در راهکارهای سنتی، داده های کسب و کار در یک کامپیوتر ذخیره سازی و پردازش میشوند. در این رویکرد، داده ها معمولا در یک سیستم پایگاه داده رابطه ای مانند Oracle یا MySql ذخیره می شود. نرم افزارهای نوشته شده با این پایگاه داده ها در ارتباط هستند و داده های مورد نیازشان را پردازش کرده و نتایج را برای تجزیه و تحلیل های نهایی به کاربران ارائه می کنند. این رویکرد تا زمانی پاسخگوی نیازهای شرکت ها و سازمان ها است که حجم داده ها چندان زیاد نبوده و سرورهای مورد استفاده ی پایگاه های داده، توانایی پردازش آنها را داشته باشند. به عبارتی، قدرت پردازشی سرورها پاسخگوی پردازش داده های در دسترس باشد. در غیر این صورت و در حالتی که شرکت ها و سازمان ها با حجم های بالای داده روبهرو هستند، پردازش داده ها از طریق راهکارهای سنتی پایگاه های داده بسیار زمان بر و خستهکننده خواهد بود. شرکت گوگل مشکل فوق را با ارائه الگوریتمی تحت عنوان MapReduce مرتفع کرده است. این الگوریتم، هر پرس و جو یا Query را به قسمت های کوچک تر تقسیم کرده و هر قسمت را به یکی از کامپیوترهای متصل به شبکه ارجاع میدهد. در نهایت، نتایج پردازش هر یک از قسمت ها، توسط کامپیوترهای کوچک تر جمعآوری شده و حاصل نهایی پردازش را شکل میدهند.
تاریخچه
هدوپ توسط Doug Cutting سازنده Apache Lucene که به صورت گسترده برای عملیات جستجوی متن ها استفاده می شود، تولید شد. در حقیقت به وجود آمدن هدوپ از کار بر روی Nutch شروع شد. Apache Nutch یک framWork متن باز برای ایجاد موتور جستجو است که به صورت گسترده، عملیات جستجوی متن ها را به روشی که خزیدن یا Crawling نام گرفت انجام می دهد.
در خصوص نامگذاری نام هدوپ (HADOOP) باید گفت که مخفف عبارت خاصی نیست، این نامی است که پسر Doug برروی عروسک فیل خود که زرد رنگ بود گذاشته بود.
برای شروع، Doug و همکارش Mike ایده ساختن یک موتور جستجوگر وب را در سر داشتند اما این تنها چالش آنها نبود، قیمت سخت افزار یک موتور جستجوگر که 1 میلیون صفحه وب را جستجو و index می کند، در حدود 500000 دلار بود با این وجود آنها باور داشتند که این پروژه یک هدف ارزشمند است.
Nutch در سال 2002 شروع به کار کرد و در همان زمان عملیات و روش های جستجوی صفحات وب به سرعت رشد کرد. طی زمانی معماران پروژه دریافتند که این پروژه قابلیت و توانایی کار کردن با میلیون ها صفحه وب را ندارد، در همان برهه در سال 2003 مقاله ای از شرکت گوگل منتشر شد که توانست راهگشای مشکل آنها باشد و معماری(Google File system) GFS را توصیف می کرد.
GFS توانست مشکل ذخیره سازی داده های عظیم را حل کند علاوه بر آن مدیریت ذخیره سازی گره ها دیگر چالشی بود که در معماری های قبلی بود و با استفاده از این روش آن مشکل نیز برطرف شد. در سال 2004 تیم Nutch توانست نسخه متن باز خود را با نام Nutch Distributed filesystem(NDFS) منتشر کنند. در سال 2004 گوگل با مقاله ای MapReduce را به جهان معرفی کرد، خیلی زود در سال 2005 برنامه نویسان Nutch شروع به کار با (MR)MapReduce کردند و تا اواسط همان سال Nutch نسخه جدید خود را که با NDFS و MR کار می کرد به جهان معرفی کرد. بعد از چندی معماران Nutch دریافتند که عملکرد آن فراتر از فقط یک موتور جستجوگر است و در فوریه 2006 آنها از پروژه Nutch که خود زیر پروژه Lucene به حساب می آمد به سمت پروژه ای آمدند که آن را Hadoop (هدوپ) نامیدند. در تقریبا همان سال Doug به Yahoo پیوست تا با استفاده از یک تیم مستقل هدوپ را آزمایش و پیاده سازی کند.
