
در حال حاضر پایتون پر استفاده ترین زبان برنامه نویسی برای پروژه های مختلف در سراسر جهان است. طبق آمار، 44.1 درصد از برنامه نویسان، زبان برنامه نویسی پایتون را برای توسعه ی اپلیکیشن/وب انتخاب می کنند. با این حال، این بدان معنا نیست که توسعه دهندگان پایتون می توانند کدهای نامرتب و ناکارآمد که میتواند برای شما و مشتریانتان زمان و هزینه داشته باشد، بنویسند و از بهینه سازی کد معاف هستند. در این مقاله قصد داریم در مورد روش های بهینه سازی کد پایتون، صحبت کنیم.
بهینهسازی چیست؟
بیایید با تعریف بهینه سازی کد شروع کنیم تا ایده ی اولیه را به دست آورید و بفهمید چرا به آن نیاز است. گاهی اوقات ایجاد کدی که فقط یک وظیفه را اجرا می کند کافی نیست. کد بزرگ و ناکارآمد می تواند باعث کندی برنامه شود، منجر به زیان مالی برای مشتری شود، یا به زمان بیشتری برای بهبودها و رفع اشکال نیاز داشته باشد.
بهینه سازی کد پایتون راهی است که میتوانید برنامه تان را با خط های کد کمتر، حافظه یا سایر منابع درگیر کمتر، انجام هر کاری را کارآمدتر و سریع تر انجام دهید و در عین حال نتیجه های درستی را تولید کنید.
وقتی نوبت به پردازش تعداد زیادی عملیات یا داده در حین انجام یک کار میرسد، بهینه سازی کد بسیار اهمیت پیدا می کند. جایگزینی و بهینه سازی برخی بلوک ها و ویژگی های کد ناکارآمد، می تواند معجزه کند:
- افزایش سرعت عملکرد برنامه
- تمیز و خوانا کردن کد
- ساده تر کردن ردیابی و اشکال زدایی خطا
- صرفه جویی زیادی در توان محاسباتی و موارد دیگر
نکتههای برتر بهینه سازی کد پایتون
توسعه دهندگان پایتون باید بتوانند به جای برنامه نویسی پایه، از روش های بهینه سازی کد استفاده کنند تا از اجرای روان و سریع برنامه ها اطمینان حاصل کنند. در ادامه ی این مقاله، ما 6 نکته در مورد نحوه ی بهینه سازی کد پایتون برای تمیز و کارآمد کردن آن فهرست کرده ایم.
۱. اعمال روش بهینهسازی Peephole
برای درک بهتر روش بهینه سازی Peephole (Peephole Optimization Technique)، اجازه دهید با نحوه ی اجرای کد پایتون شروع کنیم. ابتدا کد در یک فایل استاندارد نوشته می شود، سپس می توانید دستور زیر را اجرا کنید:
python -m compileall <filename>به جای filename، باید نام فایل خود را قرار دهید. بعد از اجرا، همان فایل را با فرمت pyc.* که نتیجه ی بهینه سازی است، دریافت خواهید کرد.
<Peephole>، یک روش بهینه سازی کد در پایتون است که در زمان کامپایل، برای بهبود عملکرد کد شما انجام می شود. با روش بهینه سازی Peephole، کد در پشت صحنه بهینه می شود و یا با پیش محاسبه ی عبارت های ثابت، یا با استفاده از تست های membership انجام می شود. Membership Testing یا تست عضویت یعنی بررسی این که آیا مجموعه ای از آیتم ها (یک list، یک set، یک dictionary و غیره) حاوی آیتم خاصی است یا خیر. برای مثال، بررسی این که آیا لیستی از اعداد زوج حاوی عدد 42 است یا خیر.
برای مثال، میتوانید چیزی شبیه به تعداد ثانیه های یک روز را به صورت a = 60*60*24 بنویسید تا کد خواناتر شود، اما مفسر زبان، خیلی سریع محاسبه را انجام میدهد و از آن به جای تکرار عبارت بالا استفاده میکند و باعث کاهش عملکرد نرم افزار می شود.
نتیجه ی روش بهینه سازی Peephole، این است که پایتون عبارت ثابت 60*60*24 را از قبل محاسبه میکند و آنها را با 86400 جایگزین میکند. بنابراین حتی اگر همیشه 60*60*24 بنویسید، کارایی را کاهش نمیدهد.
استفاده از روش بهینه سازی Peephole
با استفاده از این روش، می توانید یک بخش از برنامه یا بخشی از دستور را بدون تغییرهای قابل توجه، در خروجی جایگزین کنید.
با استفاده از این روش بهینه سازی، می توانید:
- ساختارهای قابل تغییر را به غیرقابل تغییر تبدیل کنید. این کار را می توان با استفاده از یکی از 3 tuple زیر انجام داد:
- <code__.co_varnames__> که متغیرهای محلی را با پارامترهای گنجانده شده، ذخیره می کند.
