

در دنیای دادهها، یکی از پرسشهای ابتدایی و کلیدی که هر تحلیلگر با آن روبهرو میشود این است: رابطه بین دو متغیر چیست و چگونه میتوان پیشبینی کرد؟
رگرسیون، بهعنوان یکی از قدرتمندترین و در عین حال سادهترین روشهای مدلسازی آماری، پاسخ دقیقی به این سؤال میدهد. با کمک رگرسیون میتوانیم تغییر یک متغیر مستقل را تحلیل کنیم و اثر آن را روی متغیر وابسته مشاهده کنیم.
در این دوره، تمرکز ما بر رگرسیون خطی ساده (Simple Linear Regression) بهعنوان دروازه ورود به دنیای مدلسازی آماری خواهد بود و در فصل پایانی به رگرسیون لاجستیک ساده (Simple Logistic Regression) خواهیم پرداخت در طول این جلسه، شما با متغیر وابسته و مستقل، مدل خطی و غیرخطی، رگرسیون چندگانه و دستهبندی (Classification) آشنا میشوید و پایهای محکم برای یادگیری مدلهای پیشرفتهتر در آینده خواهید ساخت.
آشنایی با مفهوم رگرسیون
در این قسمت از آموزش، قصد داریم دربارهی رگرسیون صحبت کنیم.
فرض کنید یک مجموعهداده در اختیار داریم که شامل چند ستون اطلاعاتی است؛ برای مثال، دو، سه یا چهار ستون داده مختلف، مشابه دیتاستی که در اینجا مشاهده میکنید.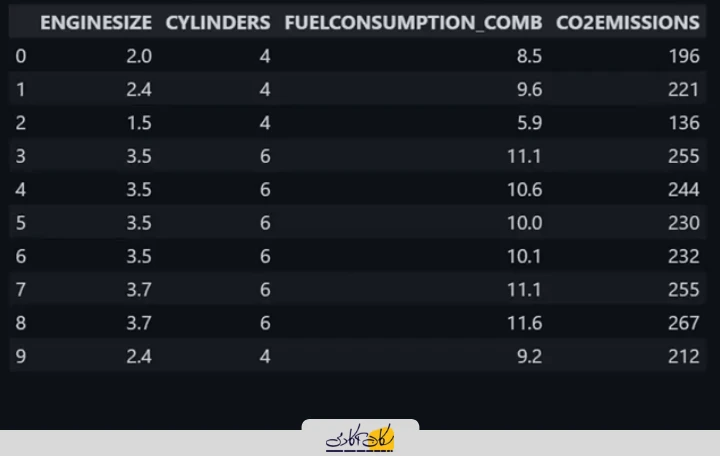
این مجموعهداده شامل اطلاعات مربوط به تعدادی خودرو است که در آن، تنها چند ویژگی مشخص انتخاب شدهاند، از جمله:
- اندازه موتور (Engine Size)
- تعداد سیلندرها (Cylinders)
- میزان مصرف سوخت ترکیبی (Fuel Consumption)
- میزان انتشار دیاکسید کربن (CO₂ Emissions)
در این دیتاست، سه متغیر اول بهگونهای هستند که افزایش یا کاهش آنها میتواند بر متغیر چهارم، یعنی میزان انتشار CO₂ تأثیر بگذارد. هدف از جمعآوری این مجموعهداده، بررسی تأثیر متغیرهای مختلف موجود در یک خودرو بر میزان تولید دیاکسید کربن است. به بیان دیگر، ما میخواهیم تحلیل کنیم که ویژگیهایی مانند اندازه موتور، تعداد سیلندرها و مصرف سوخت، چگونه و تا چه اندازه بر میزان انتشار CO₂ اثرگذار هستند.
متغیر وابسته
در این مسئله:
- متغیر هدف یا همان متغیری که قصد بررسی، تحلیل یا حتی تخمین آن را داریم، میزان تولید
CO₂است. - متغیرهایی مانند اندازه موتور، تعداد سیلندر و مصرف سوخت، متغیرهایی هستند که بر این مقدار تأثیر میگذارند.
