
برای درک بهتر مفهوم این مقاله، در ابتدا سعی کرده ایم تا از زندگی واقعی مثالی برای آن آماده کنیم.
من عادت دارم از مباحثی فنی که مطالعه می کنم در لپ تاپ شخصیم، یادداشت برداری کنم. این کار کمکم می کند تا در آینده به یاد آوردن مباحث خوانده شده برایم راحت تر باشد. اما گاهی اوقات نگران دزدیده شدن لپ تاپ خود یا خراب شدن آن می شدم که به سبب آن اطلاعاتم در معرض خطر قرار می گرفتند! بنابراین برای رفع این نگرانی شروع به پشتیبان گیری از اطلاعاتم در یک حافظه خارجی کردم. همچنین برای اطمینان بیشتر یک اکانت Dropbox هم ساختم تا یک نسخه دیگر از اطلاعاتم را درون آن ذخیره کنم.
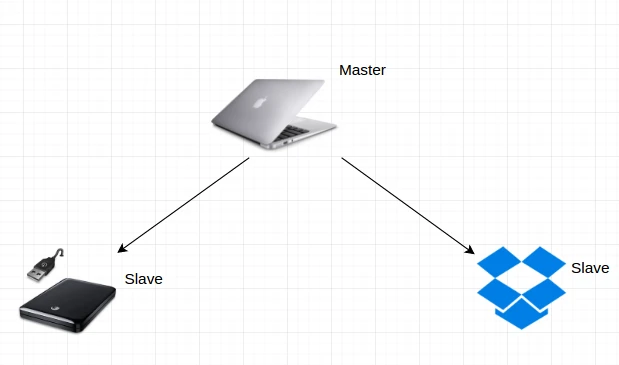
هر2 هفته یک بار هارد خود را با اطلاعات تازه نوشته شده در لپ تاپ خود به روز رسانی می کنم و همچنین به محض اتصال به اینترنت، Dropbox هم به روز می شود.
در اینجا من از حافظه خارجی و Drop box به عنوان منابعی برای خواندن اطلاعاتم استفاده می کنم در حالی که از لپ تاپ خود برای خواندن و همچنین نوشتن اطلاعات جدید استفاده می کنم. (معماری Master-slave)
به صورت کلی در شرایطی که از چندین پایگاه داده برای ذخیره داده هایمان استفاده می کنیم، اگر درخواستی مبنی بر نوشتن اطلاعات به یکی از پایگاه های داده ارسال شود، بایستی یک استراتژی وجود داشته باشد که بعد از نوشته شدن این اطلاعات در یک نسخه، تمامی نسخه های دیگر هم این اطلاعات را به روز بشوند. که این استراتژی به صورت کلی به دو قسم تقسیم می شود:
- Eventual consistency
- Strong consistency
مدل Eventual Consistency
این مدل اطمینان می دهد که در صورت اضافه شدن داده ی جدید به یکی از پایگاه های داده، به صورت رویداد محور تمامی نسخه ها با نسخه فعلی سازگار شود. استفاده از روش رویداد محور (Event based) ممکن است باعث به وجود آمدن وقفه در به روز شدن هم زمان تمامی نسخه ها شود. یعنی ممکن است بعد از ذخیره شدن داده جدید، نسخه های دیگر همچنان داده های قدیمی را نگهداری کنند چون در این روش معمولا از صف ها برای همگام سازی نسخه های دیگر استفاده می کنند. شکل زیر بازگو کننده این روش است.
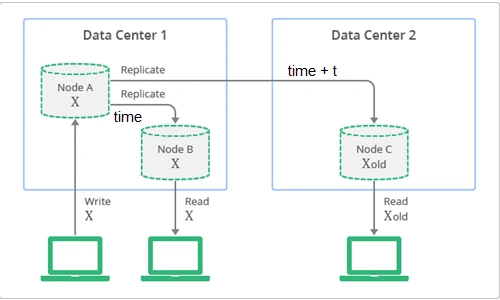
شکل 1-1
با توجه به شکل 1-1 بعد از ایجاد درخواست درج X، درخواست های همگام سازی به گره های B و C ارسال می شود. در این حین درخواستی برای خواندن اطلاعات به گره های B و C ارسال می شود که در اینجا گره B به دلیل زودتر همگام شدن نسبت به گره C مقدار X را برمی گرداند اما گره C همچنان دارای مقدار قدیمی X است.
