
همانطور که همه ما میدونیم، Redis بدون شک یکی از محبوب ترین و پرکاربرد ترین برنامه ها در صنعت نرم افزار هست. اگر کمی با این ابزار کارکنید قطعا نسبت به اون علاقه مند میشد و برای پروژه هاتون از اون استفاده خواهید کرد . این اتفاق برای من هم افتاد و واقعا از کار کردن با ردیس لذت بردم واین فکر به ذهنم رسید: چرا در رابطه با دیتابیس های in-memory عمیق تر تحقیق نکنم تا به تمام توانایی هاشون پی ببرم؟ در این صورت میتونیم از این برنامه ها بیشترین استفاده رو بکنیم و ابزار مناسب تری رو برای پروژه هامون انتخاب کنیم.
در این مقاله شما را دعوت میکنم، تا من را در این سفر اکتشافی دیتابیس های in-memory همراهی کنید. آماده اید؟
بزن بریم!! 😉
دیتابیس های in-memory اخیرأ بخاطر دسترسی سریع به داده و پردازش سریع اطلاعات محبوبیت قابلی توجهی بدست آوردن. همچنین نقش بسیار مهمی در سیستم های اطلاعات جغرافیایی ( GIS )،پردازش بدوم درنگ جریان های داده ( streamها )، تحلیل داده، یادگیری ماشین و زمینه های مختلف دیگر ایفا میکنن.
چه زمانی از دیتابیس های in-memory استفاده کنیم :
- کش کردن و برای پاسخ های سریع (بدون پردازش)
- مدیریت افزایش ترافیک
- انجام عملیات ها در سرعت بالا
- مدیریت سشن ها
- این لیست ادامه داره…
تعداد بسیار زیادی دیتابیس in-memory وجود داره، اما ما در این مقاله فقط چندتایی از آنها را بررسی میکنیم:
- Memcached
- Redis
- Hazelcast
- Memgraph
- Apache ignite
- نگاه کوتاهی به Couchbase و Aerospike
Memcached(ممکشد):
یک برنامه، ساده و با معماری توزیع یافته (distributed) به همراه ذخیره سازی به کمک key/value و با کارایی بسیار بالا برای کش کردن هست.

- مزایا:
1.ساده و سبک: این برنامه طراحی ساده ای دارد که باعث میشه استفاده از اون آسان باشه و یک راه حل سریع برای افزایش عملکرد برنامه به حساب میاد.
2.مقیاس پذیری: Memcached به صورت افقی مقیاس پذیر است، امکان افزایش node های بیشتری برای افزایش عملکرد و ذخیره سازی به ما میده.
3.معماری mulit-thread : برخلاف Redis،این برنامه معماری multi-thread رو در برمیگیره که منجر به عملکرد بهتر نسبت به ردیس به ویژه هنگام کار با داده های بزرگ میشه.
- معایب:
1.عدم پایداری(حافظه موقت): این برنامه گزینه های پایداری دیتا ارائه نمیده. اگه سرور دوباره راهاندازی بشه یا خاموش بشه، تمام داده های ذخیره شده در مموری حذف میشه و قابل دسترسی نیست. همچنين وقتی Memcached فضای ذخیرهش پر بشه، شروع به حذف کردن داده های قدیمی میکنه.
2.محدودیت ساختار داده ها : این برنامه فقط از key-value پشتیبانی میکنه و فاقد ساختارهای پیچیده تر و قابلیت کوئری پیچیده هستش.
Redis(ردیس):
ردیس رو که تقریبا هرکسی که تو حوزه نرم افزار کار میکنه باهاش اشنایی داره ؛که به عنوان یک دیتابیس key/value ساده شروع به کار کرد،اما به یک برنامه کاربردی قوی در سطح سازمانی تبدیل شده. Redis درحال حاظر طیف وسیعی از ویژگی های قدرتمند و پیشرفته ای مثل: پارتیشن بندی، پایداری داده روی دیسک، Messaging Broker، پردازش جریان های داده و غیره رو ارائه میده.