- <code__.co_names__> که دادههای خام global را در خود جای می دهد.
- <code__.co_consts__> که به همه ی ثابت ها ارجاع می دهد.
- عضویت یک عنصر را با در نظر گرفتن دستور ها به عنوان یک عمل با هزینه ثابت و بدون توجه به اندازه ی مجموعه، تایید کنید.
- هم مجموعه (set) و هم لیست (list) را به Constants تبدیل کنید.
به این نکته توجه کنید که این تبدیل فقط توسط پایتون برای داده های خام (literals) قابل انجام است. بنابراین، اگر هر یک از مجموعه ها یا لیست های مورد استفاده، literal نباشند، بهینه سازی اتفاق نخواهد افتاد.
Literal ها داده های خامی هستند که در حین برنامه نویسی به متغیرها یا ثابت ها نسبت داده می شوند. در پایتون انواع مختلفی از Literal مانند رشته ای، عددی، بولی و Literal ویژهی None داریم.
بیایید به چند مثال نگاهی بیاندازیم:
def peephole_func():
a = "Hello, world!" * 5
b = [1, 2] * 7
c = (10, 20, 30) * 3
print(a, b, c)
peephole_func.__code__.co_consts: (
None
Hello, world!Hello, world!Hello, world!Hello, world!Hello, world!
1
2
7
(10, 20, 30, 10, 20, 30, 10, 20, 30)
)
peephole_func.__code__.co_varnames: ('a', 'b', 'c')
peephole_func.__code__.co_names: ('print',)
- عبارت Hello world” * 5“ یک عبارت ثابت با طول کمتر از 4096 است. بنابراین توسط کامپایلر به صورت “Hello world” در 5 بار متوالی، ارزیابی می شود.
- عبارت 7*[1,2] یک لیست (شی قابل تغییر) است بنابراین ارزیابی نمی شود.
- عبارت 3*(10, 20, 30) دنباله ای به طول 9 است که کمتر از 256 است (برای tuple ها)، بنابراین به صورت (10, 20, 30, 10, 20, 30, 10, 20, 30) ذخیره می شود.
۲. وارد کردن (Intern) رشته ها برای کارایی
اشیا رشته ای در پایتون دنباله ای از کاراکترهای یونیکد هستند، بنابراین در مستندات، دنباله های متنی (text) نامیده میشوند. هنگامی که کاراکترهایی با اندازه های مختلف به یک رشته اضافه می شود، اندازه و وزن کل آن افزایش می یابد، اما نه فقط با اندازه کاراکتر اضافه شده. پایتون اطلاعات اضافی را برای ذخیره رشته ها اختصاص می دهد که باعث می شود فضای زیادی را اشغال کنند. برای افزایش کارایی از یک روش بهینه سازی به نام string interning استفاده می شود.
ایده ی روش string interning این است که رشته های خاص را هنگام ایجاد، در حافظه کش می کند. یعنی تنها یک نمونه از یک رشته ی خاص در هر زمان مشخص، فعال است و هیچ حافظه ی جدیدی برای ارجاع به آن لازم نیست.
String interning شباهت های زیادی با اشیا مشترک دارد. هنگامی که یک رشته درون سازی (interned) میشود، به عنوان یک شی مشترک در نظر گرفته میشود، زیرا نمونه ای از آن شی رشته به صورت global توسط همه برنامههایی که در یک جلسه (session) پایتون اجرا میشوند به اشتراک گذاشته میشود.
در رایج ترین پیاده سازی زبان برنامه نویسی پایتون، CPython هر بار که یک session تعاملی پایتون مقداردهی اولیه می شود، اشیا مشترک را در حافظه بارگذاری می کند.
به همین دلیل است که string interning به پایتون اجازه می دهد تا به طور موثر اجرا شود، هم از نظر صرفه جویی در زمان و هم در حافظه.
رشتههای identifier
پایتون تمایل دارد فقط رشته هایی را ذخیره کند که به احتمال زیاد مورد استفاده مجدد قرار می گیرند، یعنی رشته های identifier:
- نام ویژگی ها
- نام متغیرها
- نام آرگومان ها
- نام توابع و کلاس ها
- کلیدهای dictionary
اصولی که بر اساس آن یک رشته باید درون سازی (Intern) شود:
- فقط رشته ای که در زمان کامپایل به عنوان یک رشته ثابت بارگذاری می شود، درون سازی خواهد شد، و برعکس، رشته ای که در زمان اجرا ساخته شده است، درون سازی نمی شود.
