در مقاله "مقیاسبندی ویژگی در پایتون" متوجه شدیم که هدف از مقیاسبندی ویژگیها این است که همه ویژگیها به طور یکسان در فرآیند یادگیری ماشین مشارکت کنند، تا ویژگی خاصی تأثیر بیشتری نسبت به بقیه نداشته باشد. همچنین بررسی کردیم که چه زمانی باید مقیاسبندی ویژگیها را انجام دهیم، چالشهای مربوط به آن چیست و چگونه از آن در یادگیری ماشین استفاده کنیم. در این بخش آموزشی، با تکنیکهای مقیاسبندی ویژگیها با استفاده از Scikit-learn آشنا خواهیم شد.
مقایسه عملکرد نرمالسازی و استانداردسازی در پایتون
اکنون به بخش سرگرمکننده رسیدیم، یعنی عملی کردن به آنچه آموختهایم. بیایید مقیاسبندی ویژگی را برای چند الگوریتم یادگیری ماشین در مجموعه دادههای Big Mart از پلتفرم DataHack، اعمال کنیم. در اینجا ما از مجموعه داده clean شده استفاده میکنیم و از مراحل پیشپردازش برای clean کردن صرف نظر میکنیم زیرا آنها خارج از محدوده این آموزش هستند. بنابراین، اجازه دهید ابتدا دادههای خود را به مجموعههای آموزشی و آزمایشی تقسیم کنیم. قبل از رفتن به بخش مقیاسبندی ویژگی، بیایید با استفاده از متد ()pd.describe به جزئیات دادههایمان نگاهی بیندازیم:
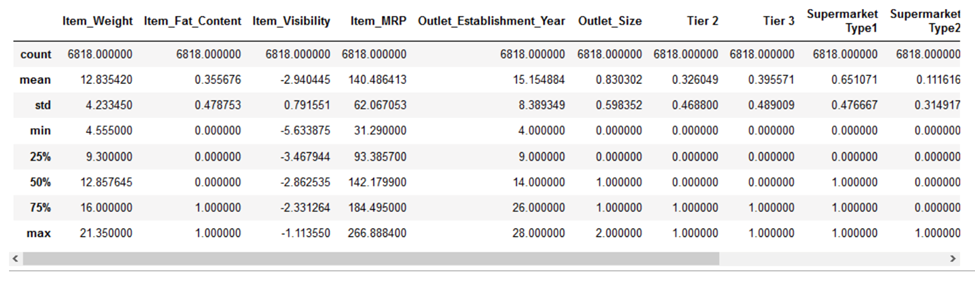
میتوانیم ببینیم که تفاوت زیادی در دامنه مقادیر موجود در ویژگیهای عددی ما وجود دارد: Item_Visibility، Item_Weight، Item_MRP و Outlet_Establishment_Year. بیایید سعی کنیم آن را با استفاده از مقیاسبندی ویژگی برطرف کنیم!
1- نرمال سازی با استفاده از sklearn
برای نرمالسازی دادههای خود، باید MinMaxScalar را از کتابخانه sklearn ایمپورت کرده و آن را به مجموعه داده اعمال کنید. بیایید این کار را انجام دهیم!
# data normalization with sklearn
from sklearn.preprocessing import MinMaxScaler
# fit scaler on training data
norm = MinMaxScaler().fit(X_train)
# transform training data
X_train_norm = norm.transform(X_train)
# transform testing dataabs
X_test_norm = norm.transform(X_test)بیایید ببینیم نرمال سازی چگونه بر مجموعه داده ما تأثیر گذاشته است:
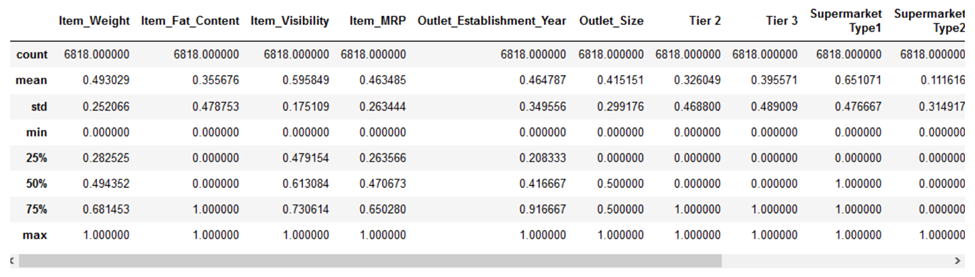
همه ویژگیها اکنون دارای حداقل مقدار ۰ و حداکثر مقدار ۱ هستند. در مرحله بعد، بیایید سعی کنیم دادههای خود را استاندارد کنیم.
