است که اطلاعات دانشجو و درس در جاهای مختلفی قرار بگیرند و با شناسه آن ها که مقدار یکتایی دارد کار کنیم.
در ادامه انواع روابطی که در پایگاه داده های رابطه ای استفاده می شوند را توضیح می دهیم.
انواع رابطه در پایگاه داده های رابطه ای
1. رابطه ی چند به چند
رابطه ای که در بخش قبل دیدیم رابطه ای از نوع چند به چند یا many to many بود. در این نوع رابطه، هر رکورد از طرفین رابطه (جداول) می توانند با چندین رکورد از جدول مقابل در ارتباط باشند یعنی یک دانشجو می تواند چند درس را انتخاب کند و یک درس هم می تواند توسط چند دانشجو انتخاب شود. برای پیاده سازی این نوع رابطه از جدولی میانی استفاده می کنیم که کلید های جداولی که در ارتباط شرکت می کنند را در آن قرار می دهیم یعنی StudendId و CourseId.
2. رابطه ی یک به یک
فرض کنید می خواهیم اطلاعات تماس دانشجویان را در جدولی جداگانه ذخیره کنیم پس باید ارتباطی بین دو جدول دانشجو و اطلاعات تماس وجود داشته باشد. پس جدول زیر را تعریف می کنیم و اسم آن را جدول اطلاعات تماس می گذاریم.
StudendId | tel | ContactId | |
1 | abc@yahoo.com | 5540 | 1 |
2 | efg@yahoo.com | 1422 | 2 |
3 | hig@gmail.com | 9635 | 3 |
همان طور که مشاهده می کنید ، در این ارتباط هر دانشجو فقط با یک رکورد از جدول تماس در ارتباط است و هر یک از رکورد های جدول تماس هم مختص به یک دانشجو است پس بین این جدول ارتباطی از نوع یک به یک یا one to one شکل می گیرد . ذکر این نکته هم لازم است که چون ارتباط بین این دو جدول از نوع یک به یک است، تفاوتی نمی کند که کلید جدول تماس را در جدول دانشجو قرار دهیم یا بر عکس ولی حتما باید مقدار یکتا در آن ستون درج شود که این کار را از طریق Unique Constraint ها انجام می دهیم. در این مثال کلید جدول دانشجو را در جدول تماس قرار داده ایم.
3. رابطه ی یک به چند
جدول دیگری تعریف می کنیم و می خواهیم اطلاعات اساتید دانشگاه را در آن نگه داری کنیم. اسم این جدول را جدول اساتید می گذاریم.
name | TeacherId |
محمد | 1 |
پدرام | 2 |
در جدول دروس قصد داریم بفهمیم که درس ها توسط چه استادی تدریس می شود. پس یک ستون به آن اضافه کرده و کد استاد درس را در آن قرار می دهیم. پس خواهیم داشت.
TeacherId | Name | CourseId |
1 | Java | 1 |
2 | #C | 2 |
از جدول بالا متوجه می شویم که هر درس توسط چه استادی تدریس می شود. ارتباط بین دو جدول درس و استاد ارتباطی از نوع یک به چند یا one to many است یعنی هر رکورد از جدول درس تنها با یک رکورد از جدول استاد ارتباط دارد ولی هر استاد می تواند چند درس را تدریس کند.
همان طور که می بینید بین جداول یک پایگاه داده ی رابطه ای روابط مختلفی وجود دارد و به همین دلیل است که به این نوع پایگاه داده ها، پایگاه داده های رابطه ای گفته می شود چون داده ها در جداول آن ها پخش می شوند و این جداول با هم در ارتباط هستند. رابطه ی زبان Sql با پایگاه داده های رابطه ای به این صورت است که Sql زبانی است که از طریق آن می توان با توصیف داده های مورد نیاز، جداول مختلف را به هم پیوند یا join کرد و داده ها را از جداول مختلف واکشی کرد.
NoSQL چیست؟
تا این جای کار با دو مشخصه ی بسیار مهم پایگاه داده های رابطه ای آشنا شدیم. دیدیم که جداول این نوع پایگاه داده ها دارای schema (شِما) یا شما هستند که قالب داده هایی که قرار است ذخیره کنند را مشخص می کنند و هم چنین دیدیم که داده ها در جداول مختلفی ذخیره شده و جداول ارتباط منطقی با هم دیگر دارند. اما دنیای NoSql ها با این نوع پایگاه داده ها متفاوت است. در NoSql ها خبری از جداول و رابطه ی بین آن ها نیست و تفاوت های بنیادی با پایگاه داده های رابطه ای دارند.
