

در چهارمین فصل از دوره آموزشی «آشنایی با رگرسیون با statsmodels در پایتون» با مدل رگرسیون Logistic ساده آشنا میشوید و میآموزید چطور به کمک آن پیشبینی انجام دهید. به این منظور ابتدا با ذکر مثال، محل کاربرد مدل رگرسیون Logistic توضیح داده و در ادامه مبانی ریاضی این مدل و نحوه کار آن تشریح میشود. همچنین میآموزید چگونه یک مدل رگرسیون Logistic ساده را ایجاد کرده و پارامترهای آن را بهدست آورید.
آشنایی با رگرسیون لجستیک ساده (Logistic Regression )
در این فصل قصد داریم به بررسی مدلسازی رگرسیون لجستیک ساده بپردازیم.
در این قسمت و درسنامهی مربوط به آن، تمرکز ما بر این است که ابتدا مشخص کنیم رگرسیون لجستیک دقیقاً چیست و در چه موقعیتهایی به آن نیاز داریم. به عبارت دیگر، تلاش میکنیم به این سؤال پاسخ دهیم که چرا و برای حل چه نوع مسائلی از Logistic Regression استفاده میکنیم.
برای درک بهتر مفاهیم، مباحث این جلسه را در قالب بررسی یک مسئلهی واقعی پیش میبریم. به همین منظور، یک مجموعهداده با نام churn.csv در اختیار شما قرار داده شده است که در طول این فصل، تحلیلها و مدلسازیهای خود را بر اساس آن انجام خواهیم داد.
معرفی کتابخانهها و نمایش دادهها
در این بخش، ابتدا کتابخانههای مورد نیاز را ایمپورت میکنیم و سپس مجموعهداده را بررسی میکنیم تا با مقادیر آن آشنا شویم. از آنجا که حجم محتوای این جلسه نسبتاً زیاد است، کدها را از قبل نوشتهام و تنها آنها را اجرا میکنم و توضیح میدهم تا زمان زیادی صرف نشود.
لطفاً به کدهایی که ارائه شده توجه کنید و سپس نوتبوک خود را باز کرده و آنها را بررسی کنید. اگر در هر بخش سوالی داشتید، میتوانید یا در کامنتها بپرسید یا مستقیماً در گوگل جستجو کنید، زیرا اغلب مواردی که مطرح میشود، پیشتر توضیح داده شده است. بررسی ساختار مجموعهدادهی ما شامل سه ستون است:
- Hac_churned
- Time_since_first_purchase
- Time_since_last_purchase
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.formula.api as smf
churn = pd.read_csv('churn.csv')
print(churn.head(5), end="\n")
print("'has_churned' column values: ", churn["has_churned"].unique()) has_churned time_since_first_purchase time_since_last_purchase
0 0 -1.089221 -0.721322
1 0 1.182983 3.634435
2 0 -0.846156 -0.427582
3 0 0.086942 -0.535672
4 0 -1.166642 -0.672640
'has_churned' column values: [0 1]این سه ستون مربوط به یک مجموعه خدماتدهی هستند؛ بهعنوان مثال، فرض کنید شرکتی وجود دارد که سرویس ماهانه اینترنت ارائه میدهد. هر رکورد در این مجموعهداده، نماینده یک کاربر یا مشتری شرکت است.ستون اول که برای ما اهمیت ویژهای دارد، شامل مقادیر صفر و یک است و نشاندهندهی وضعیت خاصی برای هر کاربر میباشد. این ستون در تحلیل رگرسیون لجستیک بهعنوان متغیر هدف (Target Variable) مورد استفاده قرار میگیرد.
در این قسمت، ستونهای مجموعهداده را دقیقتر بررسی میکنیم:
- ستون (Hac_churned)
مقدار صفر نشاندهندهی این است که کاربر همچنان از خدمات شرکت استفاده میکند و ارتباطش با شرکت فعال است.
مقدار یک نشان میدهد که کاربر دیگر از خدمات شرکت استفاده نمیکند؛ بهعنوان مثال، خط اینترنت خود را جمعآوری کرده است یا سرویسش را لغو کرده است. - ستون زمان از اولین خرید (Time_since_first_purchase)
این ستون نشان میدهد که از اولین خرید کاربر چقدر زمان گذشته است.
