در بخش قبل، مقدمهای از کلاس های داده در پایتون را مطرح کردیم. در ادامه به نکات بیشتری درباره آنها می پردازیم.
آیا DataClass در همه شرایط خوب است؟
اکنون که با کارکردهای جالب توجه DataClass آشنا شدیم، ممکن است به این جمعبندی برسیم که بهتر است در همهی شرایط از Dataclassها استفاده کنیم، اما واقعیت این است که Dataclassها در همه شرایط عملکرد خوبی ندارند و گاهی اوقات باید از گزینههای جایگزین استفاده کنیم. بهتر است برای تشریح موضوع به مثال عملی دیگری اشاره کنیم:
from dataclasses import dataclass
@dataclass
class DataClassCard:
rank: str
suit: strیک کلاس داده عملکردهای پایهای را توسعه داده و به شکل ساده در اختیار برنامهنویسان قرار میدهد. به عنوان مثال، میتوانید نمونههایی از کلاس داده را برای انجام کارهایی مثل چاپ و مقایسه مورد استفاده قرار دهید:
>>> queen_of_hearts = DataClassCard('Q', 'Hearts')
>>> queen_of_hearts.rank
'Q'
>>> queen_of_hearts
DataClassCard(rank='Q', suit='Hearts')
>>> queen_of_hearts == DataClassCard('Q', 'Hearts')
Trueمقدار بازگشتی برابر با True است.
کلاس فوق را با یک کلاس معمولی مقایسه کنید. یک کلاس معمولی در کمترین حالت شبیه به قطعه کد زیر است:
class RegularCard:
def __init__(self, rank, suit):
self.rank = rank
self.suit = suitدر حالی که قطعه کد بالا، زیاد نیست، اما بازهم چند ایراد بزرگ بر آن وارد است. اول آنکه نشانههایی از تکرار فیلدها را مشاهده میکنید. rank و suit هر دو سه مرتبه برای مقداردهی اولیه یک شی تکرار میشوند. همچنین، اگر سعی کنید از این کلاس ساده استفاده کنید، متوجه خواهید شد که نمایش اشیا چندان توصیفی نیستند و در مقایسه با قطعه کدی که پیشتر نوشتیم، خیلی جالب نیستند:
>>> queen_of_hearts = RegularCard('Q', 'Hearts')
>>> queen_of_hearts.rank
'Q'
>>> queen_of_hearts
<__main__.RegularCard object at 0x7fb6eee35d30>
>>> queen_of_hearts == RegularCard('Q', 'Hearts')
Falseکلاسهای داده، کارهایی در پشت صحنه انجام میدهند تا بخشی از وظایف برنامهنویسان کمتر شود. بهطور پیشفرض، کلاس داده یک متد ()__repr__ را برای نمایش زیباتر یک رشته و یک متد ()__eq__ که میتواند مقایسههای اصلی میان اشیا را انجام دهد، پیادهسازی میکنند. برای اینکه کلاس RegularCard از کلاس داده بالا منشعب شود باید متدهای زیر را به آن اضافه کنید:
class RegularCard
def __init__(self, rank, suit):
self.rank = rank
self.suit = suit
def __repr__(self):
return (f'{self.__class__.__name__}'
f'(rank={self.rank!r}, suit={self.suit!r})')
def __eq__(self, other):
if other.__class__ is not self.__class__:
return NotImplemented
return (self.rank, self.suit) == (other.rank, other.suit)جایگزینهایی برای کلاسهای داده
برنامهنویسان پایتون برای ساختارهای داده ساده، از یک تاپل (Tuple) یا لغتنامه (Dictionary) استفاده میکنند. شما میتوانید قطعه کد بالا را به یکی از روشهای فوق پیادهسازی کنید:
>>> queen_of_hearts_tuple = ('Q', 'Hearts')
>>> queen_of_hearts_dict = {'rank': 'Q', 'suit': 'Hearts'}قطعه کد بالا بدون مشکل کار میکند، با این حال، اگر قصد داشته باشید بر مبنای الگوی بالا کار کنید، باید کارهای زیر را انجام دهید:
باید به خاطر داشته باشید که متغیر queen_of_hearts یک کارت را نشان میدهد.
برای نسخه Tuple، باید ترتیب صفات را به خاطر بسپارید. نوشتن ('Spades', 'A') برنامه شما را به هم میریزد، اما به احتمال زیاد به شما پیام خطای قابل فهمی نشان نمیدهد.
اگر از نوع dictionary استفاده کنید، باید مطمئن شوید که نام ویژگیها {'value': 'A', 'suit': 'Spades'} هماهنگ هستند که همانطور که انتظار میرود ممکن است به درستی کار نکند. علاوه بر این، استفاده از این ساختارها ایدهآل و ساختیافته نیست.
