
در این مقاله قصد داریم یاد بگیریم چگونه با استفاده از SLY (Sly Lex Yacc) و پایتون زبان برنامهنویسی خود را ایجاد کنیم. قبل از اینکه به طور عمیقتر به این موضوع بپردازیم، باید توجه داشته باشیم که این یک آموزش مبتدی نیست و شما باید اطلاعاتی از پیشنیازهای زیر را داشته باشید.
- مقدمهای درباره طراحی کامپایلر.
- درک اولیه از تجزیه و تحلیل لغوی (lexical analysis)، تجزیه و تحلیل نحوی (parsing) و سایر جنبههای طراحی کامپایلر.
- درکی از عبارات منظم (regular expressions).
- آشنایی با زبان برنامهنویسی پایتون.
(برای درک بهتر واژگان این مقاله به https://fa.wikipedia.org/wiki/%D8%AA%D8%AD%D9%84%DB%8C%D9%84_%D9%88%D8%A7%DA%98%DA%AF%D8%A7%D9%86%DB%8C مراجعه کنید)
شروع کردن
1. نصب SLY برای پایتون: SLY یک ابزار لکسینگ و پارسینگ است که فرایند را برای ما آسان میکند. برای نصب SLY، میتوانید از pip، نصبکنندهی بستهها برای پایتون استفاده کنید. ترمینال یا پنجرهی دستورات خود را باز کنید و دستور زیر را اجرا کنید:
pip install slyایجاد یک لکسر
فاز اول یک کامپایلر تبدیل تمام جریانهای کاراکتر (برنامهی سطح بالا که نوشته شده است) به جریانهای توکن است. این کار با استفاده از فرایندی به نام تجزیه و تحلیل لغوی (lexical analysis) انجام میشود. با این حال، با استفاده از SLY این فرآیند سادهتر میشود.
ابتدا بیایید همهٔ ماژولهای لازم را وارد کنیم.
from sly import Lexerحالا بیایید یک کلاس با نام BasicLexer بسازیم که از کلاس Lexer در SLY گسترش میدهد. بیایید یک کامپایلر بسازیم که عملیات حسابی ساده را انجام میدهد. بنابراین برخی از توکنهای اصلی مانند NAME، NUMBER، STRING نیاز داریم. در هر زبان برنامهنویسی، بین دو کاراکتر فاصله وجود دارد. بنابراین یک ignore literal ایجاد میکنیم. سپس literalهای اصلی مانند '=', '+' و غیره را نیز ایجاد میکنیم. توکنهای NAME در واقع نام متغیرها هستند که با عبارت منظم [a-zA-Z_][a-zA-Z0-9_]* قابل تعریف هستند. توکنهای STRING مقادیر رشتهای هستند و با علامت نقل قول (" ") محصور میشوند. این مورد میتواند با عبارت منظم \".*?\" تعریف شود.
هرگاه رشتهای از ارقام پیدا کنیم، باید آن را به توکن NUMBER اختصاص دهیم و عدد باید به عنوان یک عدد صحیح ذخیره شود. ما در حال ساختن یک اسکریپت برنامهنویسی ساده هستیم، بنابراین فقط با اعداد صحیح آن را انجام میدهیم، اما برای اعداد اعشاری، اعداد طولانی و غیره احساس راحتی کنید که همان راه حل را گسترش دهید. ما همچنین میتوانیم توضیحات بدهیم. هرگاه " //" را بیابیم، هر چیزی که در خط بعدی از آن آمده را نادیده میگیریم. همین کار را با کاراکتر خط جدید نیز انجام میدهیم. بنابراین یک لکسر ابتدایی را ساختیم که جریان کاراکتر را به جریان توکن تبدیل میکند.