اگر بخواهیم این روش را در داستانی که پیش تر تعریف کردیم مدل کنیم:
یکی از دوستان من، قصد گرفتن هاردم را برای خواندن اطلاعاتی که یادداشت کرده ام، دارد. چون هر دوهفته یکبار من اطلاعات حافظه ی جانبی ام را با لپ تاپ خود همگام سازی (sync) می کنم بنابراین به دوست خود می گویم اطلاعات هارد من مربوط به دو هفته پیش است، آیا مشکلی با این قضیه نداری؟ و دوست من می گوید نه مشکلی نیست و بدون هیچ معطلی می تواند هارد من را قرض بگیرد. (low latency)
منظور از low latency یعنی درخواستی که برای خواندن اطلاعات به یک گره ارسال می شود، بدون هیچ معطلی پاسخ آن آنداده شود و درخواست دهنده اطلاعات را دریافت کند.
به صورت کلی روش Eventual consistency تاخیر کم در ارسال اطلاعات، همراه با ریسک برگشت داده های تکراری را تضمین می کند.
مدل Strong Consistency
این روش برخلاف روش قبلی به شدت بر سر یکسان بودن اطلاعات در تمامی گره ها حساس است. و منطق آن به این صورت است که اگر داده ای جدید به یکی از نسخه ها اضافه شود، بلافاصله تمامی نسخه های دیگر هم بایستی این اطلاعات را شامل شوند. این موضوع باعث می شود که در صورتی که در حین به روز رسانی به نسخه های دیگر درخواستی برای خواندن یا نوشتن ارسال شود، همراه با یک وقفه، آن ها پاسخ دهند.
به عبارتی هر زمان که سازگاری آن ها با نسخه های دیگر انجام شد، پاسخ درخواست هایشان را می دهند.
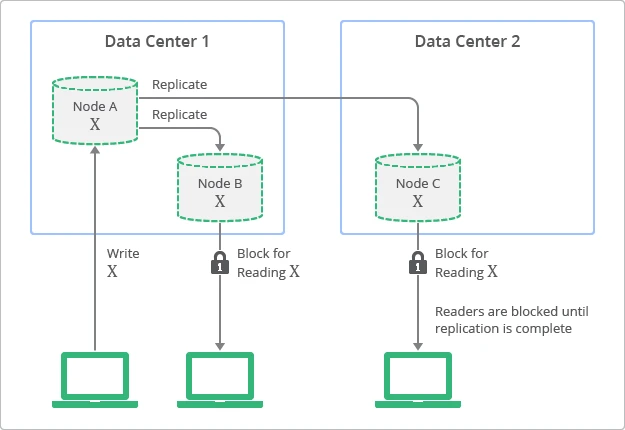
شکل 2-1
همانطور که در شکل 2-1 مشخص است بعد از ارسال درخواست همگام سازی به گره های B و C، درخواستی برای خواندن اطلاعات به گره C ارسال می شود اما چون همگام سازی این گره به صورت کامل انجام نشده لذا درخواست دهنده تا زمان همگام شدن، بایستی منتظر پاسخ درخواست خود بماند.
حال اگر بخواهیم این روش را در داستانی که تعریف کردیم مدل کنیم:
دوست من درخواست گرفتن هارد من را دارد، اما این بار به این برای که هارد من در حال همگام شدن اطلاعاتش با لپ تاپ است، بایستی زمانی را برای همگام شدن این اطلاعات صبر کند و بعد از آن می تواند هاردم را قرض بگیرد.
این روش در واقع سازگاری اطلاعات را به قیمت یک تاخیر در تمامی گره ها اطمینان می دهد.
سخن آخر
کاربرد این موضوع در معماری هایی نظیر: Microservice, CQRS و به طور کلی شرایطی که در یک نرم افزار پایگاه داده های مختلفی وجود دارد و نیاز است اطلاعات در بین این پایگاه های داده به اشتراک گذاشته شود، محسوس می شود.