
مقدمه:
به طور مختصر scrapy یک ابزار برای خزیدن (crawl) در صفحات وب به منظور استخراج بخشهای مورد نظر و انجام تحلیل روی دادههای به دست آمده، است.
در این مطلب ما ساخت یک خزنده ی وب ساده، برای دریافت اطلاعات از دو بخش دوره های آموزشی و واژه نامه از سایت سکان آکادمی را توضیح خواهیم داد. در انتهای این مقاله شما می توانید یک پروژه ی Scrapy ساده را پیاده سازی کنید و نتایج آن را ببینید.
شروع کار با scrapy
ابتدا مروری اجمالی بر معماری scrapy خواهیم داشت که در تصویر زیر مشاهده می شود:
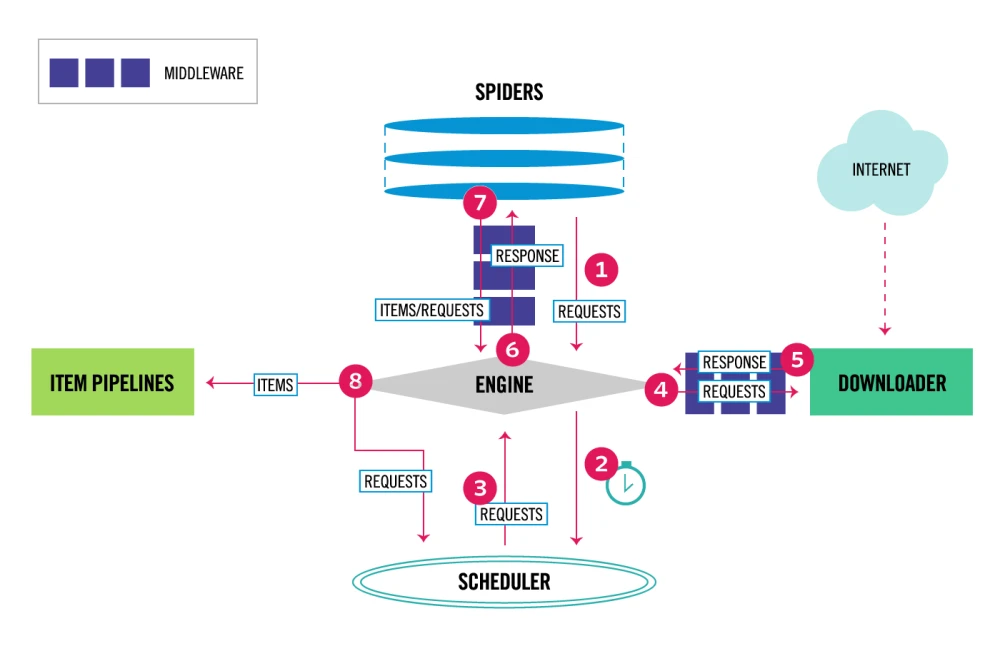
بخش های مختلف این معماری:
1- Scrapy Engine
مسئول کنترل جریان دادهها بین تمام اجزای سیستم و شروع رویدادها در زمانی است که اقدامات خاصی اتفاق می افتد.
2- Scheduler
بخش Scheduler وظیفه دریافت درخواست ها (requests) از موتور (engine) و صف بندی آن ها (enqueues) بر اساس اولویت پردازش را بر عهده دارد تا در آینده، موتور از این درخواست برای استفاده ی دیگر اجزا استفاده کند. هنگامی که engine به Scheduler اعلام نیاز می کند، Scheduler هر درخواستی که نوبت پردازش آن رسیده است را برای engine فراهم می کند.
3- Downloader
مسئول آوردن صفحات وب و تغذیه آنها به موتور است که هر صفحه را به نوبت برای spider ها ارسال می کند.
4- Spiders
به کلاس هایی که توسط برنامه نویس برای parse کردن جواب خزنده ها و extract کردن اجزا مختلف جواب نوشته شده اند، گفته می شود.