در سال 2008 شرکت یاهو، موتور جستجویی را معرفی کرد که توسط 10000 کلاستر هدوپ عملیات جستجو را انجام می داد. در همان سال و در ماه ژانویه هدوپ در بالاترین سطح پروژه های Apache قرار گرفت در آن زمان دیگر تنها Yahoo استفاده کننده این محصول نبود، شرکت هایی نظیر Last.fm، Facebook و New York Times نیز شروع به فعالیت در این حوزه کرده بودند.
در همان سال New York Times تعداد زیادی از روزنامه های خود را که در قسمت آرشیو وجود داشت اسکن کرد که حجم آن نزدیک به 4 ترابایت داده می شد و سپس با استفاده از پردازش ابری EC2 آمازون و با استفاده از 100 ماشین در کمتر از 24 ساعت پردازش خود را به پایان برساند.
در April سال 2008 هدوپ رکورد جهان را شکست و سریعترین سیستمی شد که توانست 1 ترابایت داده را ظرف 202 ثانیه و با استفاده از 910 node کلاستر پردازش کند. این رکورد در سال قبل با 297 ثانیه ثبت شده بود. در November همان سال گوگل طی گزارشی اعلام کرد که این رکورد را به 68 ثانیه ارتقاء داده است. در April 2009 یاهو اعلام کرد با استفاده از هدوپ توانسته 1 ترابایت داده را ظرف 62 ثانیه پردازش کند؛ و بالاخره در سال 2014 یک تیم از شرکت DataBricks اعلام کرد که توانسته با استفاده از 207 node کلاستر اسپارک حدود 100 ترابایت داده را ظرف 1406 ثانیه که تقریبا 4.27 ترابایت در دقیقه می شود پردازش کند.
امروزه هدوپ به صورت وسیعی و در زمینه های بسیاری از فعالیت های دانشگاهی تا تجارت، از علوم تا نجوم، مورد استفاده قرار می گیرد. هدوپ مکانی امن برای ذخیره و تحلیل داده های کلان به شمار می رود، مقیاس پذیر، توسعه پذیر و متن باز است. هدوپ هدف اصلی کمپانی های بزرگ تولید و ذخیره داده از جمله Facebook، IBM، EMC، Oracle و Microsoft است.
از کمپانی های متخصص در زمینه سرویس های هدوپ می توان به MapR، Cloudera و HortonWorks اشاره کرد.
بهتر است که بدانیم هدوپ چه چیزی نیست:
- هدوپ پایگاه داده نیست.
- هدوپ یک نرم افزار نیست.