به عبارتی، بیانگر مدت زمان رابطه کاربر با شرکت است.
مقادیر کمتر نشان میدهد که کاربر هنوز اخیراً از خدمات استفاده کرده است. - ستون زمان از آخرین خرید (Time_since_last_purchase)
این ستون مقدار زمان سپریشده از آخرین خرید یا تمدید سرویس کاربر را نشان میدهد.
هرچه این عدد بیشتر باشد، نشاندهندهی این است که کاربر مدتی طولانی است که با شرکت ارتباط نداشته است.
هدف ما بررسی این است که ارتباط بین ستونهای مستقل و وابسته چگونه است:
- ستونهای زمانی بهعنوان متغیر مستقل
- ستون هدف بهعنوان متغیر وابسته (کاربر فعال یا ریزش کرده)
به عبارت دیگر، میخواهیم ببینیم اگر کاربری ریزش میکند و ارتباط خود را قطع میکند، این موضوع چگونه با زمان سپریشده از آخرین خرید مرتبط است. در ادامه، نسبت و ارتباط این دو ستون با یکدیگر را بررسی خواهیم کرد تا بتوانیم الگوها و روندهای موجود در دادهها را تحلیل کنیم.
نکته: بعضی از مقادیر منفی در این ستونها به دلیل استانداردسازی دادهها ظاهر شدهاند، اما نسبتها و روند کلی دادهها همچنان معتبر هستند و میتوان از آنها در تحلیل استفاده کرد.
بررسی دادهها با نمودار پراکندگی
برای تحلیل اولیه، نمودارهای پراکندگی (Scatter Plot) مورد استفاده قرار میگیرند تا ارتباط بین ستونهای مجموعهداده را بهتر درک کنیم. در این جلسه، اولین نموداری که رسم میکنیم، نمودار پراکندگی ستون Has_churned بر حسب ستون Time_since_last_purchase است
- برای این نمودار، از 30 نمونه داده استفاده شده و اسکترپلات (scatter plot) روی دادههای مجموعهداده رسم شده است.
- مقدار alpha = 0.5 تعیین شده تا چگالی نقاط روی نمودار بهتر قابل مشاهده باشد.
sns.scatterplot(data=churn, x="time_since_last_purchase", y="has_churned", alpha=0.5)
plt.show()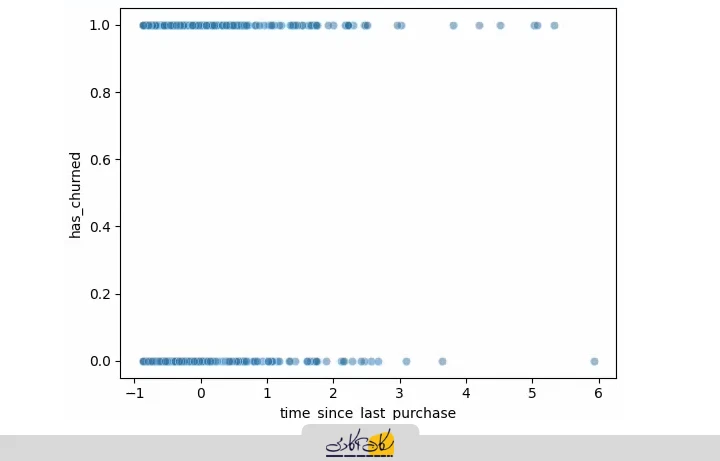
محور Y (ستون هدف) تنها شامل دو مقدار صفر و یک است:
- صفر برای کاربرانی که هنوز از خدمات شرکت استفاده میکنند.
- یک برای کاربرانی که دیگر خدمات را دریافت نمیکنند.
در بازه زمانی نمودار، هیچ مقدار دیگری بین صفر و یک وجود ندارد. به همین دلیل، در این نمودار، ارتباط واضح یا الگوی مشخصی بین ستون X (زمان از آخرین خرید) و ستون Y (وضعیت کاربر) قابل مشاهده نیست. به عبارت دیگر، با استفاده از نمودار پراکندگی، نمیتوان نتیجهگیری خاصی دربارهی رابطه مستقیم بین این دو ستون داشت.