5- Item Pipeline
هر دادهای که توسط spider جداسازی میشود (scrap) به بخش pipeline منتقل خواهد شد. کاری که این بخش انجام می دهد عبارت است از:
- پاک کردن داده های
HTML.منظور پاک سازی تگ های HTML هست که در تحلیل داده کاربردی ندارند. - چک کردن مجدد دادهها به منظور جلوگیری از تکراری بودن دادهها. در صورت تکراری بودن، آنها را از حذف می کند.
- مرتب سازی دادهها در هنگام ذخیره سازی دادهها در پایگاه داده یا مرتب سازی دادههای scrap شده در پایگاه داده.
6- Downloader middlewares
واسط میانی بین downloader و engine برای پردازش درخواست ها قبل از رسیدن به downloader است.
7- Spider middlewares
واسط میانی بین spiders و engine برای پردازش درخواست ها قبل از رسیدن به spider است.
پیادهسازی خزنده برای سایت سکان آکادمی
نیازمندی ها:
برای راه اندازی این پروژه به پایتون 3 روی یکی از توزیع های لینوکس و همچنین یک IDE احتیاج دارید. ما در این مقاله با استفاده از Debian 10 این تمرین را پیش بردیم. شما نیز می توانید قبل از شروع این تمرین از نصب پایتون ورژن 3 به بالا روی لینوکس خود مطمئن شوید. برای این کار می توانید از آموزش نصب پایتون 3 روی دبیان 10 استفاده کنید.
در ابتدا نیاز هست روی سرور لینوکسی خود مقدمات پروژه ی Scrapy را آماده کنید به همین منظور مراحل زیر را پیش ببرید:
- ایجاد پوشه برای پروژه در شاخه opt
ابتدا برای پروژه سکان آکادمی یک پوشه به نام academy-project در شاخه opt با دستورهای زیر ایجاد می کنیم:
- برای ورود به شاخه
optدستور زیر را ایجاد می کنیم:
cd /opt- سپس با دستور زیر پوشه مورد نظر را می سازیم:
mkdir academy-project- با دستور cd درون شاخه
academy-projectورود می کنیم
2. نصب pip
ابتدا از نصب pip اطمینان حاصل کنید. با کمک pip می توانیم کتابخانه ها و پکیج های مربوط به پایتون را نصب کنیم برای نصب pip می توانید از دستور زیر استفاده کنید:
apt install python-pip3. نصب scrapy
سپس با دستور زیر scrapy را نصب می کنیم:
pip install scrapyسپس با دستور
pip freezeاز نصب scrapy اطمینان حاصل می کنیم.
یکی از ویژگیهای مهم scrapy توانایی خزیدن در چند لینک هم زمان با هم است. لذا ما از سایت سکان آکادمی دو بخش دوره های آموزشی و واژه نامه را scrap خواهیم کرد.
4. ایجاد پروژه
برای ایجاد یک پروژه scrapy از دستور زیر در مسیر opt/academy-project/ استفاده می کنیم:
scrapy startproject academy
پس از اجرای دستور بالا پروژه ای به نام academy ساخته میشود که درون IDE خود می توانیم ساختار آن را مشاهده کنیم.
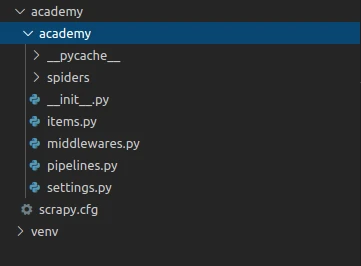
همانطور که مشاهده میشود با توجه به توضیحاتی که درباره معماری scrapy داده شد، فایلهایی مربوط به هر قسمت از معماری ایجاد شده است.
5. ساخت یک Spider جدید
Spider های پروژه، درون پوشه ای به نام spiders ساخته میشوند. به همین منظور ما درون این پوشه یک کلاس به نام AcademySpider که از کلاس Spider ارث بری می کند، می سازیم.
