
الگوی معماری داده گرافی (Graph) یکی از انواع پایگاه های داده NoSQL است که در برنامه هایی که نیازمند تحلیل روابط بین اشیا و یا مشاهده تمامی گره ها در یک گراف هستند، مهم است. درباره پایگاه داده NoSQL، ویژگی ها و مزیت های آن در مقاله ی دیتابیس NoSQL چیست؟ توضیح داده شده است و انواع دیتابیس های NoSQL نیز در مقاله ای با همین عنوان به طور کامل بررسی شده اند. بنابراین در این مقاله بر روی پایگاه های داده گرافی به عنوان نوعی از دیتابیس های NoSQL (نو اس کیو ال) متمرکز خواهیم شد. معماری فوق برای ذخیره موثر گره های گراف و ارتباطات بهینه بین آن ها بسیار کارساز است و می توان بر روی داده هایی که به صورت یک گراف ذخیره شده اند query مورد نظر خود را اجرا کرد. این نوع پایگاه های داده برای هر نوع مسئله کسب و کار که دارای ارتباطاتی پیچیده بین اشیا هستند، مفید اند. شبکه های اجتماعی، موتورهای مبتنی بر قواعد و تحلیل ساختارهای پیچیده شبکه، نمونه هایی از کاربرد الگوی معماری داده گرافی هستند.
پایگاه های داده گرافی چیست؟
پایگاه های داده گرافی شامل دنباله ای از گره ها و ارتباطات است که با ترکیب آن ها با یکدیگر یک گراف ایجاد می شود. معماری داده key-value store شامل دو فیلد key و value است. در مقابل، در یک پایگاه داده گرافی از سه فیلد اساسی داده با نام گره، روابط و خصلت روابط استفاده می شود. به برخی از گراف ها به دلیل ساختار node-relationship-node، به اصطلاح triple stores نیز گفته می شود.
زمانی که آیتم های زیادی داریم که با یکدیگر روابط پیچیده ای دارند و هر یک نیز دارای خصلت های مختص به خود هستند، استفاده از Graph stores بسیار مناسب است. در Graph store امکان اجرای query ساده وجود دارد و می توان برای نمونه نزدیک ترین همسایه و یا الگوی خاص تر و پیچیده تری را پیدا کرد. مثلا اگر از یک پایگاه داده رابطه ای برای ذخیره لیستی از دوستان خود استفاده کرده باشید، می توان لیست مرتب شده ای بر اساس نام خانوادگی از دوستان خود را تولید و در خروجی نمایش داد. در صورت استفاده از Graph store، نه تنها می توان لیستی از دوستان خود را بر اساس نام خانوادگی پیدا کرد، همچنین می توان لیستی از دوستان خود که علاقه مند به مطالعه کتاب های علمی هستند را نیز، پیدا کرد. Graph stores، صرفا به این موضوع اکتفا نمی کند که به شما بگوید بین دو گره یک رابطه وجود دارد یا خیر بلکه قادر به ارائه گزارش های تکمیلی همراه با جزئیات مورد نیاز در خصوص هر یک از روابط موجود است.
گره های گراف معمولا بیانگر اشیای دنیای واقعی نظیر اسامی هستند. گره ها می توانند افراد، سازمان ها، شماره تلفن، صفحات وب، کامپیوترهای موجود بر روی یک شبکه و یا حتی سلول های بیولوژیکی در یک ارگانیزم زنده باشند. ارتباطات را می توان به منزله اتصالات بین اشیا درنظر گرفت که معمولا به صورت کمان در دیاگرام ها نشان داده می شوند. اجرای یک query بر روی یک گراف، مشابه حرکت کردن بین گره ها در یک گراف است.
همانگونه که قبلا اشاره شد، در پایگاه های داده رابطه ای (RDBMS) از اعداد برای کلید اصلی و خارجی برای ارتباط سطرها در جداولی که در بخش های مختلف یک هارد دیسک ذخیره شده اند، استفاده می شود. انجام عملیاتی نظیر Join در RDBMS دارای هزینه بالایی است و علاوه بر تاخیر در انجام عملیات، I/O زیادی را نیز به دنبال خواهد داشت. Graph store، گره ها را با یکدیگر مرتبط می نماید و متوجه این موضوع می شود که دو گره با شناسه یکسان،گره های مشابه هستند. Graph stores به گره ها، شناسه های داخلی را نسبت می دهد و از این شناسه ها برای Join شبکه ها به یکدیگر استفاده می کند. بر خلاف RBDMS، در Graph stores عملیات Join سبک تر بوده و کار با سرعت به مراتب بیشتری انجام می شود. علت این کار به ماهیت کوچک هر گره و قابلیت نگهداری گراف در RAM برمی گردد که در آن بازیابی داده نیازمند عملیات I/O سنگینی نیست.
