
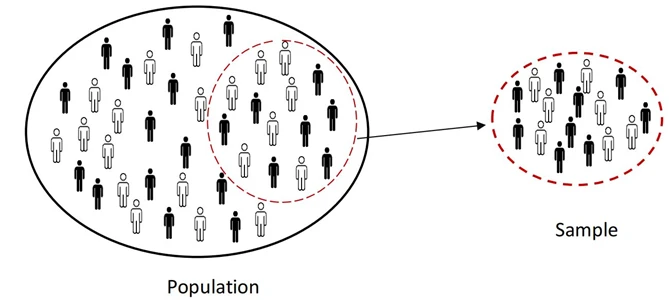
1. تفاوت بین جامعه و نمونه چیست؟
جامعه بیانگر همه مواردی است که در حال مطالعه آن هستید.نمونه زیرمجموعه محدودی از جامعه است که برای نمایش کل گروه، انتخاب می شود. یک نمونه معمولاً به این دلیل انتخاب میشود که مطالعه کامل جامعه، بسیار زمانبر و پرهزینه است. مثالی از دادههای جمعیت، سرشماری و مثالی از نمونه، نظرسنجی است.
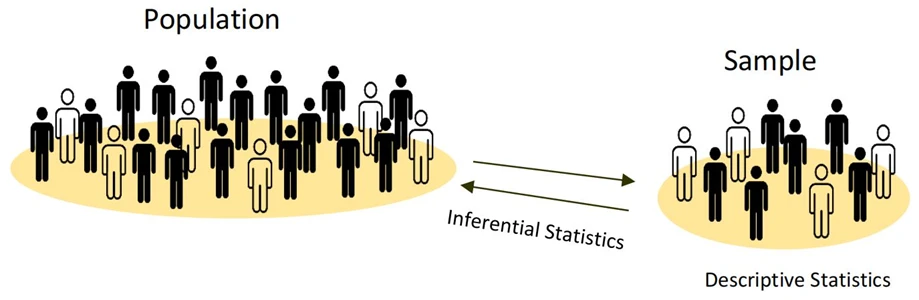
2. تفاوت آمار استنباطی و توصیفی چیست؟
- آمار توصیفی نمونه یا جامعه را توصیف میکند.
- آمار استنباطی سعی می کند از نمونهها استفاده کند تا در مورد جمعیت بزرگتر استنباط انجام دهد.
3. دادههای کمی و کیفی چیست؟
- برای دادههای کمی معیارها به صورت اعداد بیان میشوند (مثلاً چند بار، چقدر)
- برای دادههای کیفی معیارها از «انواع» هستند و ممکن است با نام، نماد یا کد عددی نشان داده شوند. دادههای کیفی به عنوان دادههای طبقهای نیز شناخته میشوند.
4. منظور از انحراف معیار چیست؟
انحراف معیار آماری است که پراکندگی یک مجموعه داده را نسبت به میانگین اندازهگیری میکند. این معیار، مقدار تنوع در مجموعه داده را نشان میدهد و به طور متوسط به شما میگوید که هر مقدار چقدر از میانگین فاصله دارد.
انحراف معیار بالا به این معنی است که مقادیر از میانگین فاصله دارند، در حالی که انحراف معیار پایین نشان می دهد که مقادیر نزدیک به میانگین خوشه بندی شدهاند.
انحراف معیار به صورت جذر واریانس و با تعیین انحراف هر نقطه داده نسبت به میانگین محاسبه میشود.
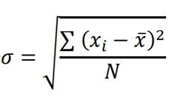
۵. مثالی بزنید که در آن میانه معیار بهتری نسبت به میانگین است.
زمانی میانه معیار بهتری برای گرایش مرکزی نسبت به میانگین است که توزیع مقادیر دادهها کج است یا زمانی که نقاط پرت واضح وجود دارد.
۶. چگونه حجم نمونه مورد نیاز را محاسبه میکنید؟
برای محاسبه حجم نمونه مورد نیاز برای یک نظرسنجی یا آزمایش:
- اندازه جمعیت را تعریف کنید: اولین مورد این است که تعداد کل جمعیت هدف خود را تعیین کنید.