قصد دارم این تفاوت ها را با یکی از معروف ترین پایگاه داده های NoSql، یعنی MongoDB توضیح دهم. مونگو دی بی یک سیستم مدیریت پایگاه داده یا Database Management System است که به دلیل انعطاف پذیری و قابلیت گسترش پذیری بالایش، محبوبیت فراوانی پیدا کرده است. در ادامه به بررسی خصوصیات مونگو دی بی به عنوان یک NoSql خواهیم پرداخت.
ساختار MongoDB
در مونگو دی بی مانند پایگاه داده های رابطه ای، مفهوم database یا پایگاه داده که مجموعه ای از داده ها است، وجود دارد اما در مونگو دی بی مفهوم جدول وجود ندارد و مفهوم معادل آن در مونگو دی بی، Collection یا مجموعه است. مثلا پایگاه داده ی دانشگاه را در نظر بگیرید و داخل آن دو مجموعه به نام های دانشجویان و دروس را تعریف می کنیم.
داخل مجموعه ها، داده ها قرار می گیرند. بر خلاف پایگاه داده های رابطه ای که داده ها در سطر هایی از جداول قرار می گیرند، در مونگو دی بی مفهومی به اسم سطر یا رکورد وجود ندارد . به جای مفهموم سطر، مفهوم دیگری وجود دارد به نام سند یا Document. پایگاه داده های NoSql در طبقه بندی های مختلفی قرار می گیرند که یکی از آن ها پایگاه داده ی Document Base یا سند گرا می باشد. مونگو دی بی یک نوع پایگاه داده ی سند گرا است و به همین دلیل است که داده ها در اسناد ذخیره خواهند شد. (برای آشنایی بهتر می توانید به مقاله آشنایی با انواع دیتابیس های NoSQL مراجعه کنید) فرمت وارد کردن داده ها در سند ها به صورت json است. مثلا مجموعه ی دانشجویان می تواند شامل این سه سند باشد.
{ id : 1 , name : ‘ali’ , age : 21 }{ id : 2 , name : ‘ahmad’ , age : 22 }{ id : 3 , name : ‘reza’ , age : 21 }پس تا این جای کار ساختار کلی ذخیره کردن داده ها در مونگو دی بی به این شکل خواهد بود.
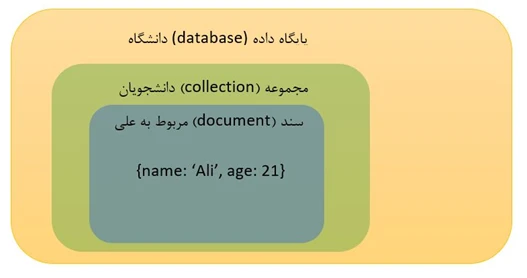
Schema و Relation در NoSql
همان طور که قبلا گفته شد ، جداول در پایگاه داده های رابطه ای، دارای schema یا شمای خاصی هستند که محدودیت هایی را روی داده هایی که قرار است در جداول درج بشوند، اعمال می کنند. اما در پایگاه داده های NoSql، شمایی وجود ندارند و در وارد کردن داده ها به هر نحوی آزاد هستید. در مونگو دی بی، اسنادی که در یک مجموعه وارد می کنید از یک شمای خاصی نیستند و می توانند هر شکل و فرمتی داشته باشند. مثلا یکی از اسناد مجموعه ی دانشجو می تواند فیلدی به نام جنسیت داشته باشد ولی سایر اسناد مجموعه ی دانشجو فیلد جنسیت را نداشته باشند و در کل شکل اسناد مجموعه شباهتی با هم نداشته باشند. البته این به معنی null بودن آن فیلد خاص نیست بلکه به این معناست که آن سند، فیلدی به نام جنسیت ندارد و با مفهوم null بودن یک فیلد که در پایگاه داده های رابطه ای وجود دارد ، متفاوت است. نداشتن شما روی اسناد یک مجموعه، انعطاف پذیری خاصی به ما می دهد که در شرایط مختلف، داده هایی با اشکال متفاوت را داخل مجموعه ها ذخیره کنیم.
به طور کلی در NoSql ها مفهوم رابطه وجود ندارد .NoSql ها برخلاف پایگاه داده های رابطه ای که کلید خارجی را برای ایجاد ارتباط معرفی کرده است، روشی برای ایجاد ارتباط بین مجموعه ها در اختیار ما قرار نمی دهند و راهکارشان برای ارتباط بر قرار کردن بین مجموعه ها به این صورت است که به جای ایجاد کلید خارجی، کل داده های سند را در سند دیگری کپی کنیم. مثلا فرض کنید سند هایی برای دانشجو و درس به شکل زیر داریم.
