
آشنایی با شاخصهای مرکزی و اهمیت آنها در تحلیل دادهها
در فصل اول با انواع دادهها و کاربردهای آنها آشنا شدیم. گام بعدی در این مسیر، محاسبه شاخصهای آماری است که در این بخش ابتدا به شاخصهای مرکزی خواهیم پرداخت. شاخصهای مرکزی، مانند میانگین و میانه، از جمله مفاهیمی هستند که احتمالاً با برخی از آنها آشنا هستید. این شاخصها به ما کمک میکنند تا رفتار دادهها را بهتر درک کنیم و تحلیلهای دقیقی داشته باشیم. اما چرا شاخصهای مرکزی اینقدر مهم و کاربردی هستند؟ ممکن است در محل کار از شما پرسیده شود که میانگین تعداد سفارشات فروش در هر ماه چقدر است، یا بخواهید بدانید هزینههای معمول یک خانه چقدر است. همچنین، در مواقعی نیاز داریم تا رایجترین رنگ مو یا متداولترین مدلها را بدانیم. اطلاعاتی مانند میانگین، رایجترین مقادیر، یا مقدار معمول، نمونههایی از نحوه استفاده از شاخصهای مرکزی در زندگی روزمره ما هستند. برای مثال، این مجموعه داده را در نظر بگیرید.
دادههای جرم و جنایت (Crime) | |||||
Total | Vehicle Crime | Theft | Robbery | Burglary | Borough |
14551 | 4668 | 6300 | 1265 | 2318 | Barking |
26152 | 9841 | 9875 | 1369 | 5067 | Barnet |
10743 | 4216 | 4500 | 444 | 1583 | Bexley |
23308 | 7739 | 10026 | 1650 | 3893 | Brent |
19498 | 6966 | 8635 | 844 | 3053 | Bromley |
... | ... | ... | ... | ... | ... |
این دادهها مربوط به جرم و جنایت در لندن است که در بخش قبلی نیز به آن اشاره کردیم. هر ردیف از دادهها به یک منطقه خاص در لندن مربوط میشود و هر منطقه با یک شناسه منحصر به فرد شمارهگذاری شده است. هر نوع جرم در این دادهها طی دو سال گذشته ثبت شده است. بهعنوان مثال، دادهای که نشاندهنده پنج هزار و شصت و هفت سرقت Burglary در منطقه Barnet است، بهوضوح این اطلاعات را نمایش میدهد.
تصویرسازی دادههای عددی با استفاده از هیستوگرام
یکی از روشهای رایج برای نمایش و تصویرسازی این دادههای عددی، تقسیمبندی دیتابیسها به محدودههای مشخص است. بهعنوان نمونه، نمودار هیستوگرام که تخلفات وسایل نقلیه را به هشت دسته مختلف تقسیم کرده، میتواند این اطلاعات را بهصورت بصری و واضح ارائه دهد:
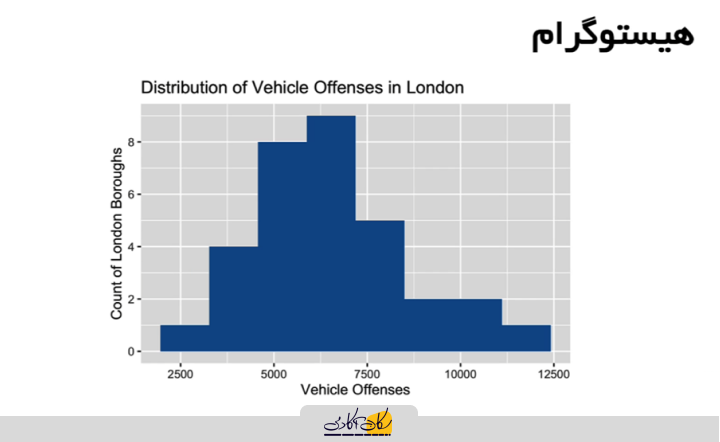
در نمودار مربوط به تخلفات وسایل نقلیه در لندن، پیک دادهها در قسمت خاصی قرار دارد که نشان میدهد نه منطقه از لندن در حدود شش هزار تا هفت هزار و سیصد تخلف وسیله نقلیه در دو سال گذشته ثبت کردهاند. این نوع نمودارها ابزارهای عالی برای خلاصهسازی دادههای عددی هستند.