به طور خلاصه، هدوپ یک framework یا مجموعه ای از نرم افزارها و کتابخانه هایی است که ساز و کار پردازش حجم عظیمی از داده های توزیع شده را فراهم می کند. در واقع Hadoop را می توان به یک سیستم عامل تشبیه کرد که طراحی شده تا بتواند حجم زیادی از داده ها را بر روی ماشین های مختلف پردازش و مدیریت کند. فریم ورک هدوپ شامل زیرپروژه های مختلفی می شود که در زیر، لیست کامل آنها آمده است:
- HDFS
- YARN
- MapReduce
- Ambari
- Avro
- Cassandra
- Chukwa
- HBase
- Hive
- Mahout
- Pig
- Spark
- Tez
- ZooKeeper

هسته اصلی هدوپ از یک بخش ذخیره سازی (سیستم فایل توزیع شده هدوپ یا HDFS) و یک بخش پردازش (Map/Reduce) تشکیل شده است. هدوپ، فایل ها را به بلاک های بزرگ شکسته و آنها را بین node های یک خوشه توزیع می کند. برای پردازش داده، بخش Map/Reduce بسته کدی را برای node ها ارسال می کند تا پردازش را به صورت موازی انجام دهند. این رویکرد از محلیت داده بهره میبرد (node ها بر روی بخشی از داده کار میکنند که در دسترشان قرار دارد). بدین ترتیب داده ها سریع تر و کاراتر از وقتی که از یک معماری متکی بر ابر-رایانه که از سیستم فایل موازی استفاده کرده و محاسبه و داده را از طریق یک شبکه پر سرعت به هم وصل میکند، پردازش میشوند. Framework هدوپ به زبان جاوا نوشته شده است، اما از زبان C و همچنین از shell script نیز در بخش هایی از آن بهره گرفته شده است. کاربران نهایی می توانند در کار با هدوپ، هر زبان برنامه نویسیی را برای پیاده سازی بخش های “map” و “reduce” به کار ببرند.
Framework هدوپ
Framework اصلی هدوپ از ماژول های زیر تشکیل شده است:
- بخش مشترکات هدوپ: شامل کتابخانه ها و utility های لازم توسط دیگر ماژول های هدوپ است.
- سیستم فایل توزیع شده هدوپ (HDFS): یک سیستم فایل توزیع شده است که داده را بر روی ماشین های خوشه ذخیره کرده و پهنای باند وسیعی را به وجود میآورد.
- YARN هدوپ: یک پلتفرم مدیریت منابع که مسئول مدیریت منابع محاسباتی در خوشه ها است.
- Map/Reduce هدوپ: یک مدل برنامه نویسی برای پردازش داده در مقیاس های بالا است.
- در واقع هدوپ یک سیستم فایل توزیع شده تهیه می کند که می تواند داده را بر روی هزاران سرور ذخیره کند و وظیفه را بر روی این ماشین ها پخش کرده (کارهای Map/Reduce) و کار را در کنار داده انجام میدهد.
همچنين، هدوپ از کاربردهای پایه اي مانند Indexing یا رابط هاي SQL پشتیبانی نمیکند، اما در این زمینه، چند پروژه open source برای فعال سازی این امکانات در هدوپ آغاز شده است.
Map/Reduce
در هدوپ، مفهوم Map/Reduce به صورت ارباب-برده (Master-Slave) اجرا مي شود. در این مجموعه، یک سرور Master وجود دارد که با نام Job Tracker شناخته مي شود و تعدادی سرور Slave که با نام Task Tracker مشخص مي شوند و به ازای هر node در یک خوشه، یکی از آنها وجود دارد. ماشین Job Tracker نقطه برقراری ارتباط کاربر و کل framework است. در این سیستم، کاربر وظایف توزیع و تجمیع خود را به ماشین Job Tracker تحویل داده و این ماشین وظایف را براساس اصلFCFS (هر که سریع تر آمده، سریع تر اجرا می شود)، روی صفی از وظایف منتظر اجرا قرار داده و به ماشین هاي slave مي فرستد. ماشین Job Tracker مدیریت و نحوه تخصیص عملیات توزیع و تجمیع به Task Tracker ها و همچنین مبادلات داده اي میان آن ها و میان عمليات دوگانه توزیع و تجمیع را بر عهده دارد. توجه كنيد که به دلیل عدم انجام عملیات به روزرسانی و پردازش تراکنش ها، هدوپ را نمی توان یک پایگاه داده به شمار آورد.