- در مورد حاشیه خطا تصمیم بگیرید: این مورد که همچنین به عنوان "فاصله اطمینان" شناخته میشود، نشان میدهد که چقدر تفاوت بین میانگین نمونه و میانگین جامعه مجاز است.
- سطح اطمینان را انتخاب کنید: سطح اطمینان نشان میدهد که چقدر مطمئن هستید که میانگین واقعی در محدوده خطای انتخابی شما قرار می گیرد. رایجترین سطوح اطمینان 90٪، 95٪، و 99٪ است. سطح اطمینان مشخص شده با z-score مطابقت دارد.
- انحراف معیار را انتخاب کنید: در مرحله بعد، باید انحراف معیار یا سطح واریانسی را که انتظار دارید در اطلاعات جمعآوری شده مشاهده کنید، تعیین کنید. اگر نمی دانید چقدر واریانس باید انتظار داشته باشید، انحراف معیار 0.5 معمولاً یک انتخاب مطمئن است البته وقتی که اندازه نمونه شما به اندازه کافی بزرگ است.
- حجم نمونه خود را محاسبه کنید: در نهایت میتوانید از این مقادیر برای محاسبه حجم نمونه استفاده کنید. می توانید این کار را با استفاده از فرمول یا با استفاده از ماشین حساب آنلاین انجام دهید.
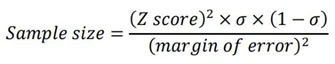
۷. انواع نمونه در آمار چیست؟
چهار نوع اصلی نمونه داده در آمار عبارتند از:
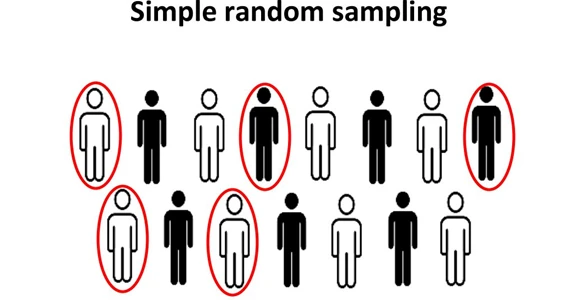
- نمونه تصادفی ساده: این روش شامل تقسیم تصادفی محض است. هر فرد احتمال یکسانی برای انتخاب شدن به عنوان بخشی از نمونه را دارد.
- نمونه خوشهای: این روش شامل تقسیم کل جمعیت به خوشههای مختلف است. خوشهها بر اساس پارامترهای شناختی جمعیت مانند جنس، سن و مکان در نمونه شناسایی و وارد میشوند.
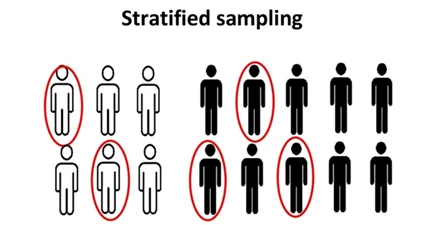
- نمونه طبقهای: این روش شامل تقسیم جمعیت به گروههای منحصربهفرد است به طوری که نماینده کل جمعیت باشند. در حین نمونهبرداری می توان این گروهها را سازماندهی کرد و سپس از هر گروه به طور جداگانه نمونهای بدست آورد.
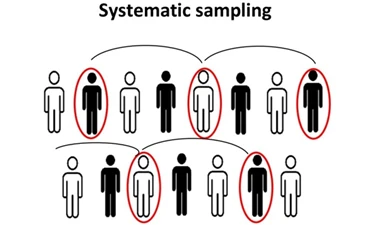
- نمونه سیستماتیک: این روش نمونهبرداری شامل انتخاب اعضای نمونه بر اساس یک نقطه شروع تصادفی اما با یک فاصله زمانی ثابت و دورهای به نام فاصله نمونهبرداری است. فاصله نمونهبرداری بر اساس جمعیت و با توجه به حجم نمونه مورد نظر محاسبه میشود. این نوع روش نمونهبرداری دارای محدوده از پیش تعریف شده است، از این رو کمترین زمان را نیاز دارد.
۸. فرض نرمال بودن چیست؟
فرض نرمال بودن مشخص میکند که اگر تعداد زیادی نمونه تصادفی مستقل از یک جامعه جمعآوری شود و مقدار موردنظر (مانند میانگین نمونه) محاسبه شود و سپس یک هیستوگرام برای تصویرسازی توزیع میانگین نمونه ایجاد شود، باید توزیع نرمال مشاهده شود. .