محاسبه مرکز دادهها، میانگین و اهمیت آن در تحلیل آماری
آیا با استفاده از نمودار بالا میتوانیم مقدار متوسط تخلفات وسایل نقلیه را محاسبه کنیم؟ پاسخ به این سوال نیازمند محاسبه مقدار متوسط دادهها است که بهطور معمول از طریق تصویرسازی دادهها مانند هیستوگرام قابل دستیابی نیست. در عوض، برای این منظور میتوانیم از آمار توصیفی و محاسبه شاخصهای آماری بهره بگیریم. یکی از روشهای رایج برای محاسبه مرکز دادهها، استفاده از میانگین است. میانگین، بهعنوان سادهترین روش برای توصیف مرکز دادهها، بهراحتی با جمع کردن تمامی مقادیر و تقسیم آن بر تعداد کل دادهها محاسبه میشود. بهعنوان مثال، برای محاسبه میانگین تعداد سرقتها در هر منطقه از لندن، تمامی مقادیر جمع میشوند و سپس بر تعداد مناطق تقسیم میشوند. 
بهعنوان نمونه، میانگین محاسبه شده برای این دادهها، عدد 3462 خواهد بود. در جدول
شاخصهای مرکزی: میانگین | |
میانگین (Mean) | Type of Crime |
۳۳۵۸۰۶ | Burglary |
۱۴۵۰۸۵ | Robbery |
۱۰۶۴۲۲۱ | Theft |
۶۲۲۷۲۷ | Vehicle Offenses |
۴۷۶۷۱۶۲ | Overall |
میانگین برای هر نوع جرم بهصورت جداگانه محاسبه شده و مشاهده میشود که میانگین برای نوع خاصی از جرم برابر با هزار و ششصد و چهل و دو است که بیشترین مقدار میانگین را دارد.
آشنایی با میانه: شاخصی ساده برای تعیین مرکز دادهها
شاخص مرکزی دیگری که در آمار بهکار میرود، میانه است که محاسبه آن نیز بسیار ساده و سریع است. برای محاسبه میانه، کافی است دادهها را از کوچکترین تا بزرگترین مرتب کنیم. داده وسطی، که همان میانه است، نقطهای است که ۵۰ درصد از دادهها کمتر از آن و ۵۰ درصد بیشتر از آن هستند. 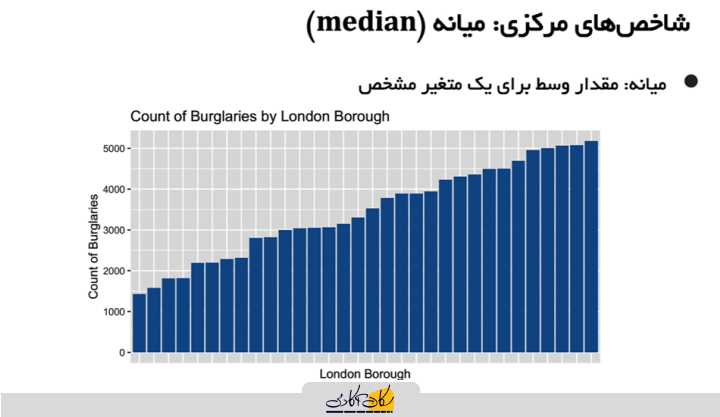
زمانی که تعداد دادهها زوج باشد، مانند مثال ما که تعداد مناطق برابر با ۳۲ است، باید دو مقدار وسطی را در نظر بگیریم، آنها را با هم جمع کرده و تقسیم بر دو کنیم تا میانه به دست آید. 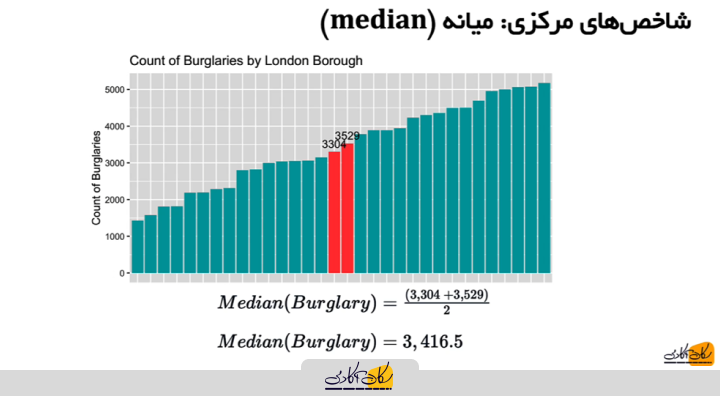
معمولاً مقداری که از این طریق به دست میآید، کمی کمتر از مقدار میانگین است.