بررسی دادهها با نمودار KDE
پس از بررسی اولیه با نمودار پراکندگی، به سراغ نمودارهای توزیع دادهها میرویم تا الگوهای موجود در ستون زمان از آخرین خرید را بهتر درک کنیم.
به جای رسم مستقیم هیستوگرام، ابتدا از نمودار KDE (Kernel Density Estimate) استفاده میکنیم. با استفاده از کتابخانه Seaborn، دو نمودار KDE برای ستون هدف رسم میکنیم:
- مقدار صفر (کاربرانی که هنوز از خدمات شرکت استفاده میکنند)
- مقدار یک (کاربرانی که ریزش کرده و دیگر از خدمات استفاده نمیکنند)
در این رسم، برای هر حالت از یک حلقه استفاده شده و تعداد 40 bin تعیین شده است تا منحنیها دقیقتر دیده شوند.
for x in [0, 1]:
values = churn.time_since_last_purchase[churn['has_churned'] == x]
sns.kdeplot(values, label=f"has_churned = {x}")
plt.legend()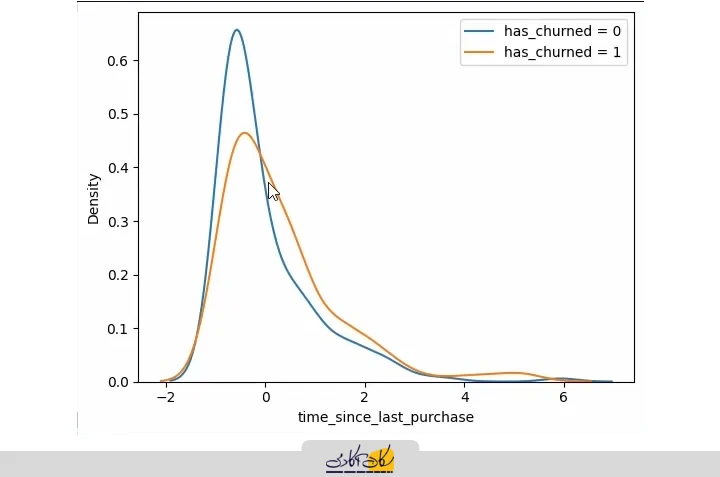
منحنی آبی رنگ مربوط به کاربران فعال (صفر) است و منحنی نارنجی رنگ مربوط به کاربران غیرفعال یا ریزش کرده (یک). از نمودار مشاهده میکنیم:
- کاربران فعال، زمان سپریشده از آخرین خرید آنها کمتر است و منحنی آنها به سمت چپ متمایل است.
- کاربران غیرفعال، زمان بیشتری از آخرین خرید آنها گذشته و منحنی آنها به سمت راست متمایل است.
این روند منطقی است کاربرانی که مدت زیادی خرید نکردهاند، احتمال ریزش بیشتری دارند.
رسم هیستوگرام مقایسهای
برای مقایسه دقیقتر، یک هیستوگرام کنار هم (side-by-side histogram) نیز رسم میکنیم. از قابلیت FacetGrid در Seaborn استفاده شده تا دو هیستوگرام کنار هم نمایش داده شوند. همچنین، گزینه kde=True در هیستوگرام فعال شده تا خط KDE روی هیستوگرام نیز نمایش داده شود و روند دادهها بهتر دیده شود.