در ریاضیات و مباحث رگرسیون، به متغیری که میخواهیم تغییرات آن را بررسی یا مقدار آن را پیشبینی کنیم، متغیر وابسته گفته میشود.
متغیر پاسخ (Response Variable)
از آنجایی که مقدار انتشار CO₂ به سه متغیر اول وابسته است، در منطق ریاضی و آمار به متغیری که قصد بررسی یا تحلیل آن را داریم، متغیر پاسخ یا Response Variable گفته میشود. این متغیر همان هدف اصلی ما در مسئله است.
متغیرهای توضیحی (Explanatory Variables)
به متغیرهایی که با تغییر آنها مقدار متغیر پاسخ نیز تغییر میکند، متغیرهای توضیحی یا Explanatory Variables گفته میشود. این متغیرها میتوانند:
- تنها یک متغیر باشند؛ برای مثال، زمانی که فقط تأثیر اندازه موتور را بررسی میکنیم،
- یا شامل چندین متغیر باشند؛ که در ادامهی آموزش به تفاوتها و مفاهیم آنها خواهیم پرداخت.
نکتهی مهم این است که در مسائل رگرسیون، متغیر پاسخ همواره یک متغیر واحد است؛ برای مثال، در اینجا تنها هدف ما بررسی میزان انتشار CO₂ است.
متغیر پیوسته
مقدار عددی پیوسته به متغیری گفته میشود که میتواند هر مقداری را در یک بازهی مشخص اختیار کند. برای نمونه، میزان انتشار CO₂ میتواند مقداری بین صفر تا ۳۰۰ داشته باشد و علاوه بر اعداد صحیح، مقادیر اعشاری نیز بپذیرد؛ برای مثال ۲۲۰، ۲۲۰٫۵، ۲۲۰٫۷۵ و به همین ترتیب. به همین دلیل میگوییم این متغیر، عددی و پیوسته است.
در مقابل، برخی متغیرها هرچند عددی هستند، اما پیوسته نیستند و تنها مقادیر مشخص و محدودی میگیرند. برای مثال، متغیر تعداد سیلندر خودرو را در نظر بگیرید. ما نمیتوانیم خودرویی با «چهار و نیم سیلندر» داشته باشیم؛ بنابراین این متغیر عددی است، اما گسسته (Discrete) محسوب میشود.
نکتهی مهم این است که برای متغیرهای مستقل چنین محدودیتی وجود ندارد. متغیرهای مستقل میتوانند:
- عددی باشند،
- دستهای یا طبقهای باشند،
- یا حتی عددی ولی غیرپیوسته باشند؛ مانند تعداد سیلندر خودرو.
معرفی رگرسیون
رابطه یا مدلی که ارتباط بین متغیر پاسخ و متغیرهای توضیحی یا مستقل را توصیف میکند، مدل رگرسیون یا Regression Model نام دارد. این مدلها به ما کمک میکنند تا تأثیر متغیرهای مختلف را بر متغیر هدف تحلیل کرده و در بسیاری از موارد، مقدار آن را تخمین بزنیم. مدلهای رگرسیون زمانی کاربرد دارند که متغیر پاسخ (یا متغیر وابسته) دارای مقدار عددی پیوسته باشد. به همین دلیل، رگرسیون معمولاً برای پیشبینی یا تحلیل متغیرهایی استفاده میشود که میتوانند روی یک بازهی عددی تغییر کنند.
وقتی میگوییم یک متغیر مقدار عددی دارد، منظور این است که مقادیر آن بهصورت عدد بیان میشوند. برای مثال، در دیتاستی که بررسی کردیم، متغیر میزان انتشار CO₂ دارای مقادیر عددی مشخصی مانند ۱۹۶، ۲۲۱ و مقادیر مشابه است. این اعداد نشاندهندهی مقدار واقعی یک کمیت قابل اندازهگیری هستند.
شرط استفاده از رگرسیون
آنچه در رگرسیون اهمیت دارد این است که متغیر پاسخ یا Response Variable ما، عددی و پیوسته باشد. به همین دلیل، از رگرسیون زمانی استفاده میکنیم که هدف ما پیشبینی یا تحلیل یک مقدار عددی پیوسته باشد. البته در ادامهی آموزش، با نوعی از رگرسیون آشنا خواهیم شد که این شرط در آن بهصورت کلاسیک برقرار نیست.
