
ساختار داده یک واژه خاص برای مفهوم ذخیره سازی و مدیریت داده ها در علوم کامپیوتر است. این ذخیره سازی به صورتی است که امکان انجام عملیات های مختلف (مثل جستجو) روی داده ها راحت تر و کارآمدتر باشد. در علوم کامپیوتر ساختار داده های مختلفی وجود دارد و کاربرد آن ها بازه وسیعی از این علم را در بر می گیرد.
ساختار داده ها در اکثر زبان های برنامه نویسی استفاده و پیاده سازی شده است. از طرفی ساختار داده یک مفهوم بنیادی در علوم کامپیوتر است که می توان بسیاری از آن ها را در هر زبانی پیاده سازی کرد (اگر به صورت پیشفرض در زبانی پیاده سازی نشده باشد). همچنین این مفهوم در مصاحبه های مهندسی نرم افزار یک مفهوم بسیار مهم و کلیدی است و در بسیاری از مصاحبه ها از آن یاد می شود (یکی از تفاوت های برنامه نویس خوب با دیگران درک بهتر و آشنایی بیشتر با ساختار داده هاست!). بنابراین به عنوان یک برنامه نویس، بهتر است با این مفاهیم آشنا باشید. در مقاله ی قبل 4 مورد از ساختار داده ی پرکاربرد در علوم کامپیوتر را بررسی کردیم. در این مقاله به ادامه ی آنها می پردازیم.
5 – Hash Table (جدول در هم سازی):
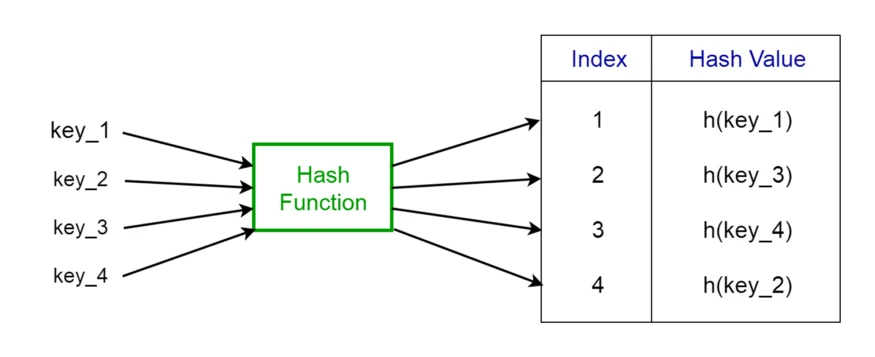
Hash Table ساختار داده ای است که مقادیر را به همراه کلیدی که با آن ها در ارتباط است ذخیره می کند. این به این معنی است که اگر بخواهیم مقدار y را در Hash Table ذخیره کنیم، کلید x مربوط به آن با مقدار y در ارتباط خواهد بود (مقدار کلید بر اساس مقدار y ساخته می شود). از این رو، در این ساختار داده اگر کلید مربوطه را پیدا کنیم، جستجو بسیار سریع خواهد بود. در این ساختار داده، اگر از اندازه داده ها صرف نظر کنیم، عملیات افزودن و جستجو بسیار کارآمد است.
همانطور که گفته شد، کلید x مربوط به y در Hash Table با آن در ارتباط است و بر اساس مقدار y ساخته می شود. برای تولید این کلید از تابعی به نام Hash Function استفاده می شود. به طور مثال ساده ترین Hash Function می توان به صورت تابع زیر باشد:
f(y) = y mod mدر مثال بالا به ازای هر y یک x تولید می شود (y مقداری که می خواهیم ذخیره کنیم و x کلید آن است). در این مثال مقدار m اندازه تابع است. اما تابع بالا یک تابع بهینه و مناسب نیست! دلیل آن این است که Hash Function باید یک تابع یک به یک باشد که به ازای هر y یک x یکتا تولید کند. اگر این تابع این گونه نباشد (یعنی به ازای دو y مختلف یک x تولید کند)، با مساله collision روبرو می شویم که باعث بروز مشکلاتی در ساختار داده می شود (دقت کنید که مقدار x تولید شده بر اساس y، کلید جدول است و در یک جدول، کلید باید یکتا باشد). فرض کنید می خواهیم مقادیر زیر را توسط Hash Function بالا در Hash Table ذخیره کنیم:
1 => 1 % 20 = 1
5 => 5 % 20 = 5
23 => 23 % 20 = 3
63 => 63 % 20 = 3همانطور که می بینید به ازای مقدار 23 و 63 یک عدد یکسان به دست آمد. برای حل این مشکل بایستی یک Hash Function مناسب انتخاب شده و از تکنیک هایی مانند chaining و open addressing استفاده شود.