{ id : 1 , name : ‘ali’ , age : 21 }{ id : 2 , name : ‘reza’ , age : 22 }{ id : 1 , name : ‘C#’ }{ id : 2 , name : ‘java’ }می خواهیم ارتباط انتخاب رشته را بین دو مجموعه دانشجو و درس ایجاد کنیم. سندی می سازیم و به جای ذخیره کردن کلید دانشجو و درس در آن، اطلاعات آن ها را در خود سند می آوریم. به این شکل:
{ id : 1 , student : { id : 1 , name : ‘ali’ } , course : { id : 1 , name : ‘C#’ } }{ id : 2 , student : { id : 2 , name : ‘reza’ } , course : { id : 2 , name : ‘java’ } }{ id : 3 , student : { id : 1 , name : ‘ali’ } , course : { id : 1 , name : ‘C#’ } }به این نکته توجه کنید که اطلاعات کامل مجموعه ها، در خود آن مجموعه نگه داری می شود و لازم نیست همه ی فیلد های آن مجموعه را در مجموعه ی ارتباط دانشجو و درس بیاوریم. مثلا در این جا تنها به فیلد شناسه و نام دانشجو نیاز داشتیم و فیلد سن آن را نیاوردیم.
مزایا و معایب نگه داری داده ها در مجموعه ها (Collections)
به حداقل رساندن join و ادغام (merge) کردن داده ی بین مجموعه های مختلف، ایده ی پشت این طراحی است. این طراحی با خود سرعت بسیار بالای پرس و جو (query) و هم چنین کارآمد بودن پرس و جو ها را به ارمغان می آورد چون داده ها در یک مجموعه جمع شده اند و نیازی به join کردن مجموعه ها نیست. یکی از معایبی که این روش دارد این است که افزونگی داده ای در آن زیاد است. در مثال ما اطلاعات دانشجو در مجموعه ی دانشجو ذخیره شده است و تقریبا همان اطلاعات در اسناد مربوط به مجموعه ی انتخاب رشته هم آورده شده است. مشکل دیگر این طراحی آن است که بروز رسانی در جاهای مختلفی باید انجام شود مثلا اگر نام یک دانشجو در مجموعه خودش عوض شود، مجبور هستیم نام دانشجو را در مجموعه ی انتخاب رشته هم عوض کنیم. این طراحی زمانی که تعداد خواندن ها (reads) از نوشتن ها (writes) بیشتر باشد روش کارآمدی خواهد بود.
مقایسه SQL با NoSQL
سوالی که خیلی از توسعه دهندگان می پرسند این است که چه زمانی باید از پایگاه داده های Sql استفاده کرد و چه زمانی از پایگاه داده های NoSql ؟ جواب این سوال در بسیاری از مواقع، بستگی به برنامه ای دارد که در حال توسعه ی آن هستید و یا بستگی به داده ای دارد که می خواهید ذخیره کنید. به طور مثال در یک برنامه ای با مقیاس بالا مانند برنامه های سازمانی یا Enterprise، با انواع برنامه ها، کسب و کار های فراوان و داده های گوناگون رو به رو هستیم، در نتیجه روش بهتر این است که بر اساس نیاز مان از ترکیب بین این دو نوع پایگاه داده استفاده کنیم. در ادامه به برخی از تفاوت های بین دنیای Sql با NoSql از منظر های مختلف خواهیم پرداخت.
تفاوت SQL با NoSQL از منظر داشتن Schema
دنیای Sql | دنیای NoSql |
در این دنیا داده ها دارای ساختار مشخصی هستند یعنی schema دارند.
مزایا: شکل داده ها از قبل مشخص است و می توان براساس شمای داده ها برنامه ریزی کرد.
معایب: انعطاف پذیری در شکل و نوع داده را نخواهیم داشت. | این دنیا بدون ساختار یا schema less است.
مزایا: داده ها اشکال مختلفی دارند و انعطاف پذیر زیادی دارند.
معایب: به دلیل متغییر بودن نوع و شکل داده ها، نمی توان به ساختار داده ها در کد متکی بود. |
تفاوت SQL با NoSQL از منظر داشتن Relation
دنیای Sql | دنیای NoSql |
داده ها در این دنیا دارای ارتباط معنایی یا Relation با هم هستند.
مزایا : به دلیل ذخیره کردن داده ها در یک جدول خاص، افزونگی داده ای (تکرار داده) نخواهیم داشت. تعداد به روز رسانی داده ای، به دلیل مشخص بودن مکان داده، کم خواهد بود و در نتیجه برای جاهایی که تعداد نوشتن و بروز رسانی زیاد است مناسب ترند.