2- استانداردسازی با استفاده از sklearn
برای استانداردسازی دادههای خود، باید StandardScalar را از کتابخانه sklearn ایمپورت کرده و آن را به مجموعه داده اعمال کنید. در اینجا نحوه انجام آن آمده است:
# data standardization with sklearn
from sklearn.preprocessing import StandardScaler
# copy of datasets
X_train_stand = X_train.copy()
X_test_stand = X_test.copy()
# numerical features
num_cols = ['Item_Weight','Item_Visibility','Item_MRP','Outlet_Establishment_Year']
# apply standardization on numerical features
for i in num_cols:
# fit on training data column
scale = StandardScaler().fit(X_train_stand[[i]])
# transform the training data column
X_train_stand[i] = scale.transform(X_train_stand[[i]])
# transform the testing data column
X_test_stand[i] = scale.transform(X_test_stand[[i]])حتماً متوجه شدهاید که استانداردسازی فقط برای ستونهای عددی اعمال میشود و نه ویژگیهای One-Hot Encoded. استاندارد کردن ویژگیهای One-Hot Encoded به معنای اختصاص یک توزیع به ویژگیهای طبقهبندی شده است که این کار را در این جا، انجام نمیدهیم.
اما چرا هنگام نرمالسازی دادهها این کار را نکردم؟ از آنجا که ویژگیهای One-Hot Encoded در حال حاضر در محدوده بین ۰ تا ۱ قرار دارند، بنابراین، نرمالسازی بر مقدار آنها تأثیری نخواهد داشت.
بیایید نگاهی بیندازیم که چگونه استانداردسازی دادههای ما را تغییر داده است:
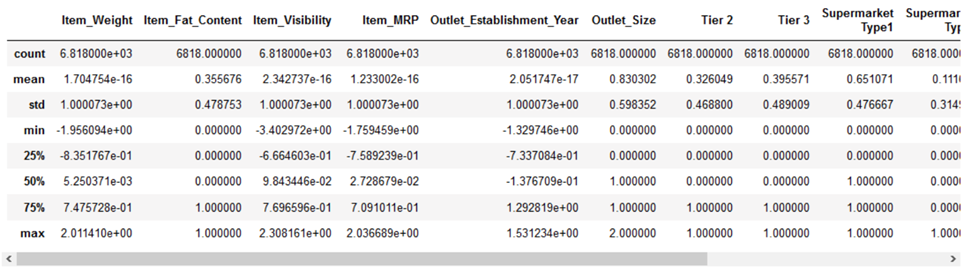
ویژگیهای عددی اکنون بر روی میانگین صفر با انحراف معیار واحد متمرکز شدهاند.
3- مقایسه دادههای مقیاس نشده، نرمالشده و استاندارد شده
تصویرسازی دادهها برای درک توزیع موجود همیشه یک روش عالی است. ما میتوانیم مقایسه بین دادههای مقیاس نشده و مقیاس شده خود را با استفاده از نمودارهای جعبهای انجام دهیم.