انواع رگرسیون
در همین جلسه، بهصورت کامل به این موضوع میپردازیم. اکنون به سراغ انواع رگرسیون میرویم. بهطور کلی، رگرسیون به دو دستهی اصلی تقسیم میشود:
- رگرسیون خطی (Linear Regression)
- رگرسیون غیرخطی (Nonlinear Regression)
هر یک از این دو دسته، خود میتوانند به دو حالت مختلف مورد استفاده قرار گیرند:
- رگرسیون ساده (Simple)
- رگرسیون چندمتغیره (Multiple)
در ادامه توضیح میدهیم که منظور از این دستهبندیها چیست.
رگرسیون خطی
سؤال اصلی این است که چه زمانی میگوییم یک رگرسیون خطی است؟
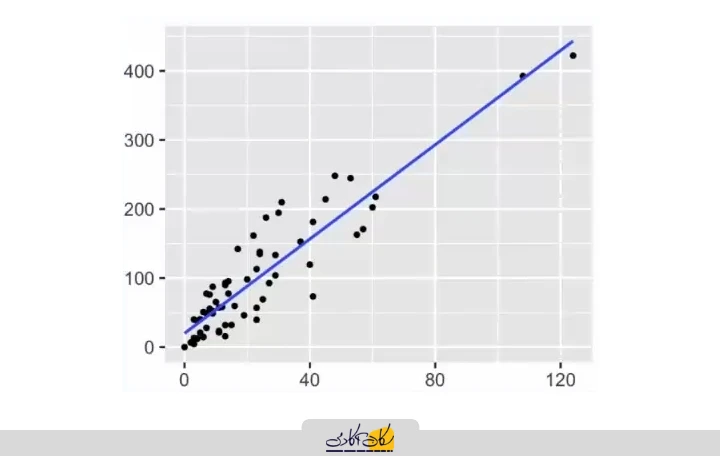
برای پاسخ به این سؤال، کافی است به مفاهیم پایهی ریاضی رجوع کنیم. اگر رابطهی بین متغیر مستقل و متغیر وابسته را بتوان با یک خط مستقیم نمایش داد، آنگاه با یک رگرسیون خطی سروکار داریم؛ مشابه نموداری که در اینجا مشاهده میکنید.
فرم ریاضی رگرسیون خطی
در رگرسیون خطی، رابطهی بین متغیرها بهصورت یک معادلهی خطی بیان میشود. در این رابطه:
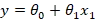
- متغیر yهمان متغیر پاسخ یا متغیر وابسته است.
- متغیر x_1متغیر مستقل بوده و روی محور افقی قرار دارد.
- یک مقدار ثابت عددی وجود دارد که به آن عرض از مبدأ یا Intercept گفته میشود و با نماد
θ_0نمایش داده میشود. - ضریب مربوط به متغیر مستقل، که نشاندهندهی شیب خط (Slope) است، با
θ_1نمایش داده میشود.
مفهوم شیب خط (Slope)
شیب خط بیانگر میزان تغییرات متغیر وابسته نسبت به تغییرات متغیر مستقل است. به بیان سادهتر، شیب نشان میدهد که با افزایش یک واحدی متغیر x، مقدار متغیر y به چه میزان تغییر میکند. این مقدار در یک خط مستقیم، ثابت است و به همین دلیل رابطهی بین متغیرها خطی در نظر گرفته میشود.
عرض از مبدأ (Intercept)
عرض از مبدأ یا Intercept نقطهای است که خط رگرسیون، محور عمودی یا همان محور y را قطع میکند.