۹. چگونه یک توزیع نرمال را به توزیع نرمال استاندارد تبدیل میشود؟
توزیع نرمال استاندارد که توزیع z نیز نامیده می شود، توزیع نرمال ویژهای است که میانگین آن برابر با 0 و انحراف معیار برابر با 1 است. هر توزیع نرمال غیر استاندارد را می توان با تبدیل هر مقدار داده x به z-score استاندارد کرد. برای تبدیل نقطه x از یک توزیع نرمال به z-score از این فرمول استفاده میشود : z = (x-µ) / σ
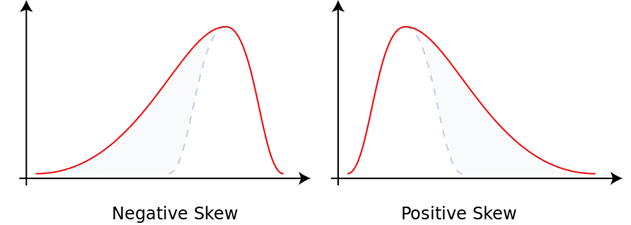
۱۰. توزیع با چولگی چپ و توزیع با چولگی راست چیست؟
چولگی راهی برای توصیف تقارن یک توزیع است.
- توزیع با چولگی چپ (منفی) توزیعی است که در آن دنباله سمت چپ بلندتر از دنباله راست باشد. برای این توزیع، mean < median < mode است.
- به طور مشابه، توزیع با چولگی راست (به صورت مثبت) توزیعی است که در آن دنباله راست بلندتر از سمت چپ باشد. برای این توزیع، mean > median > mode.
۱۱. برخی از خواص توزیع نرمال را بیان کنید.
برخی از ویژگی های توزیع نرمال به شرح زیر است:
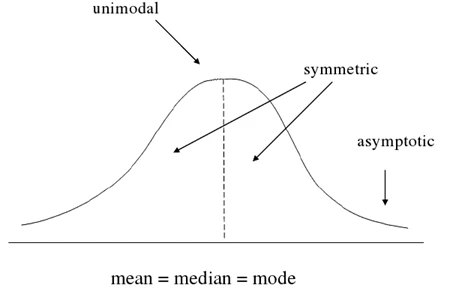
- تک وجهی: توزیع نرمال فقط یک پیک دارد. (یعنی یک مد)
- متقارن: یک توزیع نرمال در اطراف مرکز آن کاملاً متقارن است. (یعنی سمت راست مرکز تصویر آینهای سمت چپ است)
- میانگین، مد و میانه همه در مرکز قرار دارند (یعنی همه با هم برابرند)
- مجانب (Asymptotic): توزیعهای نرمال پیوسته و دارای دنبالههایی جانبی هستند. منحنی به محور x نزدیک میشود، اما هرگز لمس نمیشود.
۱۲. معیارهایی که توزیع های دوجمله ای باید داشته باشند چیست؟
4 معیاری که توزیعهای دوجملهای باید رعایت کنند عبارتند از:
- تعداد آزمایشات ثابت باشد.
- نتیجه هر آزمایش مستقل از دیگری باشد.
- هر آزمایش یکی از دو نتیجه ("موفقیت" یا "شکست") را نشان دهد.
- احتمال "موفقیت" p در تمام آزمایشات یکسان باشد.
۱۳.Outlier چیست؟
نقطه پرت یک نقطه داده است که به طور قابل توجهی با سایر نقاط داده در یک مجموعه داده متفاوت است. یک نقطه پرت ممکن است به دلیل تغییر در اندازهگیری باشد، یا ممکن است نشان دهنده یک خطای تجربی باشد.
نقاط پرت می توانند تا حد زیادی بر تحلیلهای آماری تأثیر بگذارند و نتایج آزمون فرض را منحرف کنند.
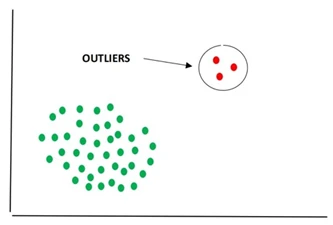
مهم است که به دقت نقاط پرت بالقوه در مجموعه داده شناسایی شده و برای نتایج دقیق با آنها مقابله شود.