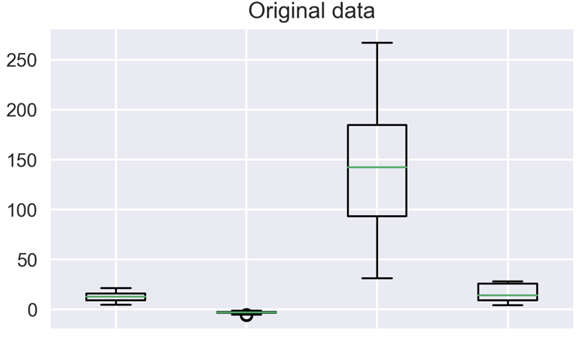
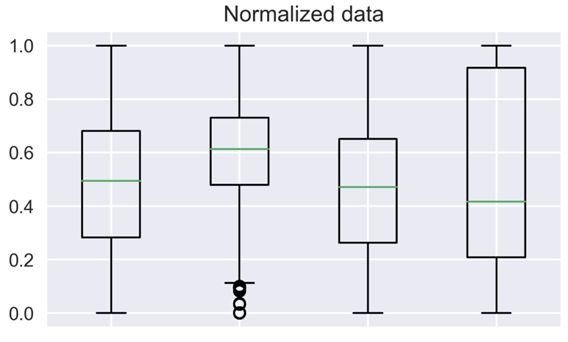
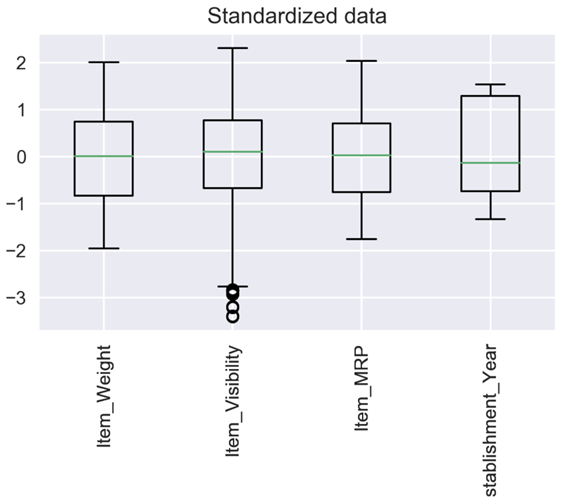
میتوانید متوجه شوید که چگونه مقیاس بندی ویژگیها همه چیز را بهتر مشخص میکند. ویژگیها اکنون قابل مقایسهتر هستند و تأثیر مشابهی روی مدلهای یادگیری خواهند داشت.
مقیاسبندی ویژگی در Sklearn با StandardScaler، MinMaxScaler، RobustScaler و MaxAbsScaler
در این بخش، نمونههایی از تکنیکهای مقیاسبندی ویژگی با Sklearn از StandardScaler، MinMaxScaler، RobustScaler و MaxAbsScaler را خواهیم دید. برای این منظور روی مجموعه داده مسکن رگرسیون انجام میدهیم و ابتدا نتایج را بدون مقیاسبندی میبینیم و سپس با اعمال مقیاسبندی ویژگیها، نتایج را با هم مقایسه میکنیم.
1- درباره مجموعه داده
مجموعه داده مورد استفاده در این بخش، مجموعه داده مسکن کالیفرنیا (California housing dataset) است که شامل ویژگیهای مختلف خانه مانند مکان، سن، تعداد اتاقها، ارزش خانه، و غیره است. هدف در این جا، پیش بینی ارزش خانه با توجه به متغیرهای ویژگی مستقل در مجموعه داده است. این مجموعه داده شامل ۲۰۴۳۳ ردیف و ۹ ستون است.
2- import کردن کتابخانههای مورد نیاز
برای شروع، اجازه دهید تمام کتابخانههای مورد نیاز برای مثالهای خود را load کنیم.
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler,MinMaxScaler,MaxAbsScaler,RobustScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import accuracy_score
from sklearn import preprocessing3- load کردن مجموعه داده
سپس مجموعه داده را در یک دیتافریم بارگذاری میکنیم و ویژگی غیر عددی ocean_proximity را حذف میکنیم. در زیر، ۱۰ ردیف بالای مجموعه داده را مشاهده میکنید.