یک spider ابتدا یک نام مخصوص به خود را دارد. به عبارتی اگر ما در یک پروژه چند spider داشته باشیم هر spider باید نام مخصوص به خودش را داشته باشد. برای تعریف نام spider فیلد name در spider را مقدار دهی می کنیم. نام spider پروژه academy است.
import scrapy
class AcademySpider(scrapy.Spider):
name="academy"یک spider لیستی از url ها را دریافت و سپس به هرکدام با دستور request، درخواست می فرستد. پس از دانلود کامل صفحه برای استخراج داده (scrap) اجزای مختلف صفحه آن را به یک متد به نام parse، پاس می دهد که در ادامه به توضیح آن می پردازیم.
پس کافیست فیلد start_urls که متغیری از نوع لیست است را مقدار دهی کنیم و لیست url های پروژه که می خواهیم داده های آن ذخیره شود را در آن ایجاد کنیم.
سپس همان طور که گفتیم لازم است متدی به نام parse را در کلاس Spider که ما آن را مطابق با پروژه خودمان override می کنیم، ایجاد کنیم که این متد یک شی با نام response که از نوع TextResponse است را دریافت می کند.
هنگامی که یک Spider کار خود را شروع می کند متد start_requests را صدا زده و لیست url ها را دریافت و شروع به دانلود آنها می کند.
البته ما در ادامه فقط با لینک مربوط به دوره ها شروع می کنیم تا نکات لازم را توضیح دهیم سپس لینک مربوط به واژه نامه ها را اضافه کرده و فقط خروجی را مشاهده خواهیم کرد.
6. پیادهسازی متد parse:
متد parse برای جداسازی اطلاعات مورد نیاز ما از صفحه دانلود شده مورد استفاده قرار می گیرد، بنابراین ما باید مطابق با پروژه خودمان آن را دوباره نویسی کنیم.
یک متد به نام parse را ایجاد می کنیم. سپس باید در بدنه ی متد، کد مربوط به دریافت موضوع دوره را بنویسیم.
def parse(self, response):برای جداسازی اجزای مختلف صفحه ای که می خواهیم کرال کنیم، انتخاب گر (selector) های مختلفی را می توانیم استفاده کنیم. از جمله انتخاب به وسیله css یا xpath یا دیگر selector ها. ما در این پروژه از انتخاب گرهای css استفاده خواهیم کرد. ابتدا لینک مربوط به دوره ها را در مرورگر باز کرده و روی یک دوره راست کلیک کرده و آن را inspect می کنیم.
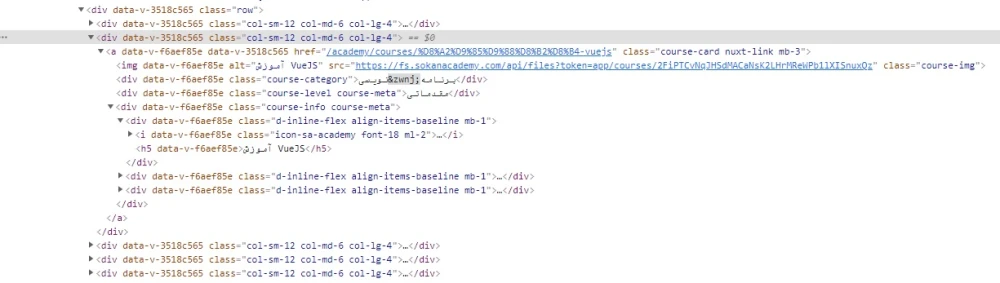
با inspect کردن یک دوره می بینیم این دوره درون یک div با کلاس col-sm-12 col-md-6 col-lg-4 قرار گرفته است که درون این div تگ های بسیاری دیده میشوند.
همان طور که مشاهده می کنید:
- موضوع پروژه در یک تگ
H5قرار دارد. - لینک در یک تگ a قرار دارد.
- سطح دوره در
Divکه کلاسcourse-level course-metaرا دارد.
ابتدا تگ div با کلاس col-sm-12 col-md-6 col-lg-4 را جدا کرده و سپس درون متغیری به نام panel ذخیره می کنیم. سپس ما از متغیر panel برای دریافت باقی موارد استفاده می کنیم.
