
در دنیای آی تی مواقع زیادی برایمان پیش میآید که می بایست کارهای تکراری را بارها و بارها انجام دهیم؛ در حین کار با فایلها و محتویات آنها نیز این قضیه صادق است به طوری که با استفاده از دستور sed و awk میتوان این نوع کارها را مدیریت کرد.
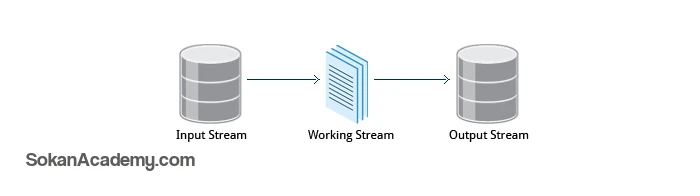
یک از ابزارهای پردازش متن معروف، قدیمی و کاربردی در سیستم عامل های مبتنی بر یونیکس، sed نام دارد که به منظور تغییر محتویات یک فایل به کار گرفته میشود (نام این دستور برگرفته از عبارت Stream Editor است.)
با استفاده از ابزار sed میتوان به فیلتر کردن متن و همچنین جایگزین کردن برخی واژگان به واژگانی دیگر پرداخت.
همانطور که در تصویر فوق مشخص است، دیتای مد نظر از Input Stream گرفته میشود سپس عملیات مد نظر در فاز Working Stream روی دیتای ورودی اعمال شده و در نهایت خروجی در Output Stream ذخیره میشود.
جهت آشنایی بیشتر با کاربرد دستور sed، فایلی میسازیم تحت عنوان file1 و عبارت This is sample text for file1 را وارد آن می کنیم:
$ cat > file1
This is sample text for file1
$حال دستور زیر را اجرا می کنیم:
$ sed s/is/are/ file1به عنوان خروجی دستور فوق داریم:
Thare is sample text for file1می بینم که واژه ی This به Thare تبدیل شده است: به عبارت دیگر، اولین نمونه از عبارت is با are جایگزین شده است. حال با استفاده از دستور cat محتویات فایل file1 را مشاهده می کنیم:
$ cat file1به عنوان خروجی دستور فوق داریم:
This is sample text for file1همان طور که ملاحظه می شود، محتویات فایل تغییر نکرده اند چرا که ما خروجی دستور sed را ذخیره نکردیم. برای جایگزین کردن عبارت is با are به صورت Global (گلوبال یا سراسری)، از دستور زیر استفاده می کنیم:
$ sed s/is/are/g file1به عنوان خروجی دستور فوق داریم:
Thare are sample text for file1می بینیم که کلیه ی واژگان is با are جایگزین شده اما کماکان تغییرات ذخیره نشده اند. برای ذخیره سازی تغییرات اعمال شده در فایل دیگری تحت عنوان file2، از دستور زیر استفاده می کنیم:
$ sed s/is/are/g file1 > file2اکنون اگر محتویات فایل file2 را با استفاده از دستور cat مشاهده کنیم، می بینیم که تغییرات روی محتویات file1 اعمال شده سپس نسخه ی ویرایش شده در file2 ذخیره شده اند:
Thare are sample text for file1آشنایی با کاربردهای دستور awk
ابزار awk معمولاً برای گزارش گیری از فایلهای مختلف مورد استفاده قرار میگیرد. این ابزار در Bell Labs در دهه ی ۱۹۷۰ میلادی توسعه یافت و وجه تسمیه ی آن برگرفته از نام توسعه دهندگانش Alfred Aho، Peter Weinberger، Brian Kernighan و است. ابزار awk قابلیتهای بیشماری دارد که از جمله ی مهمترین آنها میتوان به موارد زیر اشاره کرد:
- یک ابزار قدرتمند و یک زبان برنامه نویسی تفسیری است.
- برای پردازش متن، تهیه ی گزارش و ارائه ی گزارش های اطلاعاتی به کار گرفته میشود.
برای روشنتر شدن کاربرد ابزار awk ابتدا یک فایل جدید تحت عنوان testFile به صورت زیر میسازیم:
$ cat > testFile
password: 123456
username: bm
$حال دستور زیر را اجرا می کنیم:
$ awk -F: '{print $1}' testFileبه عنوان خروجی دستور فوق داریم:
password
username
در تفسیر خروجی بالا بایستی بگوییم که آپشن F- این امکان را به ما می دهد تا یک «جدا کننده ی فیلد» در نظر بگیریم که در اینجا : است. در واقع همان طور که در دیتابیس ما فیلدهای مختلفی برای یک جدول داریم، در لینوکس در فایل های متنی با استفاده از جدا کننده هایی همچون علامت : می توان فیلدهای مد نظر خود را مشخص ساخت. در ادامه داخل علامت های '{ }' دستور print را نوشته سپس 1$ را آورده ایم که منظور آن است که اولین فیلد (Column) در هر خط است.