۱۴. روشهایی را برای از شناسایی نقاط پرت در یک مجموعه داده ذکر کنید.
1- یک راه ساده برای بررسی نقاط داده خاص ، قبل از استفاده از روشهای پیچیدهتر، روش مرتبسازی است.
مقادیر موجود در دادهها را میتوان از کم به زیاد مرتب کرد و سپس مقادیر بسیار کم یا بسیار زیاد را مشخص کرد.
2- تصویرسازی (به عنوان مثال نمودار جعبهای) یک راه مفید برای مشاهده توزیع دادهها در یک نگاه و تشخیص نقاط پرت است. این نمودار اطلاعات آماری مانند مقادیر حداقل و حداکثر (محدوده)، میانه و محدوده بین چارکی را برای دادهها برجسته میکند. هنگام بررسی نمودار جعبهای، نقطه پرت یک نقطه داده خارج از دستههای نمودار جعبهای است.
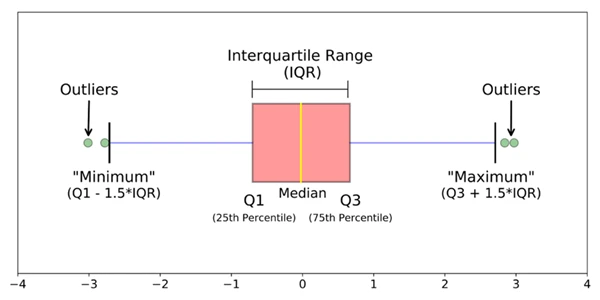
3- یک روش متداول دیگر، روش Interquartile range است. این روش در صورتی مفید است که مقادیر شدید کمی در مجموعه داده وجود داشته باشد، اما مطمئن نیستید که آیا هر یک از آنها ممکن است به عنوان مقادیر پرت محسوب شوند یا نه. برای استفاده از روش محدوده بین چارکی (IQR):
- داده ها را از کم به زیاد مرتب کنید.
- چارک اول (Q1)، میانه و چارک سوم (Q3) را مشخص کنید.
- IQR را به این صورت محاسبه کنید: IQR = Q3 – Q1
- حد بالا را محاسبه کنید= Q3 + (1.5 * IQR) و حد پایین . Q1 - (1.5 * IQR)
- از حد بالا و پایین برای مشخص کردن نقاط پرت (همه مقادیری که خارج از حدها قرار می گیرند) استفاده کنید.
4- راه دیگر برای شناسایی نقاط پرت استفاده از Z-score است. Z-score دقیقاً چند برابر انحراف معیار از مقدار میانگینی است که یک نقطه داده خاص دارد. برای محاسبه z-score از فرمول z = (x-µ) / σ استفاده میشود.
- اگر امتیاز z مثبت باشد، نقطه داده بیشتر از میانگین است.
- اگر امتیاز z منفی باشد، نقطه داده کمتر از میانگین است.
- اگر امتیاز z نزدیک به صفر باشد، نقطه داده نزدیک به میانگین است.
- اگر z-score بالاتر یا کمتر از 3 باشد (با فرض اینکه z-score = 3 به عنوان یک مقدار برش برای تعیین حد در نظر گرفته شود)، یک نقطه پرت است و نقطه داده غیر معمول در نظر گرفته میشود.
روشهای دیگر برای شناسایی نقاط پرت عبارتند از Isolation Forest و DBScan clustering.
۱۵. هنگام نمونهبرداری با چه نوع سوگیریهایی مواجه می شوید؟
سوگیری نمونهبرداری زمانی اتفاق میافتد که در طول یک تحقیق یا یک نظرسنجی، یک نمونه ، نماینده یک جامعه هدف نباشد. سه مورد اصلی که در هنگام نمونهبرداری اتفاق میافتند، عبارتند از:
- سوگیری انتخاب: شامل انتخاب دادههای فردی یا گروهی به روشی است که تصادفی نیست.
- سوگیری پنهان: این نوع سوگیری زمانی اتفاق میافتد که برخی از اعضای جمعیت بهطور کافی در نمونه نشان داده نمیشوند.