Join درگراف به چه معناست؟
Join درگراف به معنای ارتباط گره ها با یکدیگر است، تفاوت هایی بین join در پایگاه داده های گرافی و MySQL وجود دارد، تفاوت اصلی این است که در یک پایگاه داده گرافی، روابط در همان ذخیره سازی ویژگی های یک گره، ذخیره می شوند و ماهیت این نوع پایگاه داده ارتباطات را ذخیره می کند. پس وقتی که در پایگاه های داده گرافی از join استفاده می کنیم در واقع لیستی از گره هایی که به یک گره متصل است را بازیابی می کنیم. این در حالی است که در یک پایگاه داده رابطه ای، ارتباط در ساختار جداول تعریف می شود و نیاز است به کلید های خارجی که بین دو جدول جا به جا شوند تا بتوان Join را در بین آن ها تعریف کرد. یا در مواقعی که ارتباط از نوع چند به چند می باشد، نیاز است یک جدول میانی به ساختار اضافه کرد.
برخلاف سایر الگوهای NoSQL، مقیاس پذیری پایگاه های داده گرافی بر روی چندین سرویس دهنده دارای چالش های مختص به خود است. در چنین مواردی می توان داده را بر روی چندین سرویس دهنده تکرار کرد تا امکان خواندن و کارآیی اجرای query ها بهتر گردد. ولی ذخیره بر روی چندین سرویس دهنده و اجرای query بر روی گرافی که گره های آن بین چندین سرویس دهنده توزیع شده اند، دارای پیچیدگی ها مختص به خود است.
نمونه هایی از پایگاه های داده ی گرافی
پایگاه های داده زیر از نوع گرافی هستند:
- Neo4J
- AllegroGraph
- ArangoDB
- InfinitGraph
- OrientDB
- Titan
- StartDog
- MarkLogic
شکل زیر روند رو به رشد استفاده از پایگاه داده های گرافی در سال های اخیر را نشان می دهد
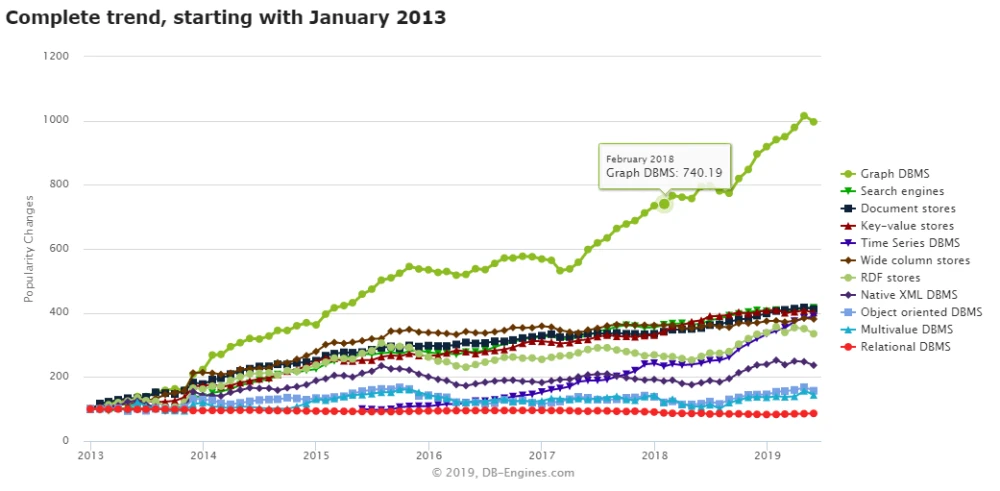
در ادامه به معرفی تعدادی از معروف ترین پایگاه های داده گرافی و ویژگی آن ها می پردازیم:

1. پایگاه داده Neo4j

Neo4j معروفترین DBMS متن باز گرافی است که کارایی و مستندسازی بسیار خوب و جامعه کاربران فعالی دارد. برای استفاده از این پایگاه داده باید به زبان Cypher مسلط بود.
در Neo4j، مقیاس پذیری افقی داریم که در عمل خواندن توسط روش master-slave صورت می گیرد، اما تمام درخواست های نوشتن، فقط در یک ماشین پاسخ داده می شوند.در نتیجه عمل نوشتن، به صورت افقی مقیاس پذیر نیست. پس می توان نتیجه گرفت که Neo4j برای کاربردهایی که میزان نوشتن کم و خواندن زیاد باشد مناسب است. در این پایگاه داده از تکنیک sharding (بخش بندی داده) استفاده نمی شود، زیرا تقسیم بهینه یک گراف بزرگ بین چندین ماشین هزینه بر و چالش برانگیز است.