#reading the dataset
df=pd.read_csv(r"C:\Users\Veer Kumar\Downloads\MLK internship\FeatureScaling\housing.csv")
df.drop(['ocean_proximity'],axis=1,inplace=True)
df.head(10)4- رگرسیون بدون مقیاس بندی ویژگی
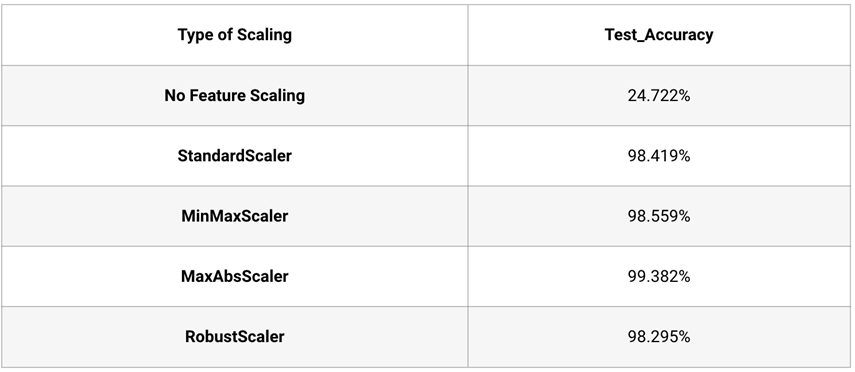
اجازه دهید ابتدا مدل رگرسیون را با KNN بدون اعمال مقیاسبندی ویژگی ایجاد کنیم. مشاهده میشود که دقت مدل رگرسیون بدون مقیاسبندی ویژگی تنها ۲۴ درصد است.
# Train Test Split
X=df.iloc[:,:-1]
y=df.iloc[:,[7]]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
# Creating Regression Model
clf = KNeighborsRegressor()
clf.fit(X_train, y_train)
# Accuracy on Tesing Data
clf.predict(X_test)
score=clf.score(X_test,y_test)
print("Accuracy for our testing dataset without Feature scaling is : {:.3f}%".format(score*100) )
خروجی:
Accuracy for our testing dataset without Feature scaling is : 24.722%5- استفاده از Sklearn StandardScaler
حال اجازه دهید مدل رگرسیون را با استفاده از مقیاسکننده استاندارد در طی پیشپردازش داده ایجاد کنیم.
ابتدا مجموعه داده را به آموزشی و آزمایشی تقسیم میکنیم. سپس یک آبجکت StandardScaler ایجاد میکنیم که با استفاده از آن مجموعه داده آموزشی را fit و transform میکنیم و سپس با همان شی، مجموعه داده آزمایشی را نیز transform میکنیم.
# Train Test Split
X=df.iloc[:,:-1]
y=df.iloc[:,[7]]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
#Creating StandardScaler Object
scaler = preprocessing.StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
#Seeing the scaled values of X_train
X_train.head()
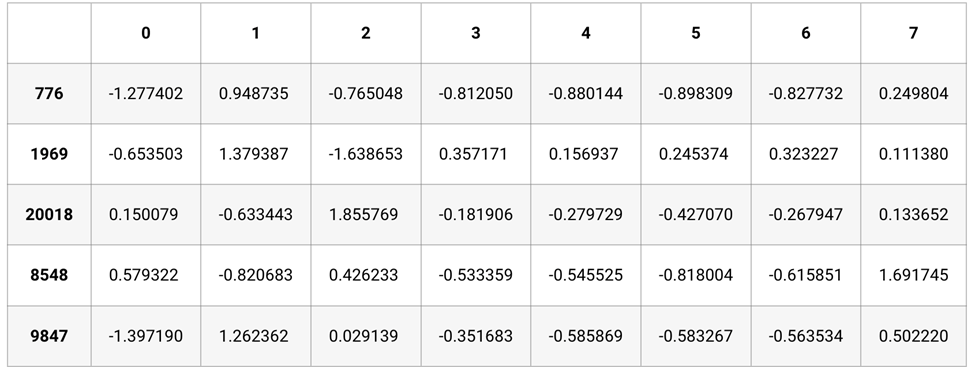
اکنون که استاندارد سازی اعمال شد، بیایید مدل رگرسیون را آموزش دهیم و دقت آن را بررسی کنیم. میتوان مشاهده کرد که دقت مدل اکنون به ۹۸.۴۱۹% میرسد که بسیار قابل توجه است.