و همچنین کد:
class BasicLexer(Lexer):
tokens = { NAME, NUMBER, STRING }
ignore = '\t '
literals = { '=', '+', '-', '/',
'*', '(', ')', ',', ';'}
# Define tokens as regular expressions
# (stored as raw strings)
NAME = r'[a-zA-Z_][a-zA-Z0-9_]*'
STRING = r'\".*?\"'
# Number token
@_(r'\d+')
def NUMBER(self, t):
# convert it into a python integer
t.value = int(t.value)
return t
# Comment token
@_(r'//.*')
def COMMENT(self, t):
pass
# Newline token(used only for showing
# errors in new line)
@_(r'\n+')
def newline(self, t):
self.lineno = t.value.count('\n')Building a Parser
ابتدا تمام ماژول های لازم را وارد میکنیم.
from sly import Parserحالا بیایید یک کلاس با نام BasicParser بسازیم که از کلاس Lexer گسترش میدهد. جریان توکن از BasicLexer به یک متغیر با نام tokens منتقل میشود. اولویتها تعریف شده است که برای اکثر زبانهای برنامهنویسی یکسان است. بیشتر پارسینگهای نوشته شده در برنامه زیر بسیار ساده است. وقتی چیزی وجود ندارد، عبارت چیزی را منتقل نمیکند. به طور اصولی میتوانید دکمه Enter را در صفحه کلید خود فشار دهید (بدون تایپ هیچ چیزی) و به خط بعدی بروید. سپس زبان شما باید قادر باشد با استفاده از "=" تخصیص داده شود. این در خط 18 برنامه زیر بررسی میشود. همین کار را میتوان برای تخصیص به رشته نیز انجام داد.
class BasicParser(Parser):
#tokens are passed from lexer to parser
tokens = BasicLexer.tokens
precedence = (
('left', '+', '-'),
('left', '*', '/'),
('right', 'UMINUS'),
)
def __init__(self):
self.env = { }
@_('')
def statement(self, p):
pass
@_('var_assign')
def statement(self, p):
return p.var_assign
@_('NAME "=" expr')
def var_assign(self, p):
return ('var_assign', p.NAME, p.expr)
@_('NAME "=" STRING')
def var_assign(self, p):
return ('var_assign', p.NAME, p.STRING)
@_('expr')
def statement(self, p):
return (p.expr)
@_('expr "+" expr')
def expr(self, p):
return ('add', p.expr0, p.expr1)
@_('expr "-" expr')
def expr(self, p):
return ('sub', p.expr0, p.expr1)
@_('expr "*" expr')
def expr(self, p):
return ('mul', p.expr0, p.expr1)
@_('expr "/" expr')
def expr(self, p):
return ('div', p.expr0, p.expr1)
@_('"-" expr %prec UMINUS')
def expr(self, p):
return p.expr
@_('NAME')
def expr(self, p):
return ('var', p.NAME)
@_('NUMBER')
def expr(self, p):
return ('num', p.NUMBER)
پارسر نیز باید عملیاتهای حسابی را پارس کند، که این کار با استفاده از عبارات انجام میشود. فرض کنید میخواهید چیزی مانند زیر داشته باشید. همه آنها به صورت خط به خط به جریان توکن تبدیل شده و خط به خط پارس میشوند. بنابراین، طبق برنامه بالا، a = 10 شبیه خط 22 است. همین کار برای b = 20 نیز صدق میکند. a + b شبیه خط 34 است که یک درخت تجزیهای (parse tree) به نمایش میگذارد ('add'، ('var'، 'a')، ('var'، 'b')).
GFG Language > a = 10
GFG Language > b = 20
GFG Language > a + b 30
اکنون جریان های توکن را به درخت تجزیه تبدیل کرده ایم. مرحله بعدی تفسیر آن است.