- مزایا:
1.عملکرد بالا: با داده هایی که بهطور کامل در مموری ذخیره میشن، Redis عملیات خواندن و نوشتن فوق العاده سریعی رو ارائه میده؛ که اون رو برای مواردی که نیاز به دسترسی با تأخیر کم داریم ، ایدهآل میکنه.
2. پشتیبانی از ساختار داده های پیچیده: Redis از ساختار داده های مختلف از جمله رشته ها، لیست ها، مجموعه ها،Hashes، JSON و موارد دیگه پشتیبانی میکنه و انعطافپذیری زیادی داره.
3.اکوسیستم غنی برای client
4.گزینه های پایداری:Redis این قابلیت رو داره تا داده ها رو روی دیسک حفظ کنه و در صورت خرابی سیستم یا ری استارت، ماندگاری داده را تضمین میکنه.
5.خوشهبندی (clustering) و مقیاس پذیری افقی
6.اوپن سورس و نگهداری عالی
- معایب:
1.فاقد قابلیت کوئری پیچیده: Redis فاقد قابلیت های جست و جوی پیشرفته هست، که معمولاً در اکثر دیتابیس های قدیمی پیدا میشه. با این حال، با استفاده از ماژول های ارائه شده توسط Redis Stack میتونیم قدرت کوئری بیشتری حین کار با ساختارداده های پیشرفته داشته باشیم.
Hazelcast:
یک برنامه اوپن سورس از نوع IMDG(in-memory data grid) هست که محاسبات درون حافظه مقایس پذیر را فراهم میکنه. محاسبات و ذخیره سازی توزیع شده که منجر به تاخیر بسیار کم برای انجام عملیات و دریافت داده میشه .

- مزایا:
1.ذخیرهسازی و پردازش توزیع یافته(distributed): برای دسترسی و مقایس پذیری بالا، شما باید داده های خود را در چندین node پخش کنید.
2.ساختار های پیچیده داده
3.پردازش جریان (stream):به ما این اجازه رو میده تا داده ها رو از جریان ها و منابع داده مانند Apache Kafka و Message-Broker ها را پردازش کنیم.
4.کوئری ساده: Hazelcast قابلیت های کوئری رو از طریق HQL (مشابه SQL) فراهم میکنه و به شما این امکان رو میده که به راحتی با دیتاتون کار کنید.
- معایب:
1.گزینه های محدود پایداری داده: Hazelcast در درجه اول بر روی ذخیره سازی داده های درون مموری تمرکز میکنه و درحالی که گزینه هایی برای پایداری دیتا بر روی دیسک ارائه میده؛ اما ممکن هست به اندازه دیتابیس های اختصاصی برای این کار قوی نباشه.
2.پیچیدگی: نیاز به معماری دقیق و در نظر گرفتن عواملی مانند پیکربندی cluster، پیکربندی network و پارتیشن بندی داده ها داره.
3.وابستگی به ماشین مجازی : Hazelcast در اصل در جاوا پیاده سازی شده و برای اجرا به ماشین مجازی جاوا (JVM) متکی هست. این موضوع میتونه به استفاده بیشتر از حافظه و زمان بیشتر راه اندازی منتهی بشه.
4.پشتیبانی محدود از client
Memgraph:
یک پایگاه داده Graph است که برای تجزیه و تحلیل گراف با سرعت بالا و پردازش و تراکنش ها طراحی شده . این برنامه یک دیتابیس گراف مدرن هست که از محاسبات درون مموری برای ارائه عملیات سریع و کارآمد گراف استفاده میکنه. دقیقا مانند Neo4j است اما به دلیل معماری درون مموری ، بسیار سریعتر عمل میکنه.