سهولت در استفاده،کاهش استفاده از حافظه، مناسب بودن برای رایانش ابری (Cloud)، پشتیبان گیری حرفه ای، شمای انعطافپذیر، دارای Driver برای زبان های java, c#, phyton, JavaScript, php, R, go و همچنین پشتیبانی از فریمورک های Spring , Kango, Laravel از دیگر قابلیت های آن است.
در شکل زیر یک کوئری را مشاهده می کنید که در آن گزارشی از یک ساختار سلسله مراتبی را درخواست می کند. تفاوت کوئری توسط دو زبان SQL و Cypher را مشاهده می کنید. این کوئری با استفاده از زبان Cypher هم باعث شده کوئری کوتاه تری نوشته شود و هم این زمان debug کردن و رفع مشکل را به مراتب کاهش می دهد.

2. پایگاه داده OrientDB

پایگاه داده OrientDB یکی دیگر از پایگاه های داده معروف و دارای رشد است که هم از حالت Document-based و هم ازحالت گرافی پشتیبانی می کند. این پایگاه داده را می توان پایگاه داده همه فن حریف در بین خانواده NoSQL دانست. این پایگاه داده را می توان هم با شِما(Schema)، هم بدون شِما و حتی ترکیبی از آن ها استفاده کرد. این پایگاه داده از الگوریتم جدید ایندکس کردن به اسم MVRB-Tree استفاده می کند.
مزایای مهم OrientDB
• از ویژگی های ACID به طور کامل پشتیبانی می کند، هرچند در مواقع قطعی سیستم، سندهای در حال تراکنش بازیابی نمی شوند.
• پشتیبانی کامل از زبان SQL
• امکان استفاده از HTTP , RESTful بدون واسطه
• نصب و استفاده سریع (حدود 60 ثانیه)
• اجرا در هر پلتفرمی (پیاده کردن آن با استفاده از جاوای خام (pure java) اجازه میدهد که با ویندوز، لینوکس و هر سیستم عامل دیگری با سازگاری اجرا شود.)
• متن باز بودن به همراه گواهینامه Apache2
• قابلیت مدیریت ساختار گراف و نمودار ها به صورت Native
• توزیعپذیری: پشتیبانی کامل برای تکثیر در چند سرور از جمله توزیع های جغرافیایی
• قابلیت Embed شدن در اپلیکیشن های جاوا
• دارای افزونه ای به نام Teleporter ( با استفاده از آن می توان به راحتی یک پایگاه داده رابطه ای را به OrientDB تبدیل کرد)
• مناسب برای رایانش ابری
3. پایگاه داده Titan

TITAN یک پایگاه داده توزیع شده و مقیاس پذیر مبتنی بر گراف است. تیتان بسیار برای مرتب کردن داده های گراف و کوئری بر روی گراف بهینه عمل می کند. این پایگاه داده توان پردازش میلیاردها گره و یال به صورت توزیع شده در میان چند ماشین را دارد. تیتان یک قابلیت تراکنشی شدن را دارد و می تواند query های از نوع graph traversals که در آن فرآیند بازدید از گره ها را انجام می شود را به خوبی و به صورت real time پشتیبانی کند.
قابلیت های Titan
• مقیاس پذیری elastic و خطی برای دادههای رو به رشد افزایش
• توزیع و تکرار داده برای عملکرد بهتر و تحمل خطا
• پشتیبانی ار ACID
• پشتیبانی از storage backends مانند Casendra,HBase, BerkeleyDB
• پشتیبانی از تجزیه و تحلیل داده های حجیم گرافی، گزارش دهی و فرآیند ETL
• پشتیبانی از Hadoop , spark
• پشتیبانی از Apache Giraph
• متن باز به همراه گواهینامه Apache 2
4. پایگاه داده Arango DB

این پایگاه داده از چند مدل پایگاه داده از جمله Document, key-value, graph با یک هسته پایگاه داده و یک زبان پشتیبانی می کند، زبان پرس و جوی آن AQL يا (Arango Query Language) است با اینکه این زبان مختص به Arango می باشد ولی در بسیاری از جهاتی شبیه به SQL است.
این پایگاه داده زمانی که با داده های گرافی کار می کند query های مقیاس پذیری (scalable queries) را ارائه می کند.همچنین این پایگاه داده از فرمت json برای فرمت اصلی ذخیره سازی استفاده می کند. اما داخل آن از فرمت باینری سریع و جمع و جور برای سریال سازی و ذخیره سازی به نام VelocyPack ArangoDB استفاده می کند.