مثال های کاربردی استفاده از Hash Table:
- استفاده برای پیاده سازی index ها در پایگاه داده
- استفاده برای پیاده سازی آرایه های مرتبط به هم
- استفاده برای پیاده سازی ساختار داده set
6 – درخت (Tree):
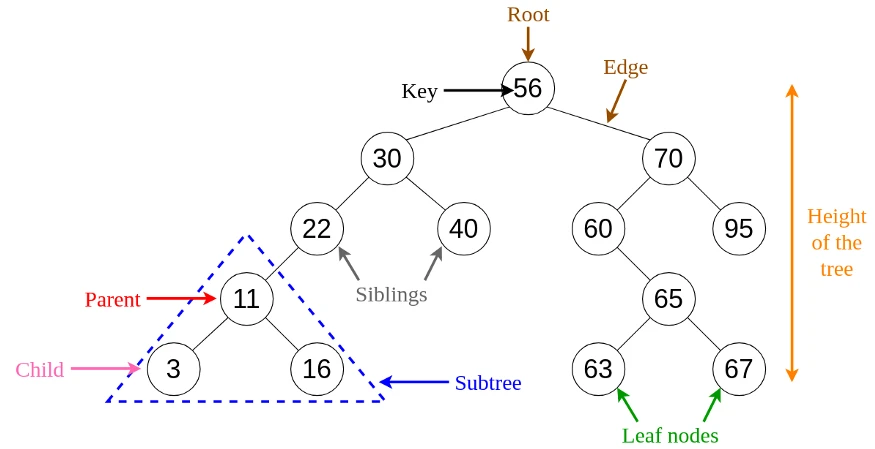
درخت یک ساختار سلسله مراتبی است که داده ها در آن به صورت سلسله مراتبی و متصل به یگدیگر ذخیره می شوند. این ساختار با لیست پیوندی تفاوت دارد. چرا که در لیست پیوندی اتصال داده ها به صورت خطی است اما در درخت اینطور نیست. در سال های گذشته درخت های مختلفی برای رفع نیازهای مختلف طراحی و پیاده سازی شده اند که از معروف ترین آن ها می توان به درخت جستجو دودویی، B Tree، treap و ... اشاره کرد.
هر المان در درخت با نام node شناخته می شود. در درخت دو node خاص وجود دارد:
- node : Root ابتدایی و بالاترین node درخت است که والدی ندارد.
- Leaf: آخرین node های درخت هستند که فرزندی ندارند.
درخت جستجو دودویی:
درخت دودویی (یا binary search tree یا به اختصار BST) نوع خاصی از درخت هاست که هر المان در درخت شامل دو المان زیرمجموعه (فرزند) است که به آن متصل هستند. یک درخت دودویی شامل خصوصیات زیر است:
- کلید (Key): مقدار ذخیره شده در درخت
- Right: اشاره گر به فرزند راست
- Left: اشاره گر به فرزند چپ
- P: اشاره گر به node پدر
همچنین درخت جستجو دودویی شامل یک ویژگی منحصر به فرد است که آن را از بقیه درخت ها متمایز میکند. این ویژگی دو شرط زیر است:
- اگر y یک node از درخت باشد و x فرزند چپ آن، همیشه y.key >= x.key
- اگر y یک node از درخت باشد و x فرزند راست آن، همیشه y.key <= x.key
مثال های کاربردی استفاده از درخت:
- درخت های جستجو دودویی: استفاده به عنوان یک ساختار داده برای جستجو مخصوصا در زمانی که داده ها به صورت مداوم به ساختار اضافه و حذف می شوند.
- Heap ها: استفاده شده در JVM (Java Virtual Machine) برای ذخیره سازی object های Java.
- Treap ها: استفاده شده در شبکه های Wireless.
7 – Heap:
Heap نوع خاصی از درخت های دودویی است که در آن node ها با توجه به مقدار فرزندانشان سنجیده شده و جایگذاری می شوند. برای درک بهتر Heap ها می توان آن ها را به صورت درخت یا آرایه به نمایش در آورد. به شکل های زیر توجه کنید.