# Creating Regression Model
model=KNeighborsRegressor()
model.fit(X_train,y_train)
# Accuracy on Tesing Data
y_test_hat=model.predict(X_test)
score=model.score(X_test,y_test)
print("Accuracy for our testing dataset using Standard Scaler is : {:.3f}%".format(score*100) )خروجی:
Accuracy for our testing dataset using Standard Scaler is : 98.419%6- استفاده از Sklearn MinMaxScaler
درست مانند قبل، یک شی MinMaxScaler ایجاد میکنیم و با استفاده از آن مجموعه داده آموزشی را fit و transform میکنیم و سپس با همان شی، مجموعه داده آزمایشی را transform میکنیم.
# Train Test Split
X=df.iloc[:,:-1]
y=df.iloc[:,[7]]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
#Creating MinMax Object
mm = preprocessing.MinMaxScaler()
X_train = mm.fit_transform(X_train)
X_test = mm.transform(X_test)
#Seeing the scaled values of X_train
X_train.head()
اکنون از این دادههای مقیاس شده برای ایجاد مدل رگرسیون استفاده میکنیم و مجدداً مشاهده میکنیم که به دقت بسیار خوب ۹۸.۵۵٪ میرسیم.
# Creating Regression Model
model=KNeighborsRegressor()
model.fit(X_train,y_train)
# Accuracy on Tesing Data
y_test_hat=model.predict(X_test)
score=model.score(X_test,y_test)
print("Accuracy for our testing dataset using MinMax Scaler is : {:.3f}%".format(score*100) )
خروجی:
Accuracy for our testing dataset using MinMax Scaler is : 98.559%7- استفاده از MaxAbsScaler در Sklearn
یک شی MaxAbsScaler ایجاد میکنیم و سپس روش fit_transform را روی مجموعه داده آموزشی اعمال میکنیم و سپس مجموعه داده آزمایشی را با همان شی transform میکنیم.
# Train Test Split
X=df.iloc[:,:-1]
y=df.iloc[:,[7]]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
#Creating MaxAbsScaler Object
mab=MaxAbsScaler()
X_train = mab.fit_transform(X_train)
X_test = mab.transform(X_test)در مرحله بعد، مدل رگرسیون KNN را با استفاده از دادههای مقیاس شده ایجاد می کنیم و مشاهده میکنیم که دقت آزمون به ۹۹.۳۸٪ میرسد.
# Creating Regression Model
model=KNeighborsRegressor()
model.fit(X_train,y_train)
# Accuracy on Tesing Data
y_test_hat=model.predict(X_test)
score=model.score(X_test,y_test)
print("Accuracy for our testing dataset using MinMax Scaler is : {:.3f}%".format(score*100) )خروجی:
Accuracy for our testing dataset using MaxAbs Scaler is : 99.382%8- استفاده از RobustScaler در Sklearn
یک شی RobustScaler ایجاد میکنیم و سپس متد fit_transform را روی مجموعه داده آموزشی اعمال میکنیم و سپس مجموعه داده آزمایشی را با همان شی transform میکنیم.
# Train Test Split
X=df.iloc[:,:-1]
y=df.iloc[:,[7]]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
#Creating RobustScaler Object
rob =RobustScaler()
X_train = rob.fit_transform(X_train)
X_test = rob.transform(X_test)در نهایت، مدل رگرسیون را ایجاد میکنیم و به دقت ۹۸.۲۹۵٪ دست مییابیم.
# Creating Regression Model
model=KNeighborsRegressor()
model.fit(X_train,y_train)
# Accuracy on Tesing Data
y_test_hat=model.predict(X_test)
score=model.score(X_test,y_test)
print("Accuracy for our testing dataset using MinMax Scaler is : {:.3f}%".format(score*100) )خروجی:
Accuracy for our testing dataset using Robust Scaler is : 98.295%خلاصه
از مشاهدات زیر، کاملاً مشهود است که مقیاس بندی ویژگی یک مرحله بسیار مهم در پیش پردازش دادهها قبل از ایجاد مدل ML است. همانطور که در این بخش دیدیم، بدون مقیاسبندی ویژگی، دقت بسیار ضعیف بود ولی پس از اعمال تکنیکهای مختلف مقیاسبندی ویژگی، دقت آزمون به بالای ۹۸ درصد رسید.