ArangoDB می تواند یک JSON object را به عنوان یک ورودی درون یک مجموعه ذخیره کند. بنابراین، نیازی به جداسازی قسمت های JSON نیست. بنابراین داده های ذخیره شده به سادگی می توانند ساختار درخت داده های XML را به ارث ببرند.
ویژگی های Arango DB
• نصب آسان
• انعطاف پذیری مدل سازی داده ها (می توان داده ها را به صورت ترکیبی از سند، key-value و گراف مدل سازی کرد).
• زبان query قوی برای بازیابی و اصلاح داده ها
• قابلیت استفاده از آن به عنوان یک سرویس دهنده ی سرور
• قابلیت تراکنشی بودن
• قابلیت تکرار و توزیع داده ها
• استفاده از JavaScript
• متن باز بودن و رایگان
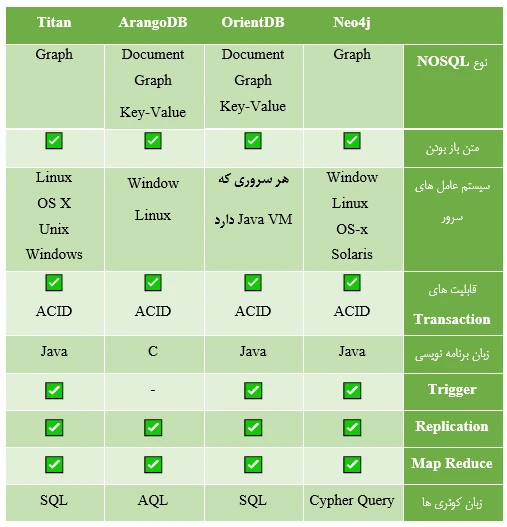
در جدول زیر به مقایسه پایگاه های داده معرفی شده به صورت خلاصه و جمع بندی شده پرداختیم:
مقایسه Neo4j ، OrientDB
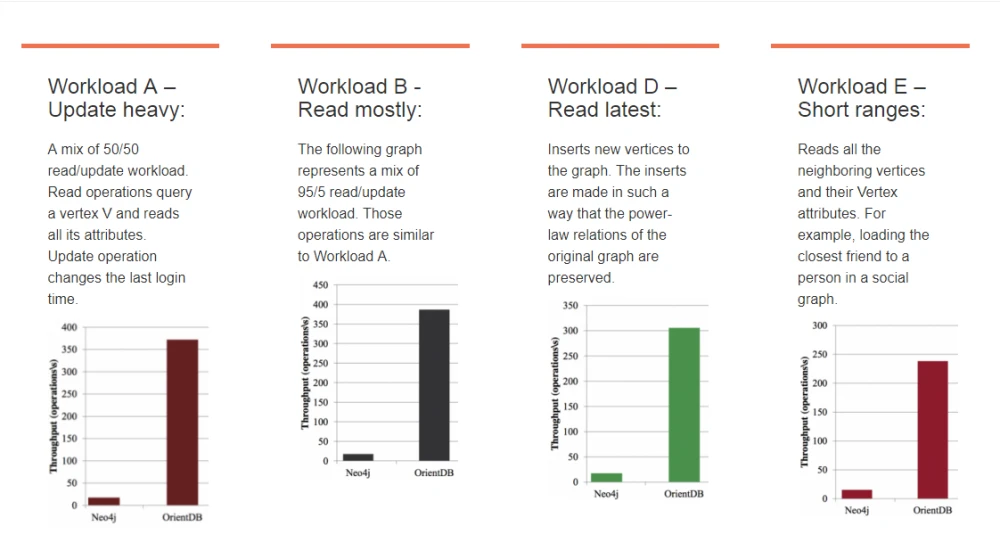
این دو پایگاه داده گرافی در مقایسه ها و استفاده آن ها بیشتر بر سر زبان ها قرار گرفته اند. Neo4j که پایگاه داده گرافی معروف و مشهوری است و خیلی از سیستم های معروف از آن استفاده می کنند در عین حال OrientDB رشد بسیار چشمگیری نزد برنامه نویسان داشته و آینده ی خوبی برای آن متصور می شود. در شکل زیر مقایسه ی این دو را در عملکرد خواندن و نوشتن در شرایط مختلف مشاهده می کنید:
در این مقاله با اهمیت و فواید پایگاه داده گرافی آشنا شده اید و با چندین پایگاه داده گرافی که جزو معروف ترین آن ها هستند نیز آشنا شدید.
اگر شما هم تجربه ای در استفاده از این نوع پایگاه داده ها دارید با ما در قسمت نظرها در میان بگذارید.