- سوگیری بقا: زمانی اتفاق میافتد که یک نمونه روی مشاهدات «بازمانده» یا موجود تمرکز میکند و آنهایی را که قبلا وجود نداشتهاند نادیده میگیرد که این میتواند منجر به نتیجهگیریهای اشتباه شود.
۱۶. منظور از inliner چیست؟
Inlier یک مقدار داده است که در توزیع مقادیر مشاهده شده قرار دارد اما یک خطا است. تشخیص دادههای درونی از مقادیر دادههای خوب، دشوار است، بنابراین، گاهی اوقات یافتن و تصحیح آنها دشوار است. یک مثال از یک inlier ممکن است مقداری باشد که در واحد اشتباه ثبت شده است.
۱۷. آزمون فرض چیست؟
آزمون فرض نوعی استنتاج آماری است که از دادههای نمونه برای نتیجه گیری در مورد دادههای جامعه استفاده می کند. قبل از انجام آزمایش، یک فرض در مورد پارامتر جمعیت در نظر گرفته میشود. این فرض، فرض صفر نامیده میشود و با H0 نشان داده میشود. سپس یک فرض مقابل (که با Ha مشخص می شود)، که نقطه مقابل منطقی فرض صفر است، تعریف میشود. در آزمون فرض از دادههای نمونه استفاده میشود تا تعیین شود که آیا H0 باید رد شود یا خیر. پذیرش فرض مقابل (Ha) به دنبال رد فرض صفر (H0) است.
۱۸. مقدار p در آزمون فرض چیست؟
مقادیر P در آزمون فرض برای کمک به تصمیمگیری در مورد رد یا عدم رد فرض استفاده میشود. هر چه مقدار p کوچکتر باشد، یعنی شواهدی قوی تری مبنی بر رد فرض صفر وجود دارد.
۱۹. چه زمانی باید از آزمون t در مقابل z-test استفاده کرد؟
- آزمون T معمولاً هنگام برخورد با مسائل با حجم نمونه محدود (n <30) استفاده میشود. اگر انحراف معیار جامعه مشخص باشد و حجم نمونه کمتر یا مساوی 30 و یا اگر انحراف معیار جامعه نامشخص باشد، از آزمون T استفاده میشود.
- آزمون Z، از سوی دیگر، یک نمونه را با یک جامعه تعریف شده مقایسه میکند و معمولاً برای مقابله با مسائل مربوط به نمونههای بزرگ (یعنی n> 30 ) استفاده میشود. به طور کلی، زمانی که انحراف معیار جامعه مشخص است و حجم نمونه بیش از 30 است، باید از آزمون Z استفاده شود.
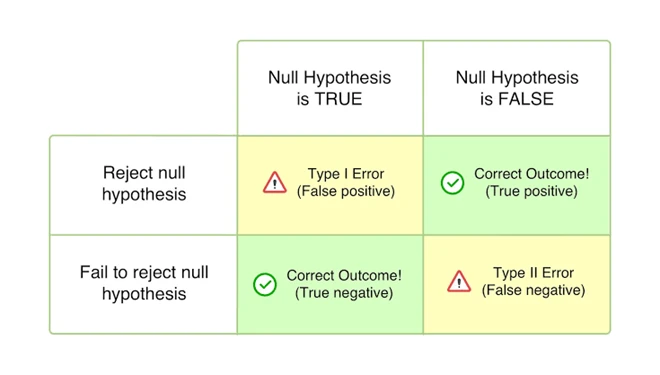
۲۰. تفاوت بین خطاهای نوع I با نوع II چیست؟
- خطای نوع I زمانی رخ میدهد که فرض صفر درست در جامعه، رد شود. این خطا، همچنین به عنوان مثبت کاذب شناخته میشود.
- خطای نوع دوم زمانی رخ میدهد که فرض صفر که در جامعه نادرست است، پذیرفته شود. این خطا، همچنین به عنوان منفی کاذب شناخته میشود.
۲۱. قضیه حد مرکزی چیست؟
قضیه حد مرکزی (CLT) بیان میکند که با توجه به حجم نمونه به اندازه کافی بزرگ از جمعیتی با سطح واریانس محدود، توزیع نمونه میانگین به طور نرمال توزیع میشود بدون در نظر گرفتن اینکه آیا جامعه به طور نرمال توزیع شده است یا خیر.