>>> queen_of_hearts_tuple[0] # No named access
'Q'
>>> queen_of_hearts_dict['suit'] # Would be nicer with .suit
'Hearts'جایگزین بهتر namedtuple است. توسعهدهندگان پایتون برای ساخت ساختارهای داده کوچک قابل فهم و خواندنی از این روش استفاده میکنند. ما در واقع میتوانیم نمونه کلاس داده بالا را با استفاده از یک namedtuple شبیه به حالت زیر بازسازی کنیم:
from collections import namedtuple
NamedTupleCard = namedtuple('NamedTupleCard', ['rank', 'suit'])این تعریف از NamedTupleCard همان خروجی را ارائه میدهد که قطعه کد DataClassCard در اختیار ما قرار میدهد:
>>> queen_of_hearts = NamedTupleCard('Q', 'Hearts')
>>> queen_of_hearts.rank
'Q'
>>> queen_of_hearts
NamedTupleCard(rank='Q', suit='Hearts')
>>> queen_of_hearts == NamedTupleCard('Q', 'Hearts')
Trueاگر همه چیز به این شکل ساده و روان است، چرا باید از کلاسهای داده استفاده کنیم؟ اول از همه، کلاسهای داده دارای ویژگیهای منعطفتری نسبت به آن چیزی هستند که مشاهده کردیم. در عین حال، namedtuple دارای ویژگیهای دیگری است که همگی مطلوب نیستند. در هنگام طراحی، namedtuple در اصل یک تاپل عادی است و این موضوع را میتوان در قطعه کد زیر متوجه شد:
>>> queen_of_hearts == ('Q', 'Hearts')
Trueدر حالی که همه چیز ممکن است خوب به نظر برسد، اما عدم آگاهی در مورد یک نوع خاص میتواند منجر به بروز مشکلات ریزی شود که باعث میشود روند اشکالزدایی زمانبر شود. به طور مثال، در مواقعی که در نظر داریم دو کلاس nametuple را با یکدیگر مقایسه کنیم.
>>> Person = namedtuple('Person', ['first_initial', 'last_name']
>>> ace_of_spades = NamedTupleCard('A', 'Spades')
>>> ace_of_spades == Person('A', 'Spades')
Truenamedtuple با محدودیتهایی همراه است. به عنوان مثال، اضافه کردن مقادیر پیشفرض به برخی از فیلدهای یک namedtuple دشوار است. یک نام تاپل به شکل طبیعی تغییرناپذیر است. یعنی مقدار یک namedtuple هرگز نمیتواند تغییر کند. در برخی از برنامهها، حالت فوق عالی است، اما در بیشتر موارد به نوعهای دادهای نیاز دارید که انعطافپذیر باشند:
>>> card = NamedTupleCard('7', 'Diamonds')
>>> card.rank = '9'
AttributeError: can't set attributeنکتهای که باید در ارتباط با کلاسهای داده به آن اشاره کنیم، این است که کلاسهای داده قرار نیست به طور کامل جایگزین namedtuple شوند. به عنوان مثال، اگر نیاز دارید، ساختار داده شما مانند یک تاپل رفتار کند، یک named tuple بهترین انتخاب است.
جایگزین دیگری که وجود دارد که خود الهامبخش کلاسهای دادهای به شمار میرود، کتابخانه attrs است. با استفاده از attrs که باید با استفاده از دستور pip install attrs آنرا نصب کنید، می توان یک کلاس را به شرح زیر نوشت:
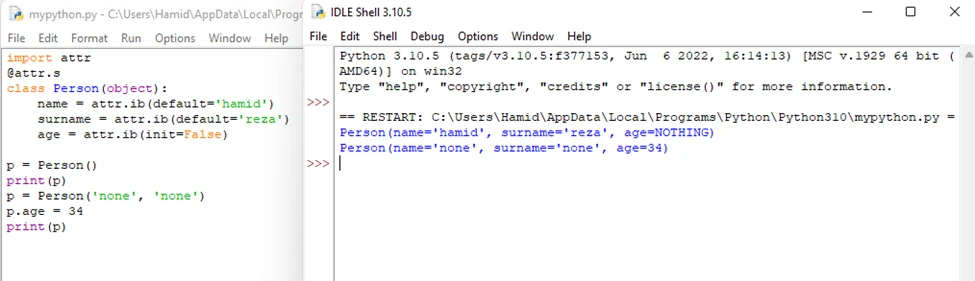
import attr
@attr.s
class Person(object):
name = attr.ib(default=Hamid)
surname = attr.ib(default=Reza')
age = attr.ib(init=False)
p = Person()
print(p)
p = Person('None', 'None')
p.age = 34
print(p)خروجی قطعه کد بالا به شرح زیر است:
attrs عالی است و از برخی ویژگیها پشتیبانی میکند که کلاسهای داده از آنها پشتیبانی نمیکنند که از آن جمله باید به تبدیلها و اعتبارسنجیها اشاره کرد. همچنین، attrsدر نسخههای مختلف پایتون مثل 2.7 و 3.4 و بالاتر پشتیبانی میشود. با این حال، از آنجایی که attrs بخشی از کتابخانه استاندارد نیست، یک وابستگی خارجی به پروژهها اضافه میکند. به همین دلیل، برخی برنامهنویسان ترجیح میدهند از کلاسهای داده برای انجام کارهای خود استفاده کنند.