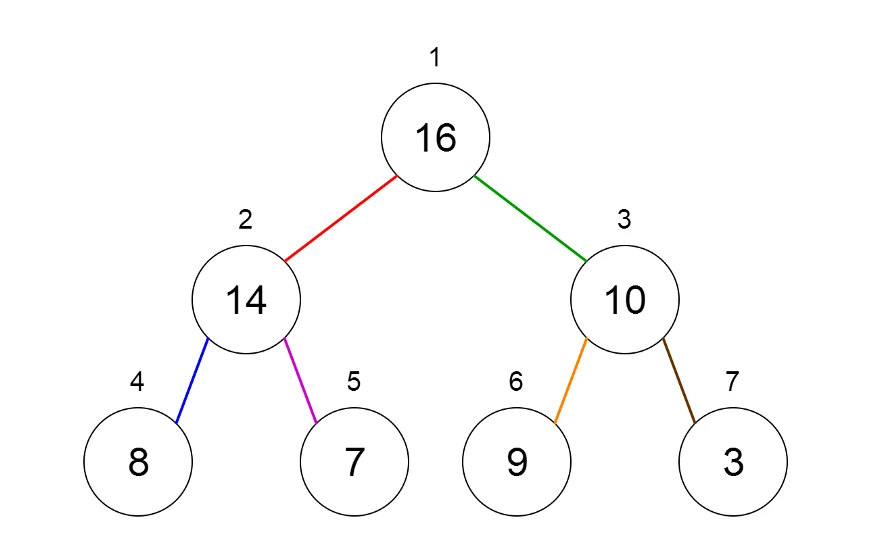
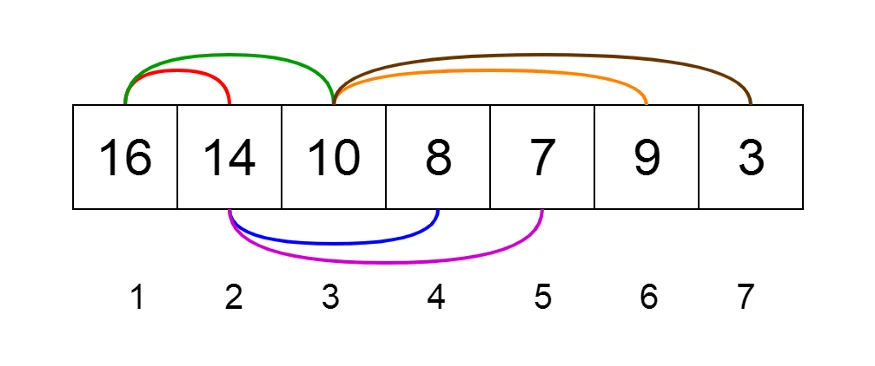
Heap ها دو نوع هستند:
- Min Heap: در این نوع، مقدار هر والد باید از فرزندان خود بزرگتر یا برابر با آن ها باشد. بنابراین در این درخت root بیشترین مقدار ساختار را دارد.
- Max Heap: در این نوع، مقدار هر والد باید از فرزندان خود کوچکتر یا برابر با آن ها باشد. بنابراین در این درخت root کمترین مقدار ساختار را دارد.
مثال های کاربردی استفاده از Heap ها:
- استفاده در الگورتیم مرتب سازی Heap sort
- استفاده برای پیدا کردن کوچکترین یا بزرگترین المان n ام در آرایه ها (مثلا سومین المان کوچک در آرایه)
8 – گراف (Graph):
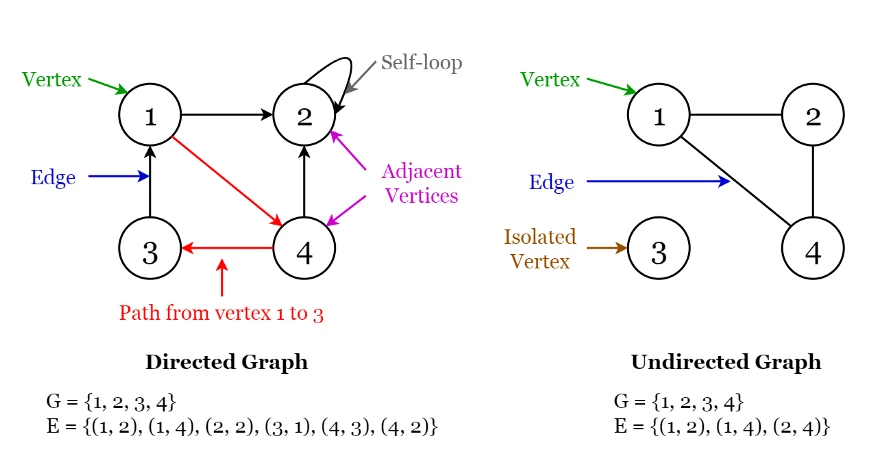
یک گراف از تعداد محدودی راس (Vertex) و تعدادی یال (Edge) که این رئوس را به یکدیگر متصل می کنند تشکیل شده است. هر گراف دارای دو خصوصیت مهم زیر است:
- درجه (Order): تعداد رئوس گراف
- اندازه (Size): تعداد یال های گراف
در یک گراف اگر دو راس به یکدیگر متصل شوند، همجوار(adjacent) نام برده می شوند.