g = sns.FacetGrid(churn, col='has_churned', hue='has_churned')
p1 = g.map(sns.histplot, 'time_since_last_purchase', kde=True).add_legend()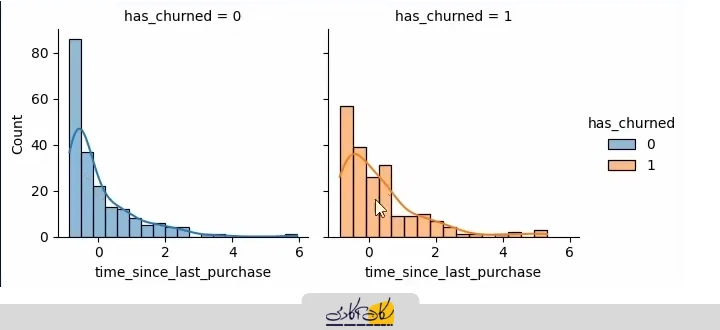
با این نمودارها میتوانیم دید بهتری نسبت به توزیع کاربران فعال و غیرفعال بر اساس زمان از آخرین خرید پیدا کنیم و روند ریزش را تحلیل کنیم. با استفاده از FacetGrid در کتابخانه Seaborn میتوانیم نمودارها را به تفکیک مقدار ستون هدف (صفر و یک) رسم کنیم و کنار هم نمایش دهیم:
- منحنی آبی رنگ مربوط به کاربران فعال (صفر) است که هنوز ریزش نکردهاند.
- منحنی نارنجی رنگ مربوط به کاربران ریزشی (یک) است.
- کاربران فعال در بازههای زمانی کمتر چگالی و جمعیت بیشتری دارند.
- کاربران ریزشی در بازههای زمانی بیشتر تعداد بیشتری دارند.
بنابراین، بین متغیر وابسته و متغیر مستقل (زمان از آخرین خرید) یک ارتباط قابل مشاهده است. این ارتباط در نمودار پراکندگی بهخوبی نمایان نمیشود، اما در نمودارهای توزیع به وضوح دیده میشود.
تا کنون، مسائل رگرسیون که حل کردهایم، متغیر وابسته عددی پیوسته داشتهاند و مدل میتوانست هر مقداری در یک بازه را پیشبینی کند. اما در مسائل فعلی و مشابه آن متغیر وابسته فقط دو مقدار دارد (صفر و یک). این متغیر میتواند غیر عددی نیز باشد، مانند:
- رنگها (آبی و قرمز)
- وضعیتها (پیروز/بازنده، بیمار/سالم، مردود/قبول)
در صورت غیر عددی بودن متغیر وابسته، باید آنها را Encode کنیم تا صفر و یک شوند. وقتی متغیر وابسته دو دسته دارد و متغیر مستقل عدد پیوسته است، میتوانیم از رگرسیون لجستیک (Logistic Regression) برای مدلسازی استفاده کنیم.
با استفاده از این روش، میتوانیم بر اساس مقدار متغیر مستقل پیشبینی کنیم که کاربر به کدام دسته (صفر یا یک) تعلق دارد. در ادامه، با مثالهای عملی بیشتر با این روش و عملکرد آن آشنا خواهیم شد و تحلیلها را کاملتر میکنیم.
استفاده از رگرسیون خطی
اگر بر اساس OLS (Ordinary Least Squares) یک مدل خطی بسازیم و رگرسیون خطی بین متغیر مستقل و وابسته رسم کنیم، خط پیشبینی ما همچنان مقادیر بین صفر و یک را پوشش میدهد. در این حالت، وقتی مدل پیشبینی (predict) میکند، نقاط روی این خط قرار میگیرند. مشکل اصلی ما هیچ ایدهای نداریم که هر نقطه به کدام دسته تعلق دارد؛ یعنی نمیتوانیم تشخیص دهیم که کدام نقطه مربوط به کلاس صفر و کدام مربوط به کلاس یک است.
sns.regplot(data=churn, x="time_since_last_purchase", y="has_churned", ci=None)
plt.show()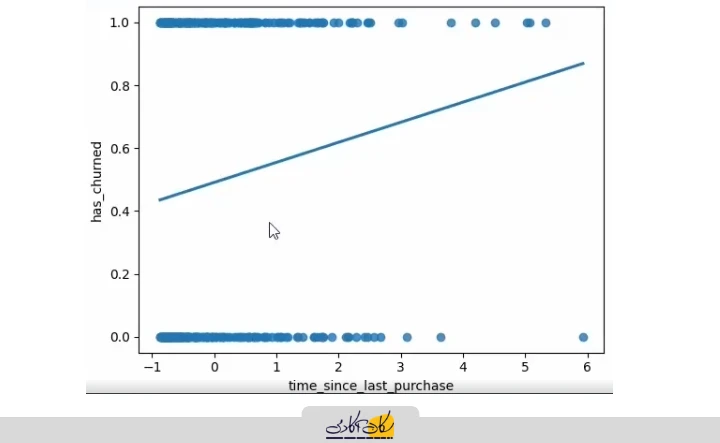
اگر مقادیر متغیر مستقل خارج از بازه دادههای موجود (Extrapolation) قرار بگیرند، رگرسیون خطی همچنان مقادیری خارج از صفر و یک تولید میکند. برای مثال، اگر متغیر مستقل مقداری خارج از محدوده مشاهده شده داشته باشد، پیشبینی مدل هم میتواند منفی یا بزرگتر از یک شود که معنایی برای دستهبندی ندارد.
