چنانچه وب اپلیکیشنی با اقبال عمومی مواجه شده و رشد قابلتوجهی داشته باشد و مخاطبین بسیاری را به سمت خود جذب کند، زیرساخت آن باید به گونهای باشد که توانایی هندل کردن میلیونها ریکئوست در هر ثانیه را داشته باشد مضاف بر اینکه برای ذخیرهسازی دادهها نیز باید سازوکاری اندیشید که پایگاه داده به صورت دینامیک و بسته به نیازهای آن وب اپلیکیشن اصطلاحاً Scale شود و اینجا است که پای معماری Database Sharding به میان میآید.
Shard در لغت به معنی «تکه» است و Sharding نیز یک الگوی طراحی دیتابیس است که در آن دادهها در قالب چندین و چند جدول و دیتابیس مختلف تقسیمبندی میشوند و همین مسئله منجر بدان خواهد شد که مدیریت ریکوئستهای زیاد راحتتر گردد.
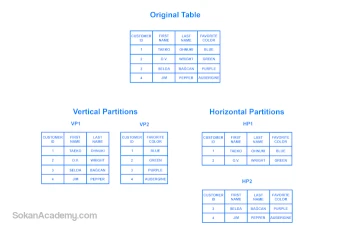
آشنایی با تفاوتهای پارتیشنبندی Horizontal و Vertical
این دو واژه به ترتیب به معنی «افقی» و «عمودی» است. پارتیشنبندی افقی (Horizontal Partitioning) به این موضوع اشاره دارد که رکوردهای ثبتشده در یک جدول را از یکدیگر جدا ساخته و هر گروه را در یک جدول که در اینجا تحت عنوان پارتیشن شناخته میشود ذخیره میسازند و این در حالی است که هر جدول (پارتیشن) از اِسکما و ستونهای دقیقاً مشابهی برخوردار است اما دادههای ذخیرهشده در آنها متفاوت و در عین حال منحصربهفرد هستند؛ به عبارتی، هیچ جدولی حاوی دادههای یکسان نخواهد بود.
در پارتیشنبندی عمودی (Vertical Partitioning) یکسری ستون خاص در یک جدول و یکسری ستون خاص دیگر در جدولی دیگر طراحی میشود و دادههای ذخیرهشده در این دست جداول نیز منحصربهفرد هستند؛ به عبارتی، هیچ دو جدول (پارتیشن) را نمیتوان یافت که حاوی ساختار و دادههای یکسانی باشد.
در پاسخ به این پرسش که «تفاوت مابین پارتیشنبندی افقی و پارتیشنبندی عمودی چیست؟» میتوان گفت که در پارتیشنبندی افقی فقط دادههای جداول منحصربهفرد هستند در حالی که در پارتیشنبندی عمودی علاوه بر دادهها، ستونهای جداول نیز با یکدیگر فرق دارند. همانطور که در تصویر فوق ملاحظه میشود، یک جدول داریم تحت عنوان Original Table که وقتی آن را به صورت افقی پارتیشنبندی کنیم دو جدول تحت عناوین HP1 و HP2 خواهیم داشت که در هر دوی آنها اِسکما (ساختار) دیتابیس یکسان است اما هر کدام حاوی دادههای متفاوتی است اما زمانی که این جدول را به صورت عمودی پارتیشنبندی میکنیم، دو جدول خواهیم داشت تحت عناوین VP1 و VP2 که اِسکمای آنها با یکدیگر فرق داشته مضاف بر اینکه هر کدام از آنها مسئول ذخیرهسازی دادهٔ خاصی است.
با این توضیحات میتوان گفت که Sharding به پروسهٔ شکستن دادهها به واحدهای کوچکی که هر کدام در جدول خاصی ذخیره میشوند گفته میشود که با کنار هم قرار گرفتن تکتک جداول و دادهها در کنار یکدیگر، به یک دیتابیس کامل دست خواهیم یافت.
Sharding گاهی اوقات در سطح اپلیکیشن صورت میگیرد بدان معنا که فانکشنهایی توسط دولوپر نوشته میشود که مشخص میسازند ارتباط اپلیکیشن با دیتابیس برای فرآیندهای خواندن و نوشتن دیتا به چه صورت باشد اما در عین حال برخی سیستمهای مدیریت دیتابیس هستند که به صورت پیشفرض قابلیت Sharding را دارند و این کار در سطح دیتابیس صورت میگیرد.