اجرا
تفسیر (Interpreting) یک روش ساده است. ایده اصلی این است که درخت را طی کرده و عملیات حسابی را سلسله مراتبی ارزیابی کنیم. این فرایند به صورت بازگشتی تکرار میشود تا کل درخت ارزیابی شده و پاسخ به دست آید. برای مثال، فرض کنید 5 + 7 + 4. این جریان کاراکتری ابتدا در یک لکسر به جریان توکنها تبدیل میشود. سپس جریان توکن به یک درخت تجزیه میشود. درخت تجزیه به طور اساسی (‘add’، (‘add’، (‘num’، 5)، (‘num’، 7))، (‘num’، 4)) را برمیگرداند. (تصویر زیر را ببینید)
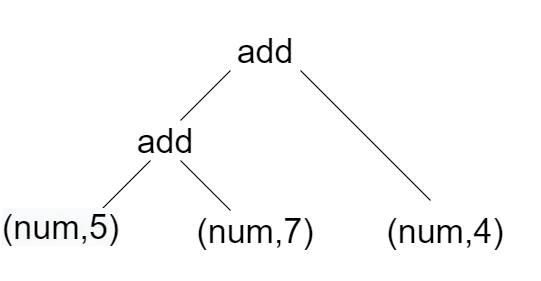
تفسیرگر ابتدا ۵ و ۷ را جمع میکند و سپس به صورت بازگشتی تابع walkTree را فراخوانی کرده و ۴ را به نتیجه جمع ۵ و ۷ اضافه میکند. بنابراین، ما عدد ۱۶ را دریافت میکنیم. کد زیر همین فرآیند را انجام میدهد.
class BasicExecute:
def __init__(self, tree, env):
self.env = env
result = self.walkTree(tree)
if result is not None and isinstance(result, int):
print(result)
if isinstance(result, str) and result[0] == '"':
print(result)
def walkTree(self, node):
if isinstance(node, int):
return node
if isinstance(node, str):
return node
if node is None:
return None
if node[0] == 'program':
if node[1] == None:
self.walkTree(node[2])
else:
self.walkTree(node[1])
self.walkTree(node[2])
if node[0] == 'num':
return node[1]
if node[0] == 'str':
return node[1]
if node[0] == 'add':
return self.walkTree(node[1]) + self.walkTree(node[2])
elif node[0] == 'sub':
return self.walkTree(node[1]) - self.walkTree(node[2])
elif node[0] == 'mul':
return self.walkTree(node[1]) * self.walkTree(node[2])
elif node[0] == 'div':
return self.walkTree(node[1]) / self.walkTree(node[2])
if node[0] == 'var_assign':
self.env[node[1]] = self.walkTree(node[2])
return node[1]
if node[0] == 'var':
try:
return self.env[node[1]]
except LookupError:
print("Undefined variable '"+node[1]+"' found!")
return 0نمایش خروجی
برای نمایش خروجی توسط تفسیرگر، باید چند کد بنویسیم. کد باید ابتدا لکسر را فراخوانی کند، سپس پارسر و سپس تفسیرگر و در نهایت خروجی را دریافت کند. سپس خروجی را در شل نمایش دهد.
if __name__ == '__main__':
lexer = BasicLexer()
parser = BasicParser()
print('GFG Language')
env = {}
while True:
try:
text = input('GFG Language > ')
except EOFError:
break
if text:
tree = parser.parse(lexer.tokenize(text))
BasicExecute(tree, env)
لازم به ذکر است که ما هیچ خطاهایی را مدیریت نکردهایم. بنابراین SLY هنگامی که شما چیزی را انجام میدهید که توسط قوانینی که نوشتهاید مشخص نشده است، پیام خطای خود را نشان خواهد داد.
زبانی که نوشتهاید را با استفاده از دستور زیر اجرا کنید:
py language.pyتفسیرگری که ساختیم بسیار پایه است. البته، این میتواند برای انجام بسیاری از کارها گسترش یابد. حلقهها و شرطها میتوانند اضافه شوند. قابلیتهای طراحی ماژولار یا شیگرا قابل اجرا است. ادغام ماژول، تعریف متد، پارامترها در متدها برخی از ویژگیهایی هستند که میتوانند به آن اضافه شوند.