برای مثال، در نمودار نمایش دادهشده، خط آبی محور y را در نقطهای با مقدار ۲۰ قطع کرده است. در این حالت، مقدار Intercept برابر با ۲۰ در نظر گرفته میشود. برای نمونه، اگر با افزایش مقدار x، مقدار yاز ۴۰ به ۱۲۰ افزایش پیدا کند، این تغییرات نشاندهندهی شیب خط است که با نماد θ_1 نمایش داده میشود. در این شرایط، میتوان رابطهی خط را بهصورت زیر نوشت:
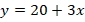
این معادله یک نمونه از یک رابطهی خطی بین متغیر مستقل و متغیر وابسته است. حال این سؤال مطرح میشود که رگرسیون خطی دقیقاً به چه معناست؟
فرض کنید یک مجموعهداده در اختیار داریم، مشابه نمودار پراکندگی (Scatter Plot) که در اینجا مشاهده میکنید. این دادهها شامل تعدادی جفت مقدار (x,y)هستند که از دنیای واقعی جمعآوری شدهاند. هدف ما این است که بهترین خط ممکن را پیدا کنیم که بتواند این دادهها را بهخوبی نمایش دهد، و این خط را به دادهها برازش (Fit) دهیم. و وقتی فرمول خط را به دست بیاورم که میشود
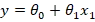
به عملیات به دست اوردن θ و ساختن این مدل ریاضی میگوییم رگرسون خطی اگر مدل تنها شامل یک متغیر مستقل باشد (مانند x_1)، به آن رگرسیون خطی ساده (Simple Linear Regression) گفته میشود.
اما اگر بهجای یک متغیر مستقل، چندین متغیر مستقل در مدل وجود داشته باشد و رابطه از حالت دو جملهای خارج شود، با رگرسیون خطی چندگانه (Multiple Linear Regression) یا Multiple Linear Regression سروکار داریم.
رگرسیون خطی چندگانه (Multiple Linear Regression)
در حالتی که بیش از یک متغیر مستقل داشته باشیم، رابطهی رگرسیون بهصورت زیر نوشته میشود:
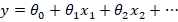
در این رابطه:
- yمتغیر پاسخ یا متغیر وابسته است،
- x_1 "،" x_2و سایر متغیرها، متغیرهای مستقل هستند،
- و ضرایب θمیزان تأثیر هر متغیر مستقل را مشخص میکنند.
زمانی که دادههای واقعی را رسم میکنیم، معمولاً با یک نمودار پراکندگی (Scatter Plot) از نقاط روبهرو هستیم. برای مثال، اگر میزان انتشار CO₂ را برحسب مصرف سوخت رسم کنیم، مجموعهای از نقاط بهدست میآید.
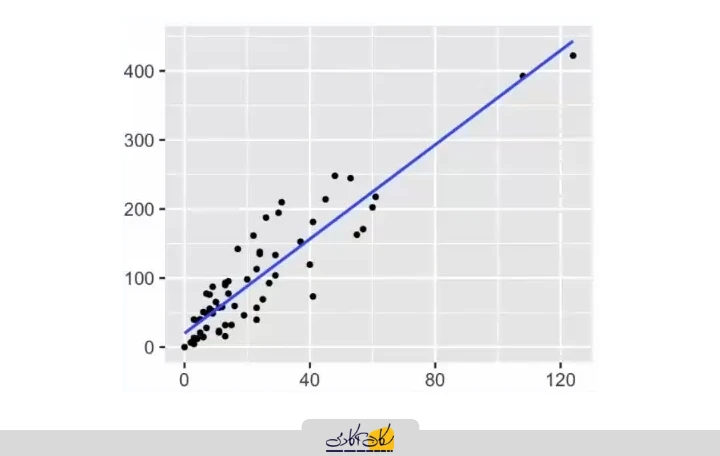
اگر این نقاط بهگونهای باشند که بهترین مدل قابل برازش به آنها یک خط مستقیم باشد، در این حالت میگوییم رابطهی بین متغیر مستقل و متغیر پاسخ خطی است و میتوان از رگرسیون خطی استفاده کرد.
رگرسیون غیرخطی (Nonlinear Regression)
اما اگر چیدمان نقاط بهگونهای باشد که بهترین مدل قابل برازش یک خط مستقیم نباشد، و شکل مناسبی مانند یک منحنی یا تابع درجهدو (سهمی) داشته باشد، در این صورت، رابطهی بین متغیرهای مستقل و متغیر پاسخ، غیرخطی در نظر گرفته میشود و از رگرسیون غیرخطی استفاده میکنیم.