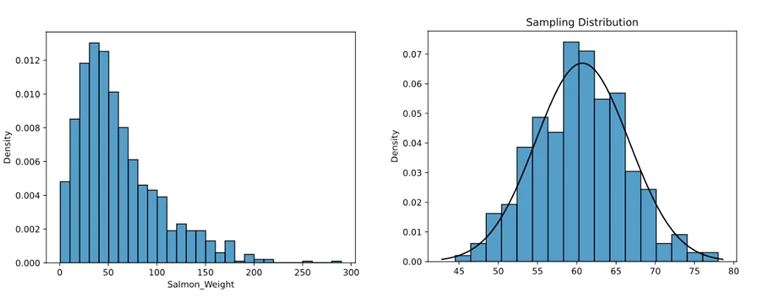
۲۲. برای برقراری قضیه حد مرکزی چه شرایط کلی باید رعایت شود؟
قضیه حد مرکزی بیان میکند که توزیع نمونه میانگین همیشه از توزیع نرمال در شرایط زیر پیروی می کند:
- حجم نمونه به اندازه کافی بزرگ است (یعنی حجم نمونه n≥ 30 است).
- نمونهها متغیرهای تصادفی مستقل و با توزیع یکسان هستند.
- توزیع جمعیت دارای یک واریانس مشخص است.
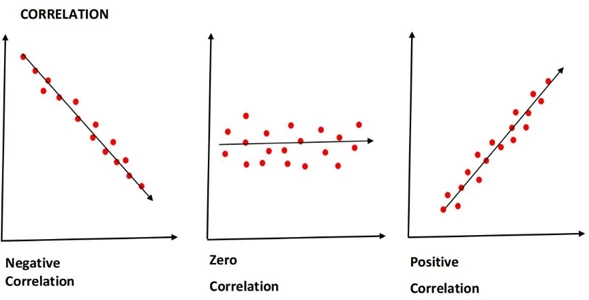
۲۳. همبستگی و کوواریانس در آمار چیست؟
- همبستگی (Correlation) نشان میدهد که دو متغیر چقدر با هم مرتبط هستند. مقدار همبستگی بین دو متغیر از 1- تا 1+ متغیر است. مقدار ۱- ، همبستگی منفی بالا را نشان میدهد، یعنی اگر مقدار یک متغیر افزایش یابد، مقدار متغیر دیگر کاهش مییابد. به طور مشابه، ۱+، به معنای همبستگی مثبت است، یعنی افزایش یک متغیر منجر به افزایش متغیر دیگر میشود. مقدار 0 به این معنی است که هیچ همبستگی وجود ندارد.
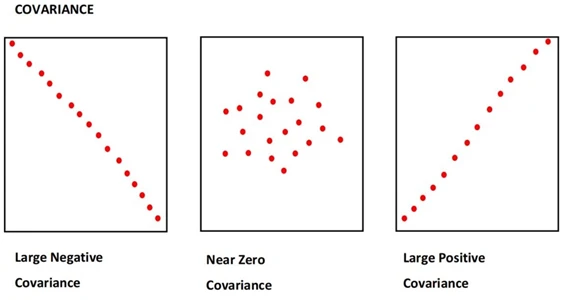
- از طرف دیگر کوواریانس معیاری است که میزان تغییر یک جفت متغیر تصادفی با یکدیگر را نشان میدهد. عدد بالاتر نشان دهنده وابستگی بالاتر است.
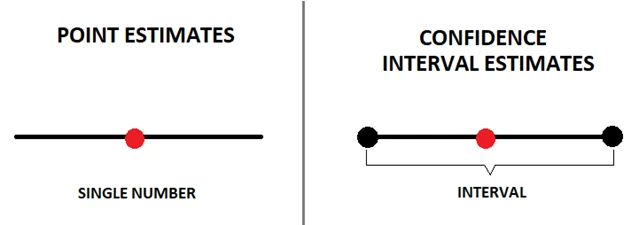
۲۴. تفاوت بین تخمین نقطهای و تخمین فاصله اطمینان چیست؟
- تخمین نقطهای یک مقدار واحد را به عنوان تخمین پارامتر جمعیت میدهد. به عنوان مثال، یک نمونه انحراف معیار، تخمین نقطهای از انحراف معیار یک جامعه است.