برای دریافت عنوان دوره از panel تگ h5 را پیدا کرده و text درون آن را با متد get در متغیر title ذخیره می کنیم و سپس آن را yield می کنیم.
def parse(self, response):
panel = response.css("div[class='col-sm-6 col-md-4']")
title=panel.css("h5::text").get()
yield {"cource_title": title}برای اجرا و مشاهده خروجی از دستور زیر در ترمینال استفاده می کنیم.
scrapy crawl academyدستور بالا spider مارا شناسایی و آن را اجرا می کند.

همان طور که مشاهده می کنید عنوان دوره در خروجی وجود دارد.
به منظور مشاهده بهتر خروجی با اضافه کردن برخی تنظیمات به فایل settings پروژه، از این به بعد خروجی را دریک فایل z ذخیره کرده و مشاهده می کنیم. برای این کار فایل settings.py را باز کرده و مقدار زیر را به انتهای فایل اضافه کنید.
FEED_EXPORT_ENCODING=’UTF-8’اضافه کردن این مقدار به فایل تنظیمات برای پشتیبانی از حروف با encoding یوتی اف 8 hsj تا حروف فارسی در فایل json به درستی نشان داده شوند.
با توجه به نکته ذکر شده در بالا، پروژه را این بار با دستور زیر اجرا کنید:
scrapy crawl academy -o academy.jsonپس از اجرای دستور بالا یک فایل به نام academy.json در پروژه ایجاد میشود که نتیجه کراول ما در آن ذخیره شده است.

اکنون که با برخی دستورهای ساده scrapy آشنا شدیم لینک مربوط به واژه نامه سایت sokanacademy را در لیست urls ها قرار می دهیم.
به دلیل اینکه یک callback به نام parse داریم و callback دیگری پیاده سازی نکردیم. حالا متد parse را به صورت زیر تغییر می دهیم.
def parse(self, response):
page_title=response.url.split("/")[-1]
if page_title=="academy":
courses_section = response.css("div[class='academy-index-courses-wrapper']")
panels = courses_section.css("div[class='col-sm-12 col-md-6 col-lg-4']")
for panel in panels :
title = panel.css("h5::text").get()
level = panel.css("div[class='course-level course-meta']::text").get()
link = panel.css("a::attr(href)").get()
yield {"section":page_title,"cource_title": title , "level" :level , "link" :link }
if page_title=="glossary":
panels = response.css("div[class='col-sm-12 col-md-6 col-lg-4']")
for panel in panels :
title = panel.css("h4::text").get()
translate = panel.css("h6::text").get()
yield {"section":page_title,"word": title , "translate": translate }به طور خلاصه در کد بالا دو صفحه را کرال کرده و داده های آن را استخراج می کند. صفحه ی مربوط به دوره ها که 9 دوره ی آخر را به همراه اسم و سطح دوره و لینک آن و صفحه ی مربوط به فن واژه یا همان واژه نامه که همه ی کلمات به همراه معنی آن را استخراج می کند.
پروژه را با دستور زیر مجددا اجرا و نتیجه را در خروجی مشاهده می کنیم.