علاوه بر tuple، dict، namedtuple و attrs، گزینههای دیگری در دسترس قرار دارند که از آن جمله باید به typing.NamedTuple ، namedlist ، attrdict ، plumber و fields اشاره کرد. در حالی که کلاسهای داده یک جایگزین خوب و البته جدید هستند، هنوز هم پروژههایی وجود دارند که نوعهای قدیمی عملکرد بهتری در آنها دارند. به عنوان مثال، اگر به سازگاری با یک API خاص نیاز دارید یا نیاز به عملکردی دارید که در کلاسهای داده پشتیبانی نمیشود، نوعهای قدیمی بهترین انتخاب هستند.
بهینهسازی کلاسهای داده
یکی از نکات مهمی که هنگام کار با کلاس دادهای باید به آن دقت کنید، بهینهسازی آنها است. برای این منظور باید از Slotsاستفاده کنید. اسلاتها را میتوان برای سریعتر کردن روند اجرای کلاسها و استفاده کمتر از حافظه مورد استفاده قرار داد. کلاسهای داده، الگوی خاصی برای تعریف و کار با اسلاتها ارائه نمیکنند، اما روش ساخت آنها پیچیده نیست و همه چیز به شکل سادهای انجام میشود. روند انجام اینکار به شرح زیر است:
from dataclasses import dataclass
@dataclass
class SimplePosition:
name: str
lon: float
lat: float
@dataclass
class SlotPosition:
__slots__ = ['name', 'lon', 'lat']
name: str
lon: float
lat: floatبه طور کلی، اسلاتها با استفاده از __slots__ برای فهرست کردن متغیرهای یک کلاس تعریف میشوند. در این حالت، متغیرها یا ویژگیهایی که در __slots__ وجود ندارند ممکن است تعریف نشده باشند. علاوه بر این، یک کلاس اسلات، ممکن است مقادیر پیشفرض نداشته باشد.
مزیت افزودن چنین محدودیتهایی این است که بهینهسازیهای خاصی ممکن است انجام شود. به عنوان مثال، کلاسهای اسلات حافظه کمتری را اشغال میکنند. جالب آنکه میزان مصرف حافظه آنها را میتوان با استفاده از Pympler به روش زیر اندازهگیری کرد:
>>> from pympler import asizeof
>>> simple = SimplePosition('London', -0.1, 51.5)
>>> slot = SlotPosition('Madrid', -3.7, 40.4)
>>> asizeof.asizesof(simple, slot)
(440, 248)به طور مشابه، کلاسهای اسلات در بیشتر موارد سریع هستند. در مثال زیر، با استفاده از timeit سرعت دسترسی به یک ویژگی در یک کلاس داده اسلات و یک کلاس داده معمولی را اندازهگیری کردیم:
>>> from timeit import timeit
>>> timeit('slot.name', setup="slot=SlotPosition('Oslo', 10.8, 59.9)", globals=globals())
0.05882283499886398
>>> timeit('simple.name', setup="simple=SimplePosition('Oslo', 10.8, 59.9)", globals=globals())
0.09207444800267695در مثال بالا، کلاس اسلات حدود 35 درصد سریعتر است.
کلام آخر
کلاسهای داده یکی از ویژگیهای جدید پایتون 3.7 هستند. با استفاده از کلاسهای داده، نیازی نیست برای انجام برخی کارهای ساده مثل مقایسه، نمایش و مقداردهی اولیه زحمات زیادی را متحمل شوید. اگر تمایل دارید از تکنیک فوق در پروژههای خود استفاده کنید، باید مراحل زیر را دنبال کنید:
- ابتدا کلاس داده را تعریف کنید.
- مقادیر پیشفرض را به فیلدهای کلاس داده اضافه کنید.
- به سفارشی سازی ترتیب اشیا کلاس داده بپردازید.
- از دکوراتور
dataclass@ماژولdataclassesبرای انشعاب یک کلاس از کلاس داده استفاده کنید. شی کلاس داده به طور پیش فرض متدهای__eq__و__str__را پیاده سازی میکند. - از توابع
astupleوasdictبرای تبدیل یک شی از یک کلاس داده به یک تاپل و دیکشنری استفاده کنید. - از frozen=True برای تعریف کلاسی استفاده کنید که اشیا آن تغییرناپذیر است.
- از متد
__post_init__برای مقداردهی اولیه ویژگیهایی که به ویژگیهای دیگر وابسته هستند، استفاده کنید. - از
sort_indexبرای تعیین ویژگیهای مرتبسازی اشیا کلاس داده استفاده کنید.