- تخمین فاصله اطمینان طیفی از مقادیر را میدهد که به احتمال زیاد حاوی پارامتر جمعیت است. این تخمین، رایجترین نوع تخمین بازهای است زیرا به ما میگوید چقدر احتمال دارد که این بازه حاوی پارامتر جمعیت باشد.
۲۵. کشش (Kurtosis) را تعریف کنید.
کشش میزان تفاوت مقادیر دنباله توزیع با مرکز توزیع است. نقاط پرت در یک توزیع داده با استفاده از کشش شناسایی میشوند. هر چه کشش بیشتر باشد، تعداد نقاط پرت در دادهها بیشتر است.
۲۶. قانون اعداد بزرگ در آمار چیست؟
طبق قانون اعداد بزرگ در آمار، افزایش تعداد آزمایشهای انجامشده باعث افزایش نسبی مثبت در میانگین نتایج و تبدیل آن به امید ریاضی میشود. به عنوان مثال، احتمال پرتاب یک سکه هموار و آمدن شیر زمانی که 100000 بار تکرار شود در مقایسه با 50 بار، به 0.5 نزدیکتر است.
۲۷. هدف از تست A/B چیست؟
آزمون A/B یک آزمون فرض آماری است. این آزمون، یک روش تحلیلی برای تصمیمگیری است که پارامترهای جمعیت را بر اساس آمار نمونه برآورد میکند. تست A/B یک روش فوق العاده برای کشف بهترین استراتژیهای تبلیغاتی و بازاریابی آنلاین برای کسب و کار است.
۲۸. از حساسیت (sensitivity) و ویژگی (specificity) چه چیزی مشخص میشود؟
- معیار حساسیت اندازه گیری نسبت موارد مثبت واقعی است که به عنوان مثبت (یا مثبت واقعی) پیش بینی شدهاند.
- ویژگی معیاری از نسبت موارد منفی واقعی است که به عنوان منفی (یا منفی واقعی) پیش بینی شدهاند.
محاسبه حساسیت و ویژگی بسیار ساده است.

۲۹. نمونهبرداری مجدد چیست و روشهای رایج نمونهبرداری مجدد کدامند؟
نمونه گیری مجدد شامل انتخاب موارد تصادفی شده با جایگزینی از نمونه دادههای اصلی است به گونهای که هر تعداد نمونه برداشته شده دارای چندین مورد مشابه با نمونه داده اصلی باشد.
دو روش رایج نمونهبرداری مجدد عبارتند از:
- بوت استرپینگ (Bootstrapping) و نمونه برداری عادی
- اعتبار سنجی متقابل (Cross Validation)
۳۰. رگرسیون خطی چیست؟
در آمار، رگرسیون خطی رویکردی برای مدلسازی رابطه بین یک یا چند متغیر پیشبینیکننده (X) و یک متغیر پیامد (y) است. اگر یک متغیر پیشبینی کننده وجود داشته باشد، به آن رگرسیون خطی ساده گفته میشود. اگر بیش از یک متغیر پیشبینی کننده وجود داشته باشد به آن رگرسیون خطی چندگانه گفته میشود.
۳۱. مفروضات مورد نیاز برای رگرسیون خطی چیست؟
رگرسیون خطی دارای چهار فرض کلیدی است:
- رابطه خطی: یک رابطه خطی بین X و میانگین Y وجود دارد.
- استقلال: مشاهدات مستقل از یکدیگر هستند.
- نرمال بودن: توزیع Y در امتداد X باید توزیع نرمال باشد.
- هم واریانسی (Homoscedasticity): تغییر در متغیر نتیجه یا پاسخ برای هر مقدار X یکسان است.
۳۲. تابع هزینه چیست؟
تابع هزینه یک پارامتر مهم است که عملکرد یک مدل یادگیری ماشین را برای یک مجموعه داده معین اندازهگیری می کند و مشخص میکند که چقدر مدل در تخمین رابطه بین پارامترهای ورودی و خروجی اشتباه عمل میکند.