در رگرسیون غیرخطی نیز اگر تنها یک متغیر مستقل وجود داشته باشد، با یک مدل ساده سروکار داریم، و اگر چندین متغیر مستقل در مدل حضور داشته باشند، مدل بهصورت چندگانه خواهد بود. برای نمونه، در رابطهای که در اینجا مشاهده میکنید:
- یک مقدار ثابت عددی
θ_0وجود دارد، - یک ضریب
θ_1داریم، - اما متغیر مستقل در مخرج کسر قرار گرفته است.
این ساختار باعث میشود که رابطهی yدیگر خطی نباشد و شکل مدل از حالت خط مستقیم خارج شود. در چنین شرایطی، برای تطبیق بهتر با الگوی دادهها، ناچار به استفاده از یک مدل غیرخطی هستیم.
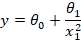
رگرسیون لاجستیک (Logistic Regression)
علاوه بر رگرسیون خطی و غیرخطی، نوع دیگری از رگرسیون نیز وجود دارد که به آن رگرسیون لاجستیک گفته میشود. نکتهی مهم دربارهی رگرسیون لاجستیک این است که معمولاً در دورههای یادگیری ماشین، بهعنوان یکی از روشهای دستهبندی (Classification) معرفی میشود، نه رگرسیون به معنای کلاسیک.
این تفاوت به نوع خروجی مدل بازمیگردد که در ادامهی آموزش بهصورت دقیق به آن خواهیم پرداخت. در رگرسیون، شما تعدادی متغیر مستقل یا ویژگی (Feature) به مدل میدهید و در خروجی، یک عدد بهعنوان تخمین دریافت میکنید. برای مثال:
- اندازه موتور،
- تعداد سیلندر،
- و میزان مصرف سوخت
را به مدل میدهید و مدل، مقدار انتشار CO₂ را بهصورت یک عدد پیشبینی میکند. در این حالت، خروجی مدل یک مقدار عددی است. در مقابل، در کلاسیفیکیشن خروجی مدل عدد پیوسته نیست، بلکه یک برچسب یا دسته است. برای نمونه، فرض کنید مجموعهای از اطلاعات افراد را در اختیار داریم، مانند:
- جنسیت
- رنگ پوست
- وزن
- قد
مدل با استفاده از این ویژگیها، هر فرد را در یکی از چند دستهی مشخص قرار میدهد. برای مثال، اگر چهار دسته (Category) داشته باشیم، مدل مشخص میکند که هر فرد به کدام یک از این دستهها تعلق دارد. حال اگر متغیر پاسخ ما دوحالته باشد، مانند:
بله / خیر
صفر / یک
درست / نادرست
در این حالت با رگرسیون لاجستیک سروکار داریم.
هرچند رگرسیون لاجستیک از نظر خروجی، یک مدل دستهبندی محسوب میشود، اما به دلیل ساختار ریاضی آن، واژهی «رگرسیون» در نام آن باقی مانده است. به همین دلیل، در بسیاری از دورههای یادگیری ماشین، رگرسیون لاجستیک در دستهی مدلهای Classification قرار میگیرد.
مشابه رگرسیون خطی و غیرخطی، رگرسیون لاجستیک نیز میتواند ساده (Simple) باشد و تنها یک متغیر مستقل داشته باشد، یا چندگانه (Multiple) باشد و از چندین متغیر مستقل استفاده کند.
در رگرسیون کلاسیک تأکید کردیم که متغیر پاسخ باید عددی و پیوسته باشد. اما در رگرسیون لاجستیک متغیر پاسخ لاجیکال است، و تنها دو مقدار صفر یا یک میگیرد.
برای درک بهتر این موضوع، فرض کنید مجموعهای از دادههای نقطهای در اختیار داریم. با استفاده از ویژگیها (چه یک ویژگی در حالت ساده و چه چند ویژگی در حالت چندگانه)، یک خط به این دادهها برازش میکنیم. این خط بهعنوان یک مرز تصمیم (Decision Boundary) عمل میکند:
- نقاطی که در یک سمت خط قرار میگیرند، در یک دسته (مثلاً صفر) قرار داده میشوند،
- و نقاط سمت دیگر خط، در دستهی مقابل (مثلاً یک).