scrapy crawl academy -o academy.json
[
{"section": "academy", "cource_title": "آموزش گام به گام Elasticsearch", "level": "مقدماتی", "link": "/academy/courses/%D8%A2%D9%85%D9%88%D8%B2%D8%B4-%DA%AF%D8%A7%D9%85-%D8%A8%D9%87-%DA%AF%D8%A7%D9%85-elasticsearch"},
{"section": "academy", "cource_title": "آموزش VueJS", "level": "مقدماتی", "link": "/academy/courses/%D8%A2%D9%85%D9%88%D8%B2%D8%B4-vuejs"},
{"section": "academy", "cource_title": "آموزش کاربردی داکر", "level": "مقدماتی", "link": "/academy/courses/%D8%A2%D9%85%D9%88%D8%B2%D8%B4-%DA%A9%D8%A7%D8%B1%D8%A8%D8%B1%D8%AF%DB%8C-%D8%AF%D8%A7%DA%A9%D8%B1"},
{"section": "academy", "cource_title": "OWASP TOP10", "level": "مقدماتی", "link": "/academy/courses/owasp-top10"},
{"section": "academy", "cource_title": "GraphQL", "level": "مقدماتی", "link": "/academy/courses/graphql"},
{"section": "academy", "cource_title": "آموزش کاربردی گیت برای برنامه نویسان", "level": "پیشرفته", "link": "/academy/courses/%D8%A2%D9%85%D9%88%D8%B2%D8%B4-%DA%A9%D8%A7%D8%B1%D8%A8%D8%B1%D8%AF%DB%8C-%DA%AF%DB%8C%D8%AA-%D8%A8%D8%B1%D8%A7%DB%8C-%D8%A8%D8%B1%D9%86%D8%A7%D9%85%D9%87-%D9%86%D9%88%DB%8C%D8%B3%D8%A7%D9%86"},
{"section": "academy", "cource_title": "آموزش ردیس", "level": "پیشرفته", "link": "/academy/courses/%D8%A2%D9%85%D9%88%D8%B2%D8%B4-%D8%B1%D8%AF%DB%8C%D8%B3"},
{"section": "academy", "cource_title": "آموزش npm", "level": "پیشرفته", "link": "/academy/courses/%D8%A2%D9%85%D9%88%D8%B2%D8%B4-npm"},
{"section": "academy", "cource_title": "آموزش OAuth و Laravel Passport", "level": "پیشرفته", "link": "/academy/courses/%D8%A2%D9%85%D9%88%D8%B2%D8%B4-oauth-%D9%88-laravel-passport"},
{"section": "glossary", "word": "Abstraction", "translate": "(انتزاع)"},
{"section": "glossary", "word": "Encapsulation", "translate": "(كپسوله كردن)"},
{"section": "glossary", "word": "goal gradient effect", "translate": "(اثر شیب هدف)"},
{"section": "glossary", "word": "Semantic Error", "translate": "(خطای سمنتیک)"},
{"section": "glossary", "word": "Syntax (سینتکس)", "translate": "(قواعد نوشتاری زبان برنامه نویسی)"},
{"section": "glossary", "word": "Regression Testing", "translate": "(regression testing)"},
{"section": "glossary", "word": "Interface Testing", "translate": "(تست رابط)"},
{"section": "glossary", "word": "Smoke Testing", "translate": "(تست smoke)"},
{"section": "glossary", "word": "Sanity Testing", "translate": "(تست sanity)"},
{"section": "glossary", "word": "Incremental Integration Testing", "translate": "(تست یکپارچه افزایشی)"},
{"section": "glossary", "word": "Integration Testing", "translate": "(تست ادغام)"},
{"section": "glossary", "word": "Component Testing", "translate": "(تست کامپوننت)"}در نهایت کد کامل این کرال را اگر بخواهیم تمام دوره ها و واژه هایی که در صفحه جاری نشان داده شده اند ببینیم کلاس AcademySpider را به صورت زیر کامل می کنیم.
کد کامل پروژه:
import scrapy
class AcademySpider(scrapy.Spider):
name = "academy"
start_urls=[
'https://sokanacademy.com/academy',
'https://sokanacademy.com/glossary'
]
def parse(self, response):
page_title=response.url.split("/")[-1]
if page_title=="academy":
courses_section = response.css("div[class='academy-index-courses-wrapper']")
panels = courses_section.css("div[class='col-sm-12 col-md-6 col-lg-4']")
for panel in panels :
title = panel.css("h5::text").get()
level = panel.css("div[class='course-level course-meta']::text").get()
link = panel.css("a::attr(href)").get()
yield {"section":page_title,"cource_title": title , "level" :level , "link" :link }
if page_title=="glossary":
panels = response.css("div[class='col-sm-12 col-md-6 col-lg-4']")
for panel in panels :
title = panel.css("h4::text").get()
translate = panel.css("h6::text").get()
yield {"section":page_title,"word": title , "translate": translate }