آشنایی با مزایای Sharding
یکی از کلیدیترین مزایای Sharding آن است که امکانی را در اختیار توسعهدهندگان میگذارد تا بتوانند دست به توسعهٔ افقی (Horizontal Scaling) بزنند بدان معنا که به منظور پخش کردن بار روی سرورها و بالتبع افزایش سرعت پردازش دادهها، از مجموع چندین و چندین دیتابیس مختلف استفاده میشود. این نوع معماری نقطهٔ مقابل توسعهٔ عمودی (Vertical Scaling) قرار دارد که در آن تیم دوآپس به افزایش قدرت سختافزاری همچون ارتقاء رَم و سیپییو میپردازد تا بتواند در آنِ واحد تعداد ریکوئستهای بیشتری را با حفظ پرفورمنس هندل کند.
اساساً وقتی پای توسعهٔ عمودی به میان میآید، به راحتی میتوان زیرساخت سختافزاری را دائماً ارتقاء داد تا با رشد تعداد کاربران، سرور نیز بتواند به همان میزان پاسخگوی نیاز ایشان باشد اما به خاطر داشته باشیم که این کار نهایتاً تا یک جایی امکانپذیر است مضاف بر اینکه کاری هزینهبر است!
زمانی که به یک دیتابیس با معماری معمولی کوئری میزنیم، اگر در یک جدول خاص میلیونها رکورد ثبت شده باشد، حتی اگر ایندکسگذاری اصولی هم صورت گرفته باشد، ریسپانس تایم خیلی سریع نخواهد بود اما این در حالی است که با Sharding یک جدول به چندین جدول مجزا، کوئری ما میبایست در میان تعداد رکوردهای کمتری را سرچ شود و بالتبع سرعت فراخوانی دادهها بالا میرود.
همچنین Sharding این تضمین را ایجاد میکند که در حین دَونتایم و به طور کلی زمانهایی که مشکلی برای سرور رخ میدهد، اپلیکیشن پایدارتر باشد. برای درک بهتر این موضوع، فرض کنیم وب اپلیکیشنی داریم که مبتنی بر یک دیتابیس معمولی (Unsharded Database) است که در چنین شرایطی رخداد مشکل برای سرور دیتابیس منجر بدان خواهد شد که کل اپلیکیشن از دسترس خارج گردد اما این در حالی است که با برخورداری از یک Sharded Database احتمال آنکه مشکل فقط یک Shard را از کار بیندازد بیشتر است که این مسلماً باعث پایداری بیشتر اپلیکیشن خواهد شد و فقط بخشهایی از اپلیکیشن به طور موقت از کار خواهند افتاد.
آشنایی با معایب Sharding
گرچه این معماری باعث بهبود پایداری و پرفورمنس اپلیکیشن میگردد، اما فراموش نکنیم که معایبی نیز دارا است که شاید به عنوان اولین آنها بتوان به پیچیدگی این دست دیتابیسها اشاره کرد. در واقع، اگر پروسهٔ Sharding به درستی صورت نگیرد، امکان تداخل دادهها، از دست دادن آنها و جداولی معیوب بسیار بالا خواهد رفت!
یکی دیگر از مشکلات مرتبط با Sharding آن است که احتمال دارد تا تعادل مابین پارتیشنهای مختلف از بین برود. به منظور درک بهتر این موضوع، فرض کنیم دو جدول داریم که در یکی از آنها اسامی کاربرانی که نامشان با حروف «الف» تا «س» شروع میشود را ذخیره میکنیم و در دیگری دیتای کاربرانی که نامشان با حروف «ش» تا «ی» آغاز میگردد اما این در حالی است که مثلاً کاربرانی که اسم آنها با حرف «ب» شروع میشود به مراتب بیش از سایر حروف الفبا است که در چنین شرایطی جدولی که مسئول ذخیرهسازی حروف «الف» تا «س» است بسیار حجیم شده و بالتبع فراخوانی دادهها برای حجم قابلتوجهی از کاربران کُند خواهد شد.
نقطه ضعف دیگر آن است که وقتی دیتابیسی را اصطلاحاً Shard میکنیم، از آن نقطه به بعد دیگر بکاپهای قبلی مفید واقع نخواهند شد که در چنین مواقعی و در صورت لزوم باید بکاپ را نیز Shard کرد که این کاری بس هزینهبر و البته عجین با خطا است.
برخی سرویسها همچون MySQL Cluster یا MongoDB Atlas قابلیت Sharding را دارند در حالی که بسیاری از سیستمهای مدیریت پایگاه داده از چنین فیچری بیبهره هستند و همین مسئله منجر بدین خواهد شد که کل بار این مسئولیت بر عهدهٔ دولوپرها افتاده تا جایی که گاهی اوقات ایشان باید در سطح اپلیکیشن این کار را هندل نمایند.