- یک رشته اگر حاصل constant folding باشد و بیش از 20 کاراکتر طول داشته باشد درون سازی (Intern) نمی شود، زیرا به سختی می توان گفت که یک identifier است. (در Constant Folding، engine به جای محاسبه در زمان اجرا، عبارت های ثابت را در زمان کامپایل پیدا و ارزیابی میکند و زمان اجرا را کم تر و سریع تر میکند.)
- پایتون فقط در صورتی یک رشته را درون سازی (Intern) کرده و یک هش برای آن ایجاد می کند که رشته ای را با نامی که فقط ترکیبی از حروف / اعداد / کاراکترهای سیاه را شامل می شود و با یک حرف یا یک کاراکتر زیر خط شروع می شود، declare کند.
بنابراین، تمام رشته هایی که از یک فایل خوانده می شوند یا از طریق شبکه دریافت می شوند، بخشی از درون سازی (interning) نیستند. با این حال، برای شروع درون سازی (Intern) چنین رشته هایی و پردازش آن ها، کافیست آن را در تابع ()intern بارگذاری کنید.
۳. نمایه کردن (profile) کد
با نمایه کردن (profile) کد خود، می توانید زمینه های بهبود آن را برای بهینه سازی بیشتر شناسایی کنید. دو راه اصلی برای انجام این کار وجود دارد.
استفاده از <timeit>
این ماژول زمان مورد نیاز برای اجرای کار توسط یک بخش کد خاص را بر حسب میلی ثانیه اندازه گیری می کند.
import hashlib
import timeit
def hash_func():
return hashlib.sha256(b'Example of code profiling with timeit').hexdigest()
print(timeit.timeit(hash_func, number=1000))
print(timeit.timeit(hash_func, number=1000000))
در زیر نتیجه ی محاسبه آن بیان شده است:
0.0006536689979839139
0.6573250420042314
Process finished with exit code 0
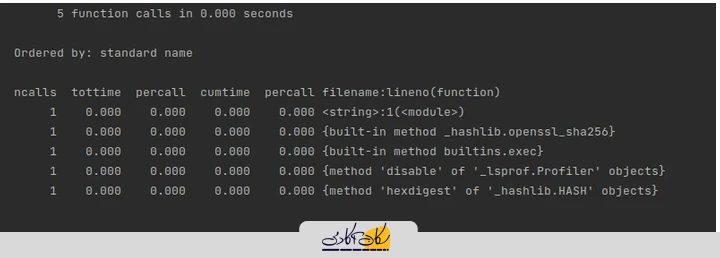
استفاده از <cProfile>
import hashlib
import cProfile
cProfile.run("hashlib.sha256(b'Example of code profiling with cProfile').hexdigest()")
این ماژول پروفایل پیشرفته است. cProfile برای اکثر کاربران توصیه می شود. یک اکستنشن C با سربار معقول است که آن را برای پروفایل برنامه های طولانی مدت مناسب می کند. چند راه برای اتصال آن به کد پایتون وجود دارد:
- یک تابع را در متد run قرار دهید و سپس عملکرد را اندازه گیری کنید.
- کل اسکریپت را از خط فرمان در حالی که cProfile را به عنوان آرگومان فعال می کنید، با استفاده از گزینه “m-” پایتون اجرا کنید.
برای مثال:
python -m cProfile code.py arg1 arg2 arg3توجه داشته باشید که این فقط با فایل های پایتون کار میکند، نمیتوانید یک CLI پایتون را با فراخوانی مستقیم آن نمایه کنید:
python -m cProfile my_cliاگر میخواهید یک CLI را پروفایل کنید، باید مسیر ورودی را به cProfile بدهید. به طور کلی، چیزی شبیه به این خواهد بود:
python -m cProfile venv/bin/my_cliبا اجرای این دستور، پس از اتمام برنامه، یک جدول خروجی خواهد شد. هر خط مربوط به یک تابع نامیده می شود. به عنوان مثال، در این جا cProfile rec_sum.py است:
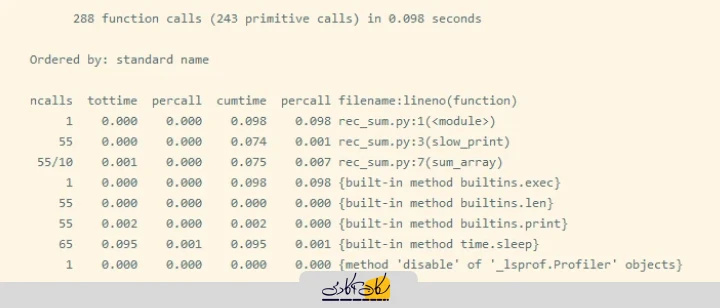
با دانستن عناصر کلیدی گزارش cProfile، می توانید گلوگاه هایی را در کد خود پیدا کنید.
عناصر موجود در تصویر بالا عبارت اند از:
- <ncalls> تعداد فراخوانی های برقرار شده است.
- <tottime> زمان کل صرف شده در تابع داده شده و بیشترین مقدار را دارد.