مد: شناسایی رایجترین مقدار در مجموعه دادهها
شاخص مرکزی دیگری که میتوان به آن اشاره کرد، مد است. مد دادهها مقداری است که بیشترین فراوانی را دارد.
شاخصهای مرکزی: مد | |
Count | Type of Crime |
۱۱۰,۸۱۰ | Burglary |
۴۷,۸۷۷ | Robbery |
۳۵۰,۰۲۵ | Theft |
۲۰۵,۳۳۷ | Vehicle Offenses |
در این جدول، با شمارش وقوعات مشاهده میکنیم که Theft با مقدار 350 هزار بیشترین فراوانی را دارد و بهعنوان مد دادهها شناخته میشود.
انتخاب شاخص مناسب براساس نوع داده
زمانی که به دنبال تحلیلهای عمیقتر و بررسی الگوهای دادهها هستیم، هر یک از این شاخصها میتواند مزایای خاص خود را داشته باشد. برای مثال، انتخاب بهترین شاخص به نوع دادهها و هدف تحلیل بستگی دارد. سوالی که پیش میآید این است که کدام یک از این شاخصها باید در هر موقعیت استفاده شوند؟
انتخاب شاخص مناسب بستگی به نوع دادهها و موقعیت تحلیل دارد. بهعنوان مثال، در نظر بگیرید که یک نمودار هیستوگرام از تخلفات وسایل نقلیه داریم که شکل متقارنی دارد و یک پیک در وسط نمودار قرار دارد، بهطوری که دادهها از هر دو طرف به سمت پایین متمایل میشوند.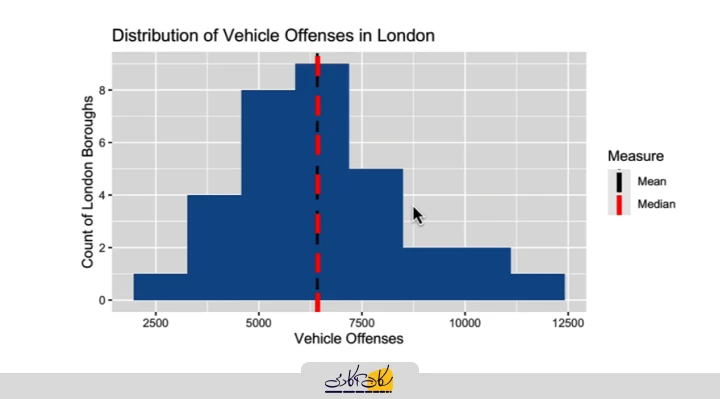
زمانی که دادهها متقارن هستند، هم میانگین و هم میانه بهخوبی کار میکنند و نتایج مشابهی را ارائه میدهند. همانطور که در این نمودار مشاهده میشود، میانگین و میانه تقریباً با هم همپوشانی دارند.