آشنایی با معماریهای Sharding
حال فرض کنیم که بسته به نیازهای بیزینس آنلاین خود، نیاز به پارتیشنبندی دیتابیس خود داریم اما اکنون سؤال اینجا است که «برای شروع دست به چه کاری باید بزنیم؟» به عنوان یک قانون کلی، باید این نکته را مد نظر داشته باشیم که وقتی قصد داریم به چندین دیتابیس یا جدول مختلف کوئری بزنیم، نیاز است تا دقیقاً بدانیم که کوئری مد نظرمان برای پارتیشن/شارد/جدول درستی ارسال میشود که در غیر این صورت با نتایجی اشتباه و گاهی هم از دست دادن دیتا مواجه خواهیم شد. در همین راستا، در ادامه به معرفی برخی معماریهای رایج Sharding میپردازیم که هر کدام از آنها از رویکرد مختلفی به منظور پخش کردن دادهها در میان پارتیشنهای مختلف استفاده میکند.
- Key Based Sharding: در این نوع معماری وقتی که دیتای جدیدی در دیتابیس ثبت میگردد، کلیدی مرتبط با آن دیتا در نظر گرفته میشود (به طور مثال، اگر یک مشتری جدید در فروشگاه آنلاینی ثبتنام میکند، customer_id به عنوان چنین کلیدی در نظر گرفته خواهد شد.) سپس این کلید به فانکشنی داده میشود که بسته به ورودیای که میگیرد، مشخص میکند که آن دیتا روی چه پارتیشنی باید ذخیره گردد به طوری که داریم:
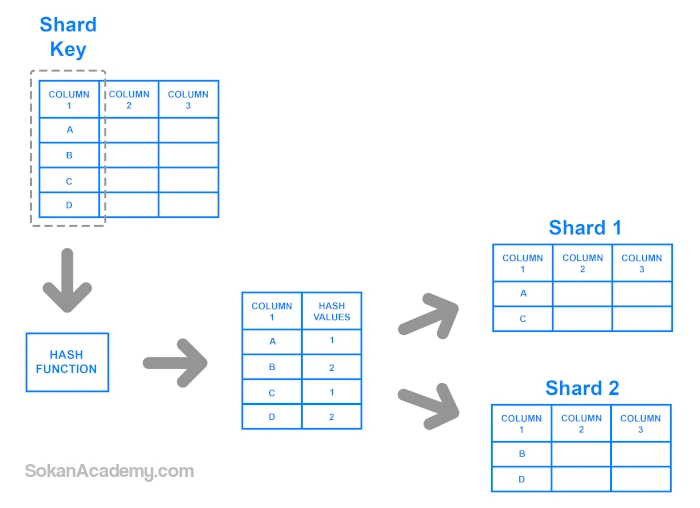
به منظور اطمینان حاصل کردن از اینکه دادهها به درستی در پارتیشنهای مناسبی ذخیره میگردند، نیاز است تا مقادیر که وارد چنین فانکشنی میشوند که تحت عنوان Hash Function شناخته میگردد منحصربهفرد باشند. برای درک بهتر این موضوع، میتوان Primary Key را به عنوان چنین دیتایی در نظر گرفت که در این معماری چنین کلیدی تحت عنوان Shard Key شناخته میشود و نیاز به توضیح نیست که این کلید هرگز نباید در طول زمان دستخوش تغییر شود که در غیر این صورت، یکپارچگی دادهها به هم خواهد خورد و اگر هم اینطور نشود، پردازش زیادی برای آپدیت پارتیشنهای مربوطه نیاز خواهد بود.
یکی از چالشهای کار با معماری Key Based Sharding آن است که در صورت نیاز به افزودن سرورهای جدید و یا کم کردن تعداد سرورهای موجود، کار ممکن است به مشکل برخورد بدین صورت که مثلاً وقتی سرور جدیدی به کلاستر خود اضافه میکنیم، هر سرور نیاز به اصطلاحاً یک Hash Value دارد تا در حین ثبت دادههای جدید مورد استفاده قرار گیرد اما این در صورتی است که اگر بخواهیم دادههای موجود را روی این سرور انتقال دهیم، نیاز به آپدیت دیتا به منظور شناخت این Hash Value داریم که این کار بسیار پرهزینه خواهد بود.