- <percall> ضریب <tottime> تقسیم بر <ncalls> است.
- <cumtime> یکی دیگر از پارامترهای بسیار مهم برای تمام پروژه ها که نشان دهنده ی زمان تجمعی در اجرای توابع، تابع های فرعی آن است.
- <percall> ضریب <cumtime> تقسیم بر فراخوانی های اولیه است.
- <filename_lineno(function)> یک نقطه ی عمل در یک برنامه است.
۴. استفاده از ژنراتورها و کلیدها برای مرتبسازی
این روش، راهی برای بهینه سازی حافظه با استفاده از ابزاری عالی مانند ژنراتورها است.
کار زیادی برای ساخت یک تکرار کننده در پایتون وجود دارد. ما باید یک کلاس را با متد ()__iter__ و ()__next__ پیاده سازی کنیم، وضعیت های داخلی را پیگیری کنیم، و زمانی که هیچ مقداری برای بازگشت وجود ندارد، StopIteration را افزایش دهیم. این کار هم طولانی است و هم غیر منطقی. ژنراتور در چنین شرایطی به کمک می آید.
مولدهای پایتون راه ساده ای برای ایجاد تکرار کننده هستند. تمام کارهایی که در بالا ذکر کردیم به طور خودکار توسط ژنراتورهای پایتون مدیریت می شوند. به زبان ساده، یک مولد تابعی است که یک شی (تکرار کننده) را برمی گرداند که می توانیم آن را تکرار کنیم (یک مقدار در یک زمان).
ویژگی آن ها این است که همه ی آیتم ها (تکرار کننده ها) را به یک باره بر نمی گردانند، بلکه می توانند هر بار فقط یک مورد را برگردانند. هنگام مرتب کردن موارد در یک لیست، بهتر است از کلیدها و روش پیش فرض <()sort> استفاده کنید. بنابراین، برای مثال، میتوانید لیست و رشته ها را بر اساس شاخص انتخاب شده به عنوان بخشی از آرگومان کلید، مرتب کنید. چیزی شبیه به کد زیر:
from operator import attrgetter
class Employee:
def __init__(self, first_name, last_name, age):
self.first_name = first_name
self.last_name = last_name
self.age = age
employees = [
Employee("Karen", "Chen", 19),
Employee("Jason", "Wilson", 40),
Employee("John", "Brown", 25)
]
sorted_by_age_lambda = sorted(employees, key=lambda employee: employee.age)
sorted_by_age_attrgetter = sorted(employees, key=attrgetter("age"))
۵. فراموش نکردن عملگرهای داخلی و کتابخانه های خارجی
هزاران عملگر و کتابخانه داخلی در پایتون موجود است. بهتر است تا جایی که ممکن است از داخلی ها استفاده کنید تا کد خود را کارآمدتر کنید. این امکان به دلیل این واقعیت وجود دارد که تمام داخلی ها از پیش کامپایل شده اند و بنابراین بسیار سریع هستند.
معادل زبان “C”، برخی از کتابخانه های پایتون، همان ویژگی های کتابخانه اصلی را به شما میدهد، اما عملکرد سریع تری دارد. برای مثال سعی کنید به جای Pickle از cPickle استفاده کنید تا تفاوت را ببینید. پکیج های PyPy و <Cython> راهی برای بهینه سازی یک کامپایلر استاتیک، برای سریع تر کردن فرآیند هستند.
۶. پرهیز از به کار بردن global ها
Global ها می توانند عوارض جانبی غیر آشکار و پنهانی داشته باشند که منجر به کد اسپاگتی شود. علاوه بر این، پایتون در دسترسی به متغیرهای خارجی کند است. به این ترتیب بهتر است برای بهینه سازی کد پایتون خود،
به کار بردن آن ها خودداری کنید یا حداقل استفاده از آن ها را محدود کنید. اگر ضروری است و مجبور هستید آن ها را به کار ببرید، در این جا چند توصیه برای شما داریم:
- از کلمه کلیدی global برای اعلام یک متغیر خارجی استفاده کنید.
- قبل از استفاده از آن ها در داخل حلقه ها، یک کپی local تهیه کنید.
جمع بندی
ایجاد یک برنامه ی قوی و مقیاس پذیر که کارها را سریع و روان انجام می دهد بسیار مهم است. با این حال، توسعه ی چنین برنامه ای تنها با استفاده از روش های کدگذاری اولیه غیر ممکن است. به همین دلیل است که باید کد پایتون را بهینه کنید. در عین حال، با استفاده از روش های بهینه سازی کد پایتون که شرح داده شد، نه تنها می توانید یک کد تمیز ایجاد کنید، بلکه عملکرد برنامه را بهبود بخشیده و در زمان و هزینه ی زیادی صرفه جویی خواهید کرد.