در واقع، ما با برازش یک مدل خطی، عملیات دستهبندی را انجام میدهیم. به دلیل استفاده از مفهوم برازش و مدلسازی ریاضی، واژهی «رگرسیون» در نام این روش حفظ شده است؛ اما از آنجا که خروجی آن صفر و یک است، این روش در عمل یک مدل کلاسیفیکیشن محسوب میشود.
سرفصلهای دوره رگرسیون
از آنجا که این دوره یک دورهی مقدماتی و آشنایی با مفاهیم رگرسیون است:
- در سه فصل ابتدایی، تمرکز ما بر رگرسیون خطی ساده (Simple Linear Regression) خواهد بود.
- در فصل پایانی، به رگرسیون لاجستیک ساده (Simple Logistic Regression) میپردازیم.
ممکن است این سؤال مطرح شود که با وجود مدلهای آماری و یادگیری ماشین متعدد، چرا رگرسیون را بهعنوان نقطهی شروع انتخاب کردهایم؟
پاسخ این است که رگرسیون، دروازهی ورود به دنیای مدلسازی آماری محسوب میشود و یکی از سادهترین و قابلفهمترین روشها برای شروع است.
اولین پرسشی که در بسیاری از مسائل دادهمحور با آن روبهرو میشویم این است که:
- رابطهی بین دو متغیر چیست؟
- تغییر یک متغیر چه تأثیری بر متغیر دیگر دارد؟
- و چگونه میتوان بر اساس این رابطه، پیشبینی انجام داد؟
در همین نقطه است که رگرسیون بهعنوان یک ابزار ساده، شفاف و قابل تفسیر اهمیت پیدا میکند.
اهمیت رگرسیون خطی ساده
رگرسیون خطی ساده پایهی اصلی بسیاری از مدلهای پیشرفتهتر است:
- پایهای برای رگرسیون خطی چندگانه،
- و حتی نقطهی شروعی برای درک رگرسیونهای غیرخطی.
اگر در این دوره بتوانید مفهوم Simple Linear Regression را بهصورت عمیق و درست یاد بگیرید، مسیر یادگیری سایر مدلهای آماری و یادگیری ماشین برای شما بسیار هموارتر خواهد شد. نکتهی مهم دیگر این است که در عمل، بسیاری از تحلیلگران و مدلسازان تلاش میکنند دادهها را بهگونهای تبدیل یا پیشپردازش کنند که:
- یا با رگرسیون خطی ساده سازگار شوند،
- یا حداقل به یک مدل خطی نزدیک شوند.
دلیل این موضوع، سادگی، قابلیت تفسیر بالا و پایداری مدلهای خطی است.
جمعبندی
استفاده از رگرسیون خطی دارای چند مزیت مهم است:
- تفسیر آسان: روابط بین متغیرها ساده و قابل فهم است.
- هزینه محاسباتی پایین: اجرای مدل سریع و سبک است.
- سرعت مدلسازی بالا: ایجاد و برازش مدل در زمان کوتاه انجام میشود.
- قابلیت مصورسازی (Visualization) ساده: میتوان دادهها و نتایج را بهراحتی نمودارسازی کرد.
به همین دلایل، حتی اگر دادههای ما شکل خطی نداشته باشند، میتوانیم با اعمال تبدیلات مناسب، رابطه را به خط نزدیک کرده و از رگرسیون خطی بهره ببریم. این موضوع در فصل دوم، نیمهی دوم دوره، بهصورت عملی بررسی خواهد شد. برای درک بهتر Linear Regression و تقویت دامنهی دانشی خود، چند لینک آموزشی مفید در اختیار شما قرار گرفته است.
بهویژه لینک اول، توضیحات بسیار کامل و مفیدی ارائه میدهد. استفاده از این منابع مکمل، شما را در یادگیری عمیقتر و کاربردیتر Linear Regression توانمند میسازد. با یادگیری این مفاهیم، شما سنگ بنای محکمی برای ادامه مسیر حرفهای خود در زمینه مدلسازی آماری و حتی یادگیری ماشین ایجاد خواهید کرد.