- Range Based Sharding: همانطور که از نام این معماری مشخص است، در این روش دیتا را بر اساس بازهٔ خاصی روی پارتیشنهای مختلف پخش میکنیم. مثلاً فرض کنیم که در یک فروشگاه آنلاین دیتابیسی داریم که دادههای مرتبط با تمامی محصولات در آن ذخیره شده است. حال به منظور پارتیشنبندی چنین دیتابیسی میتوان از دیتابیسها یا جداول مختلفی بر اساس قیمت محصولات استفاده نماییم:
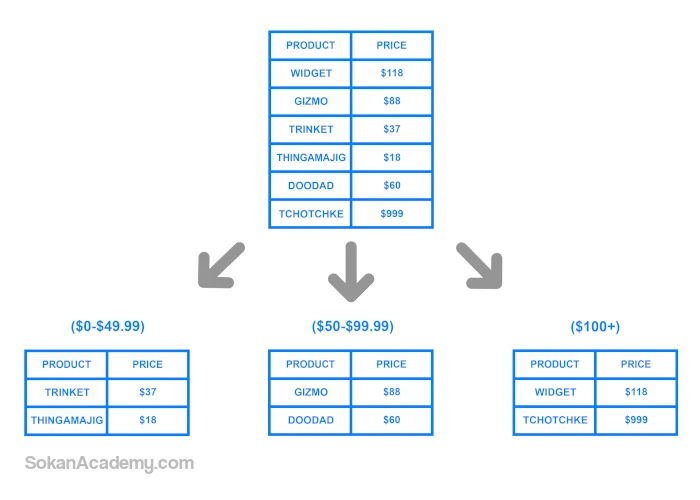
نیاز به توضیح نیست که یکی از مزایای پیادهسازی این معماری سادگی آن است به طوری که اِسکمای تمامی پارتیشنها یکسان است. در چنین شرایطی، وقتی هم که بخواهیم در سطح اپلیکیشن تصمیم بگیریم که دادهٔ جدید در کدام پارتیشن ذخیره شود، صرفاً نیاز است به بازهٔ قیمتی آن توجه کرد و بسته به آن قیمت پارتیشن مرتبط را انتخاب کرد. در عین حال، همچون مثالی که قبلاً در ارتباط با حروف الفبا زدیم، در این نوع معماری ممکن است تعادل بهم خورد به طوری که مثلاً این احتمال وجود دارد محصولاتی که در بازهٔ ۱۰/۰۰۰ تا ۱۰۰/۰۰۰ تومان هستند بسیار زیاد باشند و بالتبع پارتیشن مرتبط با این بازه بسیار حجیم خواهد شد.
- Directory Based Sharding: همانطور که در تصویر زیر مشاهده میکنید، در این معماری نیاز به یک اصطلاحاً Lookup Table داریم که این وظیفه را دارا است تا Shard Key، که قبلاً با مفهوماش آشنا شدیم، را در خود ذخیره سازد تا بر آن اساس مشخص شود که چه پارتیشنی چه نوع دیتایی را در خود ذخیره کرده است. به زبان عامیانه، این جدول همچون فهرست واژگان در انتهای برخی کتابها است که از آن طریق مشخص میشود کدام اصطلاح در کدام بخش یا کدام صفحه استفاده شده است. اگر بخواهیم این معماری را به صورت ساده تشریح کنیم، خواهیم داشت:
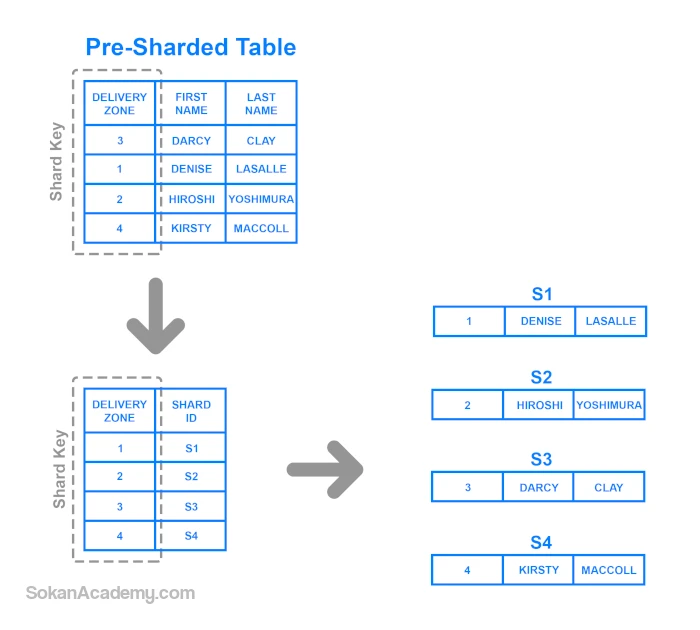
همانطور که در تصویر فوق مشخص است، ستون Delivery Zone به عنوان Shard Key در نظر گرفته شده است سپس دادهها بر اساس این ستون در Lookup Table ثبت میشوند بدین صورت که مشخص میشود هر کلید مرتبط با کدام پارتیشن است. در مقایسه با معماری قبلی (Range Based Sharding)، در مواقعی که مهم نباشد برای ذخیرهسازی دیتا از کدام پارتیشن استفاده شود، برگبرنده در دست Directory Based Sharding است.