در مثال زیر هدف شمارش کلمات است به این ترتیب که ابتدا دیتا به چند قسمت تقسیم می شود و به نود های مختلف تحویل داده می شود در این مرحله عملیات Map انجام شده و هر کلمه پس از اینکه نشانه گذاری یا همان Tokenize شد. به صورت یک Key-value در می آید. سپس در مرحله بعد باید عملیات Reduce انجام شود که در آن کار تجمیع توسط نود های reducer انجام می شود.

HDFS هدوپ
سیستم فایل توزیع شده هدوپ برای ذخیره مطمئن فایل های بسیار بزرگ بر روی ماشین های یک خوشه بزرگ طراحی شده است. این فایل سیستم الهام گرفته شده از فایل سیستم گوگل می باشد. HDFS هر فایل را به صورت یک دنباله ازبلاک ها ذخیره میکند که تمام بلاک های موجود در یک فایل به غیر از آخرین بلاک، هم اندازه هستند.
معماری HDFS هدوپ
همچون Map/Reduce هدوپ، HDFS دارای یک معماری ارباب/برده است. ساختار HDFS شامل یک Namenode (گره نام) است که یک سرور ارباب بوده و NameSpace فایل سیستم را مدیریت کرده و دسترسی به فایل ها توسط کلاینت ها را تنظیم می کند. به علاوه، تعدادی DataNode (گره داده) نیز وجود دارد، یکی به ازای هر گره در خوشه که مخزن اختصاصی به گره ها که بر روی آن اجرا میشوند را مدیریت می کند. Namenode ها عملیاتی همچون باز کردن، بستن و تغییر نام فایل ها و دایرکتوری ها را از طریق یک واسط RPC برای NameSpace فایل سیستم ممکن می کنند و همچنین map بلاک ها را به data-node ها معین می کنند. Data-node ها مسئول انجام خدمات مربوط به درخواست های خواندن و نوشتن رسیده از طرف کلاینت های فایل سیستم هستند. همچنین تولید، حذف و ایجاد کپی ازبلاک ها را بر حسب دستورالعمل Namenode انجام می دهند

نحوه ذخیره سازی فایل هاي روی HDFS – توزیع بلاک های هر فایل روی چندین node در شبکه

تاریخچه اسپارک
اسپارک یک موتور پردازش داده است که اولین بار در سال 2009 به عنوان یک پروژه در آزمایشگاه AMP دانشگاه کالیفرنیا، برکلی طراحی شد. سپس در سال 2013 به یک پروژه انحصاری از بنیاد نرم افزاری آپاچی تبدیل شده و در اوایل سال 2014 میلادی به یکی از پروژه های برتر بنیاد ارتقا یافت. اسپارک در حال حاضر یکی از فعال ترین پروژه های آپاچی است و شرکت هایی مانند Databricks، IBM و China Huawei از اسپارک حمایت مالی می کنند.
ویژگی ها
برخی ویژگی های منحصر به فرد اسپارک موجب شده است که این برنامه نسبت به برخی دیگر از گزینه های مشابه هدوپ برای پردازش داده ها مانند برنامه Map/Reduce بهتر عمل کند. در واقع می توان گفت که اسپارک از همان ابتدا به گونه ای طراحی و بهینه شده بود که عملیات پردازش را در حافظه انجام دهد و این مزیت نسبت به برنامه Map/Reduce که داده ها را بر روی دیسک نوشته و از روی دیسک نیز برای پردازش فراخوانی می کند موجب سرعت فوق العاده بالاتری شده است. طرفداران اسپارک معتقدند که سرعت پردازش اسپارک 10 تا 100 برابر از Map/Reduce بالاتر است.
اسپارک قادر است چندین پتابایت داده را که بر روی خوشه هایی از هزاران سرور فیزیکی یا مجازی توزیع شدهاند پردازش نماید. چندین زبان برنامه نویسی مانند java، phyton، R و Scala را پشتیبانی نموده و علاوه بر بستر ذخیره سازی داده های هدوپ (HDFS) قادر است با سایر منابع ذخیره سازی مانند HBase، Cassandra، Mongo و S3 آمازون نیز کار کند.