مرور روش رگرسیون خطی
فرض کنید مانند قبل، از Linear Regression استفاده میکنیم:
- مدل را فیت میکنیم و پارامترها (Intercept و Slope) را به دست میآوریم.
- سپس با استفاده از این پارامترها و ابزارهایی مانند Matplotlib، یک خط رسم میکنیم.
- شیب خط همان Slope مدل است و نقطه برخورد خط با محور Y همان Intercept است.
تا این مرحله، همه چیز مشابه تحلیلهای رگرسیون خطی گذشته است، اما مشکل اصلی این است که متغیر وابسته باینری است و مقادیر واقعی میتوانند تنها صفر یا یک باشند، نه هر عددی روی خط. به همین دلیل، رگرسیون خطی برای مسائل باینری مناسب نیست و ما نیاز به روش جایگزین داریم که بتواند احتمال تعلق به هر کلاس را پیشبینی کند و مقادیر پیشبینیشده را بین صفر و یک محدود نگه دارد.
رسم خط مدل و محدودیتهای رگرسیون خطی
برای بررسی عملی محدودیتهای رگرسیون خطی، ابتدا خط مدل را روی دادههای پراکندگی (Scatter Plot) رسم میکنیم. رنگ خط را مشکی انتخاب میکنیم تا از دادهها متمایز باشد. دادههای پراکندگی اولیه نیز روی نمودار قرار داده میشوند تا بتوانیم تغییرات را مشاهده کنیم.
# plot regplot
log_model = smf.ols("has_churned ~ time_since_last_purchase", data=churn).fit()
intercept, slope = log_model.params
plt.axline(xy1=(0, intercept), slope=slope, color="black")
# plot s_curve
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# x = np.linspace(-10, 10, 100)
# y = sigmoid(x)
# plt.plot(x, y, color="red")
sns.scatterplot(data=churn, x="time_since_last_purchase", y="has_churned", alpha=0.5)
plt.show()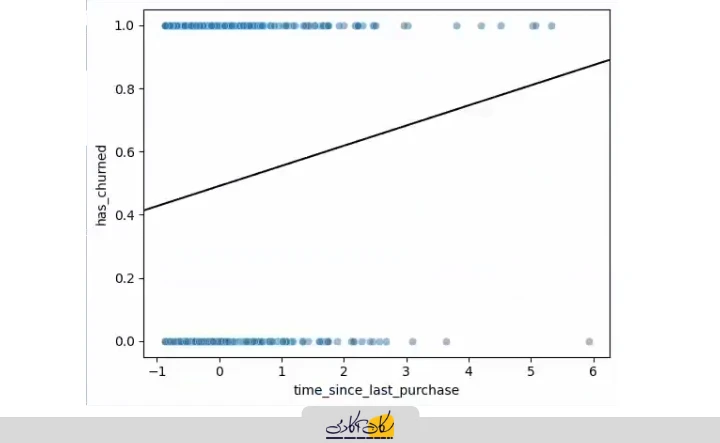
اگر محدوده محور X را از -10 تا +10 تنظیم کنیم و محور Y را از -0.5 تا 1.5 قرار دهیم، مشکل Extrapolation مشخص میشود.