اما در مقابل، اگر نموداری داشته باشیم که دادهها به یک سمت انباشته شده و یک یا چند داده با مقادیر بسیار متفاوت از بقیه وجود داشته باشد، این نمودار دیگر متقارن نیست. 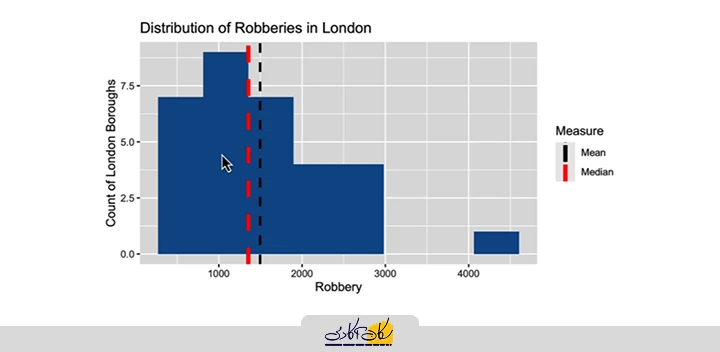
در این شرایط، میانه معمولاً بهتر عمل میکند. دلیل این امر این است که میانگین به مقادیر افراطی یا اکستریم ولیو حساس است. چون برای محاسبه میانگین باید تمامی مقادیر با هم جمع شوند، وجود یک داده با مقدار بسیار متفاوت میتواند تأثیر زیادی بر میانگین بگذارد. در حالی که میانه، به دلیل اینکه تنها به داده وسطی توجه دارد، تحت تأثیر دادههای افراطی قرار نمیگیرد.
زمانی که نمودار دادهها نامتقارن است، میانه معمولاً شاخص بهتری نسبت به میانگین است. بهعنوان مثال، 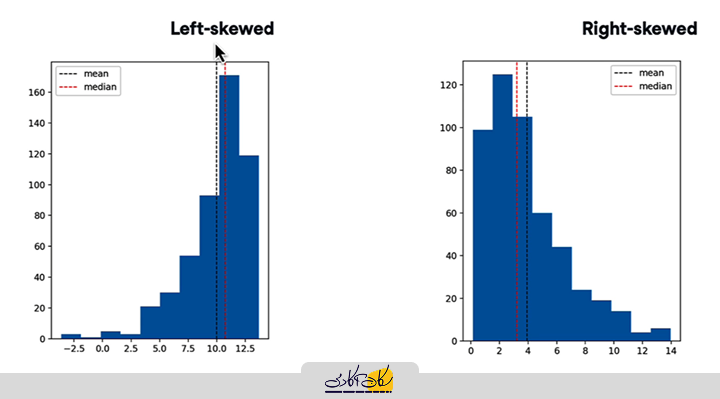
اگر یک نمودار داشته باشیم که دادهها به سمت راست انباشته شده و به سمت چپ کشیده شوند (با انحراف به سمت چپ)، میانگین تحت تأثیر این انحراف قرار میگیرد و مقدار آن کمتر از میانه خواهد بود. برعکس، اگر دادهها به سمت چپ انباشته شوند و به سمت راست کشیده شوند (با انحراف به سمت راست)، میانگین به سمت انحراف میرود و مقدار آن بیشتر از میانه خواهد بود. در هر دو حالت، که نمودارها نامتقارن هستند، میانه بهعنوان معیار مرکزی بهتر از میانگین عمل میکند.
شروع محاسبات آمار توصیفی
حال که این نکات را بررسی کردیم، بیایید وارد محاسبات آمار توصیفی شویم. برای این کار، نیاز داریم از کتابخانههای NumPy و Pandas استفاده کنیم. برای این کار یادداشت میکنیم:
import numpy as np
import pandas as pd
با استفاده از این کتابخانهها میتوانیم شاخصهای آماری مانند میانگین، میانه و دیگر ویژگیهای داده را محاسبه کنیم.
