ابتدا سعی میکنیم تعریف جامعی از الستیک سرچ (Elasticsearch) را به کمک مستندهای رسمی آن یاد بگیریم:
Elasticsearch یک موتور متن باز (Open Source) و بلادرنگ (real-time) برای تحلیل متون، جستجو و ذخیرهسازی انواع داده های نیمه ساختاریافته به صورت توزیع پذیر (distributable) است.
حال به جزییات قسمتهای مختلف تعریف بالا میپردازیم:
- متن باز بودن (open source): Elasticsearch با زبان برنامه نویسی جاوا توسعه داده شده است و سورس کد آن در سایت github.com قابل دسترس است.
- بلادرنگ بودن (real-time): Elasticsearch پس از ذخیره داده ها در کمترین فاصله آنها را برای جستجو آماده میکند. همان طور که در بخش قبل توضیح داده شد، دومین مرحلهی کار موتورهای جستجو، indexing یا شاخصگذاری کلمات کلیدی آنهاست. Elasticsearch به طور پیشفرض یک ثانیه پس از ثبت داده ها شروع به index کردن آنها میکند.
- تحلیل و جستجوی داده (analyze and search): منظور از تحلیل کردن داده ها، تبدیل آنها به فرمتی بهینه برای عملیات full text search است. پس از آن Elasticsearch میتواند به سرعت تمامی داده های مرتبط با یک عبارت مورد نظر را شناسایی و امتیازدهی کند. در خصوص روش های امتیازدهی دادهها در ادامهی دوره صحبت خواهیم کرد.
- پشتیبانی از داده های نیمه ساختاریافته (semi-structured): منظور از دادهی نیمه ساختاریافته این است که تمامی داده ها لزومی ندارد ساختار کاملا یکسان داشته باشند. برای مثال فرض کنید داده های log بازدید را داشته باشیم و برخی از این log ها دارای یک فیلد به نام event_id باشند و برخی دیگر آن را نداشته باشند اما در عین حال همگی آنها شامل فیلدهای مشترک source ، created_at و type باشند. در داده های ساختاریافته (structured) که به طور معمول در پایگاه داده ی رابطه ای از آنها استفاده میشود، تمامی داده ها باید ساختار کاملا یکسانی داشته باشند و برعکس در داده های بدونساختار (unstructured) هیچ شمای مشخصی در هیچ یک از فیلدهای دادهای آن وجود ندارد مانند داده های ویدیویی.
- توزیع پذیری (distributable): Elasticsearch به گونهای طراحی شده است که بتوان منابع مورد استفادهی آن را با کم ترین دردسر گسترش داد تا در صورت نیاز بتواند از حجم بالاتر داده ها و پردازشهای سنگین پشتیبانی کند. طراحی Elasticsearch بر اساس معماری cluster یا خوشه است. در این معماری تعدادی سرور که در یک شبکه به یکدیگر متصل هستند به عنوان یک سیستم واحد عمل کرده اند و ضمن ارتباط با یکدیگر درخواستهای دریافت شده را پاسخ میدهند. در رابطه با جزئیات طراحی Elasticsearch جلوتر توضیح داده خواهد شد.
ساختار ذخیره و بازیابی داده ها در Elasticsearch
Elasticsearch داده ها را در فرمت JSON میشناسد. در Elasticsearch به جای ساختار کلاسیک جدول ها و ستونها در پایگاه داده ی رابطه ای، مفاهیمی به نام index و document معرفی میشود. میتوان index را به عنوان جدول و document را ردیفی از جدول تصور کرد. هر Index مجموعهای از document هاست و داده هایی که در یک document ذخیره میشوند به صورت نیمه ساختاریافته هستند.
زمانیکه یک document در Elasticsearch ثبت میشود، علاوه بر اصل (source) داده های ورودی، بخشی از آن توسط تحلیلگرها (Analyzers) مورد پردازش قرار می گیرد و پس از پردازش به اجزایی کوچکتر (terms) تبدیل میشود. (در مورد شیوه ی کار تحلیلگرها و اصطلاحات مربوط به آن در قسمت بعدی عمیق تر توضیح داده خواهد شد). هدف از پردازش توسط تحلیلگرها، آمادهسازی داده ها برای شرکت در عملیات جستجو است. شاید بتوان گفت بدون تحلیلگرها، الستیک سرچ هیچ حرفی برای گفتن در زمینهی جستجو نداشت!