RDD ، مجموعه داده های توزیع شده برگشت پذیر
نقطه قوت اصلی اسپارک استفاده از مجموعه داده های توزیع شده برگشت پذیر یا RDD است. تمام داده ها در اسپارک برای پردازش باید به شکل RDD در آیند که البته به کمک توابع خود اسپارک این امر به راحتی امکان پذیر است. RDD ها فقط خواندنی هستند و با هر تراکنش جدیدی که روی یک مجموعه داده برگشت پذیر انجام می شود یک RDD جدید ساخته می شود و محاسبات با این مجموعه جدید ادامه پیدا می کند. دو نوع کار می توان روی این مجموعه داده ها انجام داد:
- تبدیلات: عمل تبدیل یک RDD را به یک RDD جدید تبدیل می کند؛ مانند فیلتر کردن و انجام یک تابع سراسری روی تک تک عناصر (map)
- عملیات: منظور از عملیات، توابعی است که روی یک RDD اعمال می شود و یک مقدار را بر می گرداند؛ مثلا شمارش عناصر، بیشینه یا کمینه عناصر
نکته مهم در مورد اسپارک این است که هر RDD اشاره گری به مجموعه داده پدر خود به همراه عمل انجام گرفته برای تبدیل را داراست و برگشت پذیر بودن این مجموعه ها هم دقیقاً به همین روال اشاره دارد چون با داشتن مجموعه داده اولیه و مجموعه تبدیلات انجام گرفته روی آن، می توان به راحتی یک مجموعه را از پایه دوباره ساخت و اگر سیستم به هر دلیلی مجموعه داده فعلی خود را از دست داد، به راحتی آن را با پیمایش زنجیره تبدیلات از اولین مجموعه تا الان می تواند بازیابی کند بنابراین RDD ها برگشت پذیر هستند.
موارد کاربرد
- پردازش داده های در جریان:
امروزه با داده هایی مواجه هستیم که مدام در حال تولید و تغییر هستند. اگرچه می توان این داده ها را ذخیره نموده و بعد پردازش کنیم اما گاهی اوقات مانند داده های مالی و داده های حاصل از حسگرهای دستگاه ها را می بایست در لحظه پردازش نمود تا بتوان به موقع به ارزش موجود در آنها دست یافت. اسپارک این قابلیت را به خوبی ایفا میکند.
- یادگیری ماشین:
توانایی اسپارک برای ذخیره داده ها در حافظه موقت و اجرای پردازش ها و جستارهای تکراری آن را برای پیکربندی الگوریتم های یادگیری ماشین مناسب ساخته تا بتوان مجموعه فعالیت های تکراری را به راحتی و با سرعت بالا بر روی داده های جدید و عظیم نیز اجرا کرد.
- تجزیه و تحلیل تعاملی داده های در جریان:
سیستمی مانند اسپارک با ویژگی پاسخ سریع به تغییرات آن را قادر ساخته که بجای یک سری داده ها و جستارهای ثابت و تکراری که نمودارهای مربوطه را بر روی داشبوردها نمایش می دهد بتوان تغییراتی به دلخواه در این جستارها اعمال کرده و پاسخ این تغییرات را به سرعت بر روی داشبورد مشاهده کرد.
- یکپارچه سازی داده ها:
داده های کسب و کار معمولا از منابع مختلف و با انواع گوناگون تولید می شوند و نیازمند پاکسازی برای استفاده مناسب هستند. در واقع اسپارک با ویژگی های فوق العاده خود هزینه عملیات استخراج، تبدیل و بارگذاری و استفاده از این داده ها را کاهش داده و سرعت این عملیات را نیز افزایش داده است.
مقایسه اسپارک و هدوپ
این سوال شاید از ابتدا اشتباه باشد، هر تکنولوژی را باید با توجه به نیازمندی های پروژه استفاده کرد، همچنین این دو تکنولوژی می توانند مکمل همدیگر باشند.