# plot regplot
log_model = smf.ols("has_churned ~ time_since_last_purchase", data=churn).fit()
intercept, slope = log_model.params
plt.axline(xy1=(0, intercept), slope=slope, color="black")
# plot s_curve
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# x = np.linspace(-10, 10, 100)
# y = sigmoid(x)
# plt.plot(x, y, color="red")
sns.scatterplot(data=churn, x="time_since_last_purchase", y="has_churned", alpha=0.5)
plt.xlim(-10,10)
plt.ylim(-0.5,1.5)
plt.show()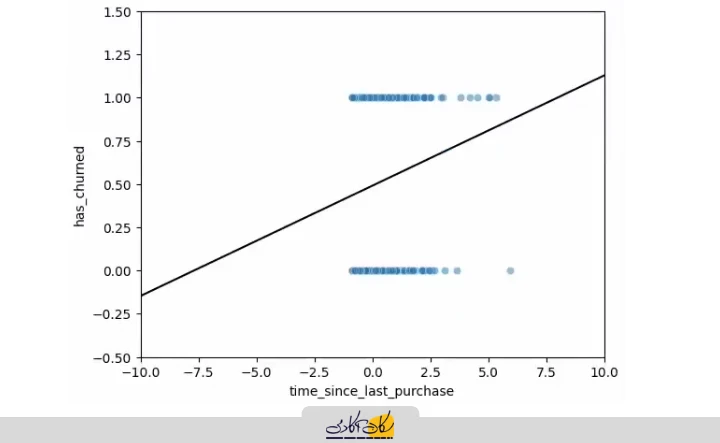
در این حالت، رگرسیون خطی برای مقادیر خارج از بازه دادههای مشاهده شده، مقادیری خارج از صفر و یک پیشبینی میکند:
- مثال: برای X = 10، مدل مقدار 1.25 پیشبینی میکند، در حالی که حداکثر مقدار کلاس 1 است.
- برای X = -10، مدل مقدار -0.1 پیشبینی میکند، در حالی که حداقل مقدار کلاس صفر است.
رگرسیون خطی نمیتواند مشخص کند هر نقطه به کدام کلاس تعلق دارد. مقادیر پیشبینی خارج از محدوده صفر و یک قابل استفاده نیستند.
رگرسیون لجستیک (Logistic Regression)
برای حل این مشکلات، از رگرسیون لجستیک (Logistic Regression) استفاده میکنیم. رگرسیون لجستیک مقادیر پیشبینی شده را بین 0 و 1 محدود میکند و میتواند احتمال تعلق هر نقطه به کلاس صفر یا یک را پیشبینی کند.
این کار با استفاده از تابع سیگموید (Sigmoid Function) انجام میشود. این تابع، که به آن منحنی سیگموید نیز گفته میشود، ورودیهای پیوسته را به خروجی بین 0 و 1 تبدیل میکند. منحنی سیگموید به ما اجازه میدهد که رابطه بین متغیر مستقل پیوسته و متغیر وابسته باینری را مدل کنیم و احتمال تعلق هر نمونه به هر کلاس را محاسبه کنیم.
در ادامه، این منحنی را روی دادهها رسم میکنیم و عملکرد رگرسیون لجستیک را با رگرسیون خطی مقایسه میکنیم. برای بررسی عملکرد رگرسیون لجستیک، ابتدا یک بازه عددی از 10- تا 10 تعریف کردیم و 100 نقطه نمونه در آن ایجاد کردیم. سپس مقدار تابع سیگموید را برای این نقاط محاسبه و نمودار آن را رسم کردیم (خط قرمز).
# plot s_curve
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.linspace(-10, 10, 100)
y = sigmoid(x)
plt.plot(x, y, color="red")
sns.scatterplot(data=churn, x="time_since_last_purchase", y="has_churned", alpha=0.5)
# plt.xlim(-10,10)
# plt.ylim(-0.5,1.5)
plt.show()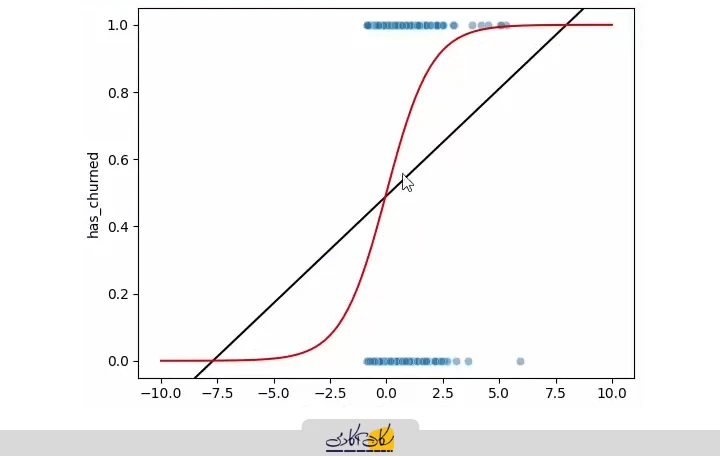
محدود شدن مقادیر بین صفر و یک:
- برخلاف رگرسیون خطی، تابع سیگموید هیچگاه از صفر پایینتر یا از یک بالاتر نمیرود.