در تصویر زیر نمای کلی از فرایند تجزیه و تحلیل داده ها در ES را مشاهده میکنید:
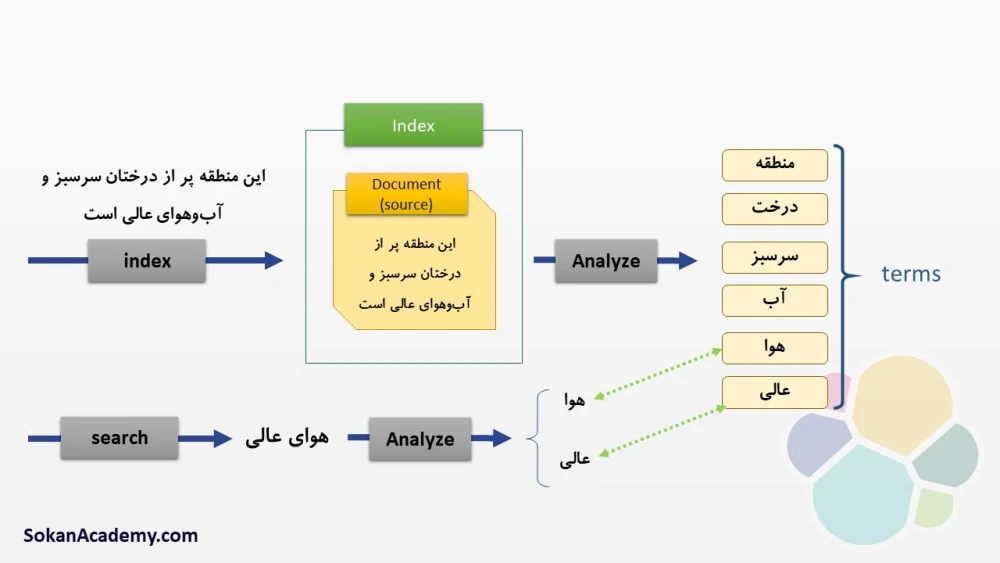
پس از ثبت داده ها، نوبت به جستجوی آنها میرسد. ES قدرت خود در جستجو را، از کتابخانهی Apache Lucene Search میگیرد. API های Elasticsearch به سادگی به شما اجازه میدهند تا Query های جستجو را به Elasticsearch ارسال کنید. همچنین تیم Elasticsearch اقدام به انتشار Client های مبتنی بر زبانهای برنامهنویسی مختلف کردهاند تا به سادگی بتوان در نرم افزارهای گوناگون از APIهای ارائهشدهی ES استفاده کرد.
طراحی مبتنی بر اصول "همیشه در دسترس بودن" و "توزیع پذیری"
یکی از نکته های مهم در Elasticsearch ، درنظر گرفتن طراحی توزیع پذیر (Distributable) آن است به طوری که امکان توسعه ی آن را بسیار ساده و پشتیبانی از حجم بالای داده ها و درخواست ها را امکان پذیر می کند.
افزون بر توزیع پذیری، ساختار Elasticsearch به گونه ای طراحی شده است که در صورت از دست رفتن قسمتی از منابع مورد استفادهی ES، دسترسی به داده ها تا حد امکان همچنان برقرار باشد. به عبارتی همواره نسخهی کپی از داده ها به صورت توزیع شده در منابع (سرورهای) مختلف وجود داشته باشد تا بتوان از آنها در مواقع نیاز استفاده کرد.
الستیک سرچ بر مبنای معماری خوشه بندی (cluster) طراحی شده است. در این معماری مجموعه ای از سرورها که گره نامیده میشوند، در یک شبکه ی داخلی به یکدیگر متصل شده و ضمن ارتباط درونی با یکدیگر، درخواست هایی که به سمت آنها ارسال میشود را، به گونه ای پاسخ میدهند که کاربر تصور میکند درخواست ارسال شده با یک سیستم یکپارچه پاسخ داده می شود. به عبارتی در این معماری فرقی نمیکند درخواست توسط کدام گره یا سرور دریافت شود و در صورت لزوم گره ها اطلاعاتی را مابین یکدیگر تبادل خواهند کرد و در نهایت پاسخ کاربر داده خواهد شد. بنابراین در Elasticsearch شما به سادگی میتوانید در صورت نیاز، گرهی جدیدی به خوشه اضافه کنید و Elasticsearch به طور خودکار بار درخواستها و داده ها را در سطح خوشه تعدیل میکند.