یکی از مزایای قابلتوجه این نوع معماری آن است که انعطافپذیری بالایی دارا است به طوری که دست دولوپر را باز میگذارد تا از الگوریتم اختصاصی خودش برای پخش کردن دیتا مابین پارتیشنهای مختلف استفاده کند مضاف بر اینکه افزودن پارتیشنهای جدید به صورت دینامیک نیز کار دشواری نخواهد بود اما در عین حال توجه داشته باشیم که اگر Lookup Table، که نقطهٔ شروع کوئری است، به هر دلیلی با مشکل مواجه گردد، کل اپلیکیشن یا حداقل بخشهای بسیاری از آن از کار خواهند افتاد!
چه زمانی باید از معماری Sharding استفاده کرد؟
برخی متخصصین بر این باورند که با حجیم شدن دیتابیس مهاجرت به سمت معماری Sharding حتمی است اما برخی هم بر این باورند که به خاطر پیچیدگیهایی که دارد، تا حد ممکن باید از آن اجتناب کرد مگر آنکه واقعاً راه چارهای در کار نباشد. در همین راستا، در ادامه موقعیتهایی را معرفی میکنیم که در آنها این نوع معماری میتواند به بهبود پرفورمنس کمک کند:
- حجم دادهها آنقدر بالا است که یک دیتابیس به تنهایی نمیتواند آنها را هندل کند.
- حجم خواندن/نوشتن دیتا آنقدر بالا است که منابع یک سرور کفایت نمیکند.
- پهنایباند لازم برای کارکرد صحیح اپلیکیشن از پهنایباندی که در اختیار دیتابیس است پیشی میگیرد و بالتبع پرفورمنس کاهش مییابد.
به طور کلی، پیش از تصمیمگیری به منظور پارتیشنبندی دیتابیس خود، بهتر است دیگر گزینهها را مورد بررسی قرار دهیم به طوری که برخی از بهبودهایی که میتوانیم انجام دهیم عبارتند از:
- مجزاسازی سرور اپلیکیشن از سرور دیتابیس: اگر یک اپلیکیشن به اصطلاح Monolithic داشته باشیم که تمامی اجزای آن روی تنها یک سرور است، شاید بتوان با انتقال دیتابیس به یک سرور مجزا پرفورمنس آن را بهبود بخشید به طوری که با دنبال کردن این استراتژی میتوان دست به Vertical Scaling زد که در ابتدای مقاله با مفهوم آن آشنا شدیم.
- استفاده از سازوکارهای کَش مناسب: چنانچه فراخوانی دادهها در اپلیکیشنمان بیش از ثبت دادههای جدید باشد، در چنین مواقعی میتوان با کَش کردن کوئریها بار روی سرور را کم و در نتیجه پرفورمنس را زیاد کرد.
- استفاده از رِپلیکیشن: در معماری دیتابیس، Replication به فرآیند گفته میشود که به موجب آن دیتا از یک دیتابیس به یک یا چند دیتابیس دیگر کپی میشود به طوری که تمامی آنها از دادههای یکسانی برخوردار خواهند بود و این کار باعث میشود تا پروسهٔ فراخوانی دادهها مابین چندین سرور پخش گردد و در نتیجه از کِرشهای احتمالی جلوگیری شود.
جمعبندی
در نظر داشته باشیم که وقتی تعداد مخاطبین اپلیکیشن از یک حد خاصی عبور کند، هیچکدام از راهکارهای فوق پاسخگو نخواهند بود و در چنین مواقعی باید به فکر Sharding یا دیگر استراتژیهای سیستمهای توزیعشده بود که در همین راستا توصیه میکنیم به پادکست مصاحبه با امیرحسین پیبراه: فوقدکترای بیگ دیتا و متخصص سیستمهای توزیعشده مراجعه نمایید. به طور کلی، گرچه این معماری در برخی مواقعی تنها سولوشن است اما این را هم باید به خاطر داشته باشیم که پیچیدگیهای خاص خود را نیز دارا است و همین مسئله موجب میگردد تا خیلی از توسعهدهندگان عطای آن را به لقایش ببخشند!