- مزایا:
1.تراکنش هایی با سرعت بالا:از تراکنش های مطابق با ACID پشتیبانی میکنه و همچنین از ثبات و قابلیت تضمین داده ها حتی در محیط هایی با همزمانی بالا رو فراهم میکنه.
2.معماری توزیع یافته (distributed): Memgraph را می توان به صورت توزیع شده در چندین node مستقر کرد که امکان مقایس پذیری افقی و تحمل خطا رو فراهم کنه.
3.زبان کوئری سایفر:Memgraph از زبان کوئری Cypher پشتیبانی میکنه که در Neo4j هم استفاده میشه.
4.پشتیبانی از درایور های Neo4j:به راحتی میشه اون رو به زبان های برنامه نویسی مختلف مانند جاوا، پایتون، جاوا اسکریپت، دات نت و ... متصل کرد.
- معایب:
1.اکوسیستم محدود
2.عدم ثبات و بلوغ
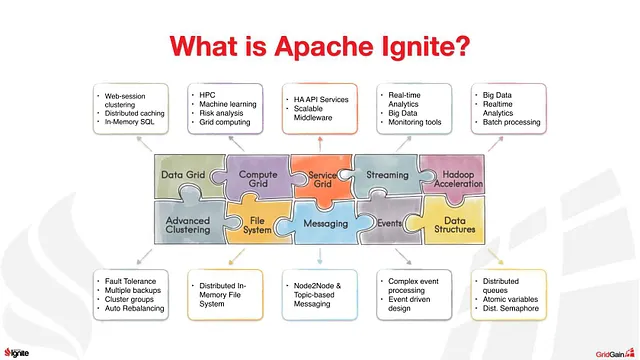
Apache Ignite:
یک پلتفرم محاسباتی اوپن سورس و توزیع شده در مموری هست که پردازش داده ها، کش کردن و قابلیت های کوئری پیشرفته را برای برنامه هایی که دسترسی سریع و مقیاس پذیر نیاز دارن، ارائه میده. به طور خلاصه Apache Ignite یه محصول غول پیکره که برای برنامه های سازمانی مناسبه.

- مزایا:
1.ذخیره سازی چندلایه: 3 رویکرد متفاوت از جمله 1- ذخیره سازی کاملا در مموری ، 2- in-memory + external DB و 3- حالت Multi-tier رو ارائه میده.
2.پشتیبانی از SQL:به ما این امکان را می ده که کوئری های SQL رو روی داده های ذخیره شده در IMDG اجرا کنیم.
3.معماری توزیع شده:این برنامه پارتیشن بندی دیتا ، همانندسازی (replication)، پردازش توزیع شده، دسترسی سریع به اطلاعات، تحمل خطا و موارد دیگه رو ارائه می ده.
4.پشتیبانی از یادگیری ماشین
5.رایگان و اوپن سورس
- معایب:
1.پیچیدگی:ویژگیهای قدرتمند Ignite با پیچیدگی بیشتری همراهش میکنه که نیاز به پیکربندی و مدیریت دقیق داره.
خب بیاید یک نگاه به دیتابیس هایی بکنیم که درواقع مموری محور نیستن اما ارزش ذکر کردن دارند .
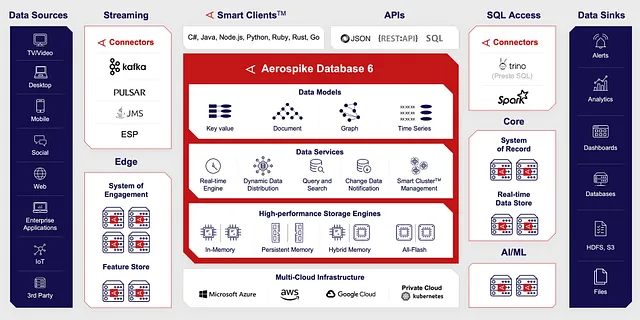
Aerospike DB :
یک پایگاه داده کاملا درون مموری نیست، با این حال گزینه ای برای انجام این کار داره. از طیف گسترده ای از معماری ها پشتیبانی میکنه مانند: in-memory ،Hybrid-Flash و All-Flash، یا معماری ذخیره سازی پایدار(NVMe, PCle, SSD ) را امکان پذیر میکنه. این برنامه یک محصول عظیم هست و بیشتر امکانات اون خارج از محدوده این وبلاگه.

ویژگی های این دیتابیس در یک نگاه:
Couchbase :
یک دیتابیس document (مثل MongoDB) هستش که از معماری memory first استفاده می کنه. Couchbase دارای یک لایه در حافظه است که به عنوان مکانیسم ذخیره سازی با سرعت بالا برای داده های با دسترسی مکرر عمل می کنه.

درحالی که این فهرست دیتابیس های in-memory به ظاهر بی پایان میرسه، این چند مثال باید برای یک وبلاگ کافی هستش. همچنین برنامه های فوق العاده دیگه ای مثل Apache Geode, Tarantool, Oracle Coherence وجود داره که می تونید در وبسایت هاشون دربارشون مطالعه کنید.
ممنونم بابت وقتی که گذاشتید 😉
معین معین نیا