- به عبارت دیگر، منحنی در بالا به مجاورت Y = 1 و در پایین به مجاورت Y = 0 و به بینهایت امتداد مییابد.
- این ویژگی باعث میشود که مشکل Extrapolation در رگرسیون خطی حل شود.
تشخیص خودکار کلاسها در بازههای دور از دادهها:
- اگر زمان آخرین خرید بسیار طولانی باشد (مثلاً یک سال)، رگرسیون لجستیک به صورت خودکار کاربر را جزو ریزشیها (کلاس 1) قرار میدهد.
- اگر زمان آخرین خرید بسیار کوتاه باشد، کاربر به صورت خودکار در کلاس فعال (کلاس 0) قرار میگیرد.
- به این ترتیب، در بازههای دور از دادهها، تصمیمگیری کاملاً مشخص و بدون خطا انجام میشود.
محدوده تصمیمگیری در وسط نمودار:
- تنها در بازهای میانی، که مقدار تابع سیگموید بین صفر و یک است، نیاز به تصمیمگیری داریم.
- اگر نقطهای در این بازه میانی قرار گیرد، باید مشخص کنیم که این نمونه جزو کلاس پایین (0) یا کلاس بالا (1) باشد.
- این تصمیم بر اساس احتمال خروجی تابع سیگموید و مرز تصمیم (Decision Boundary) گرفته میشود.
رگرسیون لجستیک سعی میکند رابطه بین متغیر مستقل (X) و متغیر وابسته باینری (Y) را با استفاده از تابع سیگموید مدل کند.
تعریف تابع سیگموید با ضرایب
ابتدا فرض میکنیم مدل خطی زیر داریم:
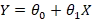
در رگرسیون لجستیک، به جای Y مستقیم، این مقدار را وارد تابع سیگموید میکنیم:
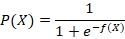
مدل به دنبال یافتن ضرایب θ0 و θ1 است به گونهای که نقاط دادههای مشاهدهشده بیشترین انطباق را با تابع سیگموید داشته باشند. این فرآیند باعث میشود که منحنی سیگموید به شکل S یا اسکرو (S-curve) در بیاید و بهترین جداسازی بین کلاسها را ایجاد کند.
تصمیمگیری نهایی بر اساس P(X)
پس از تعیین ضرایب، برای هر نمونه مقدار P(X) محاسبه میشود:
- اگر
P(X)≥0.5، نمونه به کلاس 1 (ریزش) تعلق دارد. - اگر
P(X)<0.5، نمونه به کلاس 0 (فعال) تعلق دارد.
به عبارت ساده، رگرسیون لجستیک ابتدا یک خط f(X) پیدا میکند، سپس با اعمال تابع سیگموید آن را به منحنی اسکرو (S-curve) تبدیل میکند، و در نهایت بر اساس مقدار پیشبینیشده تصمیم میگیرد هر نمونه به کدام کلاس تعلق دارد.
به عبارتی، مقدار P(X) نشاندهنده احتمال تعلق نمونه به کلاس 1 است. با استفاده از این شرط، مقادیر پیوسته تابع سیگموید به دستههای باینری (0 یا 1) تبدیل میشوند. گرد کردن احتمالات:
- مثال: اگر
P(X) = 0.6، پس از گرد کردن به کلاس 1 تبدیل میشود. - اگر
P(X) = 0.4، پس از گرد کردن به کلاس 0 تبدیل میشود.