به این صورت که اسپارک هم می تواند در هدوپ مورد استفاده قرار گیرد و داده های خود را از HDFS بخواند و در آن هم ذخیره کند و برای مدیریت خوشه یا شبکه هم از YARN کمک بگیرد؛ یعنی این دو مدل پردازشی مکمل هم هستند و می توانیم اسپارک را به یک اسب و هدوپ و مکانیزم MapReduce آن را به یک فیل تشبیه کنیم. درست است که اسب همه جا سریعتر از فیل حرکت می کند اما گاهی اوقات ما به قدرت فیل نیاز داریم. مثلاً اگر حجم داده ها بالا و میزان حافظه ما کم باشد، شاید همان مکانیزم MapReduce برایمان مناسب تر باشد. با این حال نگاهی به تفاوت های این دو می اندازیم
پردازش داده ها
پردازش به دو دسته تقسیم می شوند
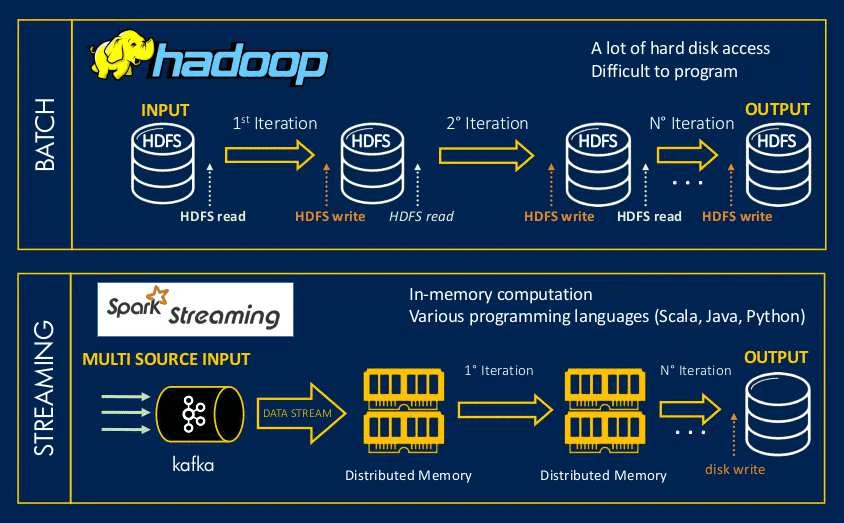
- پردازش گروهی(Batch Processing) : پردازش دسته ای یک روش کارآمد پردازش مجموعه ی داده های استاتیک است. به طور کلی، ما پردازش گروهی را برای مجموعه داده های آرشیو انجام می دهیم. برای مثال، محاسبه درآمد متوسط یک کشور یا ارزیابی تغییر در تجارت الکترونیک در دهه گذشته. هدوپ از پردازش گروهی استفاده می کند.
- پردازش همزمان و جاری (Stream processing): پردازش همزمان و جاری شایع (Trend) هم اکنون جامعه big data می باشد. نیاز به ساعت، سرعت و اطلاعات بدون اتلاف وقت است. اسپارک از پردازش همزمان و جاری استفاده می کند.
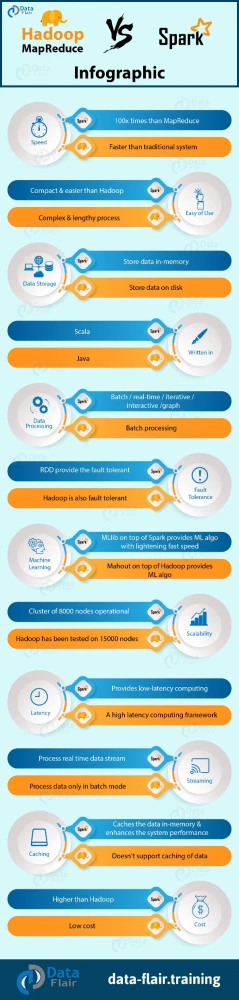
سرعت
سرعت اسپارک 10 تا 100 برابر هدوپ می باشد، به این دلیل که پردازش در memory اتفاق می افتد، همچنین می تواند از disk برای داده هایی استفاده کند که برای memory مناسب نیستند. تقریبا می توان گفت پردازش در اسپارک به صورت real-time اتفاق می افتد.