گراف ها انواع مختلفی دارند:
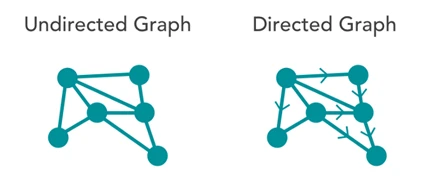
- گراف های جهت دار (Directed Graph): در این نوع، یال ها از یک راس به راس دیگر هدایت می شوند. به طور مثال مسیری از راس x به راس y وجود دارد اما از y به x مسیری نیست. این نوع گراف ها روابط نامتقارن در بین رئوس را نشان می دهند.
- گراف های بدون جهت (Undirected graphs): در این نوع، یال ها یک راس را به راس دیگر متصل می کنند، اما جهت رابطه مشخص نیست. گراف های بدون جهت، روابط متقارن را بیان می کنند.
- گراف های وزن دار (Weighted graphs): یک گراف وزنه دار، دارای یال هایی است که عددی به عنوان وزن بر روی آن ها تعریف می شود. این وزنه ها برای مشکلاتی نظیر کوتاه ترین مسیر کاربرد دارند.
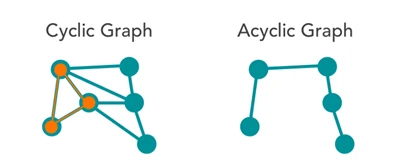
- گراف های چرخشی (Cyclic graphs): گراف چرخشی، مسیری از حداقل یک راس به سمت همان راس دارد.
مثال های کاربردی استفاده از گراف:
- استفاده در شبکه های اجتماعی. هر کاربر یک راس بوده و اتصالات کاربران توسط یال ها در نظر گرفته می شود.
- استفاده برای ارایه و نمایش صفحات وب و اینکه چگونه به یکدیگر لینک شده اند. این موضوع در موتورهای جستجو بسیار کارآمد است و باعث می شود صفحات بر اساس لینک های ارجاع شده بهتر رتبه بندی شوند.
- استفاده از سیستم های مبتنی بر نقشه و GPS. هر نقطه یک راس در نظر گرفته شده و مسیرها توسط یال ها نمایش داده می شوند. برای پیدا کردن کوتاه ترین مسیر می توان از گراف وزن دار استفاده کرد.
همچنین شما می توانیدبرای مطالعه بیشتر مقاله تحلیل گراف و کاربرد تحلیل گراف در خدمات مالی و صنعت از سکان آکادمی را مطالعه کنید.
سخن پایانی
در عصر حاضر علوم کامپیوتر روز به روز در حال پیشرفت و همه گیر شدن است. اگر به عنوان یک توسعه دهنده یا برنامه نویس در حال فعالیت در این حوزه هستید، علاوه بر فراگیری زبان های برنامه نویسی بایستی با مهارت های نرم علوم کامپیوتر نیز آشنا باشید. یکی از مهمترین این مهارت ها آشنایی با ساختار داده هاست که در بسیاری از مصاحبه های کاری (مصاحبه های حرفه ای!) نیز نکته کلیدی در انتخاب کارجوست! در این مقاله سعی شد 8 مورد از پرکاربردترین ساختارهای داده نام برده شود و توضیحات مختصری درباره هر یک ارائه شد. پیشنهاد میکنم مطالعات خود را بر روی این مهارت بیشتر کنید، دمنوش (یا قهوه) بنوشید و از برنامه نویسی و زندگی لذت ببرید!
پویا و سرزنده باشید