معایب: پرس و جو ها سخت تر و سرعت شان کم تر است چون داده ها در جاهای مختلف پخش هستند و باید با هم تجمیع یا Merge شوند، در نتیجه برای شرایطی که تعداد خواندن ها زیاد است، کارایی NoSql ها بهتر هستند.
| در این دنیا داده ها حداقل ارتباط را با هم دارند و در بسیاری از موارد هیچ ارتباطی با هم ندارند و داده ها در مجموعه های مختلف از قبل merge خواهند شد.
مزایا : چون عملیات join و ادغام کردن داده را نخواهیم داشت، خواندن از آن ها با سرعت بالا انجام می گیرد.
معایب: به دلیل تکرار داده ها در مجموعه های مختلف و بروز رسانی داده در همه ی آن ها، عملیات نوشتن کند خواهد بود. |
تفاوت SQL با NoSQL از منظر Scalability یا مقیاس پذیری
دنیای Sql | دنیای NoSql |
در این دنیا horizontal scaling یا مقیاس پذیری افقی در بیشتر موارد غیر ممکن است و در موارد خاصی با سختی انجام می گیرد. اما Vertical scaling یا مقیاس پذیری عمودی در این پایگاه داده ها قابل انجام است. | در این دنیا horizontal scaling یا مقیاس پذیری افقی و هم چنین Vertical scaling یا مقیاس پذیری عمودی در این پایگاه داده ها قابل انجام است. یکی از دلایلی که مقیاس پذیری عمودی را در این نوع پایگاه داده ها آسان می کند نداشتن ارتباط بین داده ها ست. |
* * horizontal scaling یا مقیاس پذیری افقی به این معنی است که تعداد سرور ها را افزایش دهیم و پایگاه داده را بین این سرور ها پخش کنیم.
** scaling Verticalیا مقیاس پذیری عمودی به معنی افزایش توان سخت افزاری سرور است. در این نوع سیستم ها پایگاه داده تنها روی یک سرور قرار می گیرد و سخت افزار این سرور را ارتقا خواهیم داد.
تفاوت SQL با NoSQL از منظر سرعت و تعداد خواندن و نوشتن
دنیای Sql | دنیای NoSql |
در دنیای sql اگر پرس و جو هایی پیچیده داشته باشیم (یعنی تعدادی join در آن ها به کار برده شده باشد) سرعت خواندن و نوشتن و تعداد انجام آن در ثانیه کم خواهد شد. | پایگاه داده هایی از نوع NoSql عملیات خواندن و نوشتن داده ها را با سرعت بسیار بالا انجام می دهند. البته اگر عملیات بروز رسانی را در چند مجموعه انجام دهند سرعت انجام آن پایین خواهد آمد. |
تفاوت SQL با NoSQL از منظر پخش بودن داده ها
دنیای Sql | دنیای NoSql |
در این دنیا به دلیل طراحی شان داده ها در جداول مختلف پخش شده و زمانی که به داده ها نیاز داشته باشیم با هم دیگر ادغام یا join خواهند شد. | در این دنیا سعی می شود از پخش شدن داده ها جلوگیری شود و داده ها از قبل در مجموعه ها ادغام می شوند تا عملیات خواندن با سرعت بیشتری انجام شوند. |
جمع بندی: SQL یا NoSQL؟ کدام مناسب تر است؟
در انتها قصد داریم به این سوال پاسخ دهیم که برای برنامه هایمان چه زمانی باید از پایگاه داده های NoSql استفاده کنیم و یا چه زمانی نباید استفاده کنیم؟ در حالت کلی هر نوع برنامه ای را می توان با هر یک از این انواع پایگاه داده توسعه داد و قاعده ای کلی وجود ندارد که دقیقا تعیین کند که از چه نوعی باید استفاده کنید. بر اساس نیازمندی های برنامه ای که در حال توسعه آن هستید، نوع پایگاه داده متفاوت خواهد بود. به عنوان مثال در برنامه های سازمانی که با تنوعی از نیازمندی ها رو برو هستیم، از هر دو نوع پایگاه داده استفاده خواهد شد. اگر قالب داده هایتان از قبل مشخص باشد و یا اگر داده هایتان رابطه های زیادی با هم داشته باشند و یا اگر نرخ تغییر داده هایتان زیاد است بهتر از پایگاه داده های Sql ای استفاده کنید چون مدیریت داده هایتان راحت تر خواهد بود. اگر با برنامههایی مواجه هستید که تعداد خواندن داده ها در آن زیاد است، توصیه میشود از پایگاه داده های NoSql ای استفاده کنید.