استفاده های مناسب اسپارک در این زمینه مثلا: سیستم کارت های اعتباری، machine learning
هدوپ برای جمع آوری اطلاعات از منابع مختلف بدون نگرانی در مورد نوع داده و ذخیره آن در محل های توزیع شده، راه اندازی شده است. فناوری MapReduce از پردازش گروهی استفاده می کند. این فناوری مناسب برای real time بودن نیست.
مشکل مقایسه اینجاست که این دو، نوع پردازش ها را به صورت متفاوت انجام می دهند.
سهولت استفاده:
اسپارک api های خوبی برای زبان های Scala, Java, Python, Spark SQL دارد، spark sql بسیار شبیه sql است.
هزینه:
هر دو فناوری، پروژه های open source هستند و هزینه ای ندارند تنها هزینه مرتبط با زیر ساخت می باشد. ذخیره و پردازش در هدوپ براساس دیسک است و هدوپ از مقادیر استاندارد memory نیز استفاده می کند. پس برای هدوپ ما نیازمند فضای دیسک زیاد و دیسک های سریع داریم، همچنین هدوپ برای توزیع i/o نیازمند چند سیستم می باشد.
اسپارک نیازمند memory زیادی است ولی می تواند با سرعت استاندارد و مقداری دیسک نیز کنار بیاید
از انجایی که دیسک ارزانتر از memory می باشد و از انجا که اسپارک از i/o برای پردازش استفاده نمی کند و بجای آن نیازمند مقادیر زیادی ram برای اجرا در memory می باشد، پس اسپارک هزینه بیشتری دارد.
یک نکته مهم که باید در ذهن داشته باشید این است که اسپارک، تعداد سیستم های مورد نیاز را کاهش می دهد. این سیستم به سیستم های بسیار کمتری نیاز دارد که هزینه بیشتری داشته باشد؛ بنابراین، یک نقطه وجود دارد که در آن اسپارک هزینه ها به ازای هر واحد محاسبات، حتی با نیاز رم اضافی، کاهش مییابد.
Fault Tolerance(تحمل خطا)
هر دو انجام می دهند ولی با رویکردهای مختلف چرا که اسپارک برای رفع خطا نیازی به راه اندازی مجدد ندارد.
امنیت
هدوپ از Kerberos برای تایید هویت پشتیبانی میکند، اما کنترل آن دشوار است. با این وجود، از فروشندگان شخص ثالث مانند LDAP (Lightweight Directory Access Protocol) برای احراز هویت پشتیبانی میکند. آنها همچنین رمزگذاری را پیشنهاد میکنند (encryption). HDFS از مجوزهای فایل سنتی و همچنین لیست های کنترل دسترسی پشتیبانی میکند (ACLs). هدوپ سطح اجازه ای را ارائه میدهد که تضمین می کند که مشتری ها سطوح دسترسی مناسب را برای ارایه کارها دارند.
Spark در حال حاضر از اعتبار سنجی از طریق یک sharedsecret پشتیبانی می کند. Spark می تواند با HDFS ادغام شود و از HDFS ACLs و مجوزهای سطح فایل استفاده کند. علاوه بر این، Spark می تواند با استفاده از اجرا Kerberos به قابلیت استفاده از توانایی Kerberos ادامه دهد.
عکس بعدی یک مقایسه ی کلی از این دو تکنولوژی ارائه می دهد.