استفاده از نمودار استرم
مجموعه دادهها شامل اطلاعات مختلفی از پستانداران است، از جمله ساعات خواب آنها. یکی از روشهای عالی برای خلاصهسازی بصری دادههای عددی، استفاده از نمودارهای استرم است. در این نمودار، ستونها نمایانگر دادهها هستند و با تنظیم تعداد بیتی، مثلاً برابر با بیست، میتوانیم نموداری بسازیم که محور X ساعات خواب را نشان دهد و محور Y تعداد پستانداران را که در آن بازه زمانی خاص قرار دارند. بهعنوان مثال، در این نمودار مشاهده میکنیم که تعداد نه پستاندار در مجموعه دادههای ما وجود دارند که ساعات خواب آنها بین نه تا ده ساعت است.
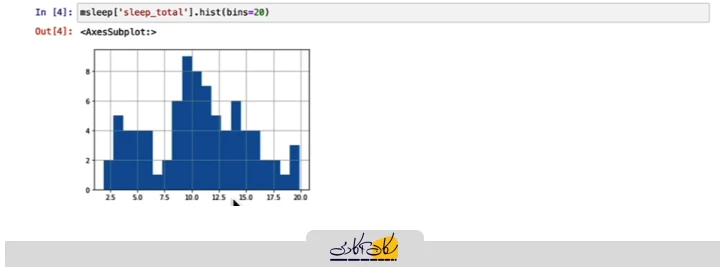
این نمودار بهعنوان یک ابزار خوب برای خلاصه کردن دادهها استفاده میشود، اما اگر بخواهیم مقدار مرکزی دادهها را مشخص کنیم، این نمودار بهتنهایی کافی نخواهد بود. برای پاسخ دادن به سوالاتی مانند "مقدار متوسط ساعات خواب پستانداران چقدر است؟" باید از شاخصهای آماری استفاده کنیم. بهطور خاص، از سه شاخص مرکزی اصلی میانگین، میانه و مد برای محاسبه و تحلیل مقدار متوسط دادهها استفاده میکنیم. برای محاسبه میانگین، میتوانیم از کتابخانه NumPy در پایتون بهره بگیریم.
محاسبه میانگین
برای محاسبه میانگین، از تابع میانگین استفاده میکنیم و ستون مورد نظر خود را به آن ارسال میکنیم. بهعنوان مثال، پس از فراخوانی این تابع، میانگین محاسبه شده برای ساعات خواب پستانداران برابر با ۱۰.۴۶ ساعت است. به این معنی که بهطور متوسط، پستانداران این مقدار ساعت را میخوابند.
np.mean(msleep['sleep_total'])
که خروجی آن برابر است با:
10.46145783132527
محاسبه میانه
شاخص مرکزی دیگری که به آن اشاره کردیم، میانه است. میانه دادهای است که در وسط مجموعه دادهها قرار دارد. برای محاسبه میانه، ابتدا باید دادهها را مرتب کنیم و سپس داده وسطی را انتخاب کنیم. برای مرتب کردن دادهها میتوانیم از تابع ()sort استفاده کنیم. ابتدا ستون دادهها را انتخاب میکنیم و سپس این تابع را روی دادهها اجرا میکنیم تا دادهها به ترتیب صعودی مرتب شوند.
در این مجموعه داده، که شامل ۸۳ مقدار است، دادهای که در موقعیت ۴۲ قرار دارد، میانه را مشخص میکند. به عبارت دیگر، میانه دادهها برابر با مقدار موجود در موقعیت چهل و دوم است که در این مثال برابر با ۱۰ است.
msleep['sleep_total'].sort_values().iloc[42]
که خروجی آن برابر است با:
10.3
میتوانیم خیلی راحت از تابع ()median استفاده کنیم. این تابع به راحتی فراخوانی میشود و تنها کافی است ستون مورد نظر را به آن ارسال کنیم.
np.median(msleep['sleep_total'])
وخروجی آن برابر است با:
10.3
محاسبه مد
آخرین شاخصی که در مورد آن صحبت کردیم، مد است. مد دادهای است که بیشترین فراوانی را دارد. برای پیدا کردن داده با بیشترین فراوانی، باید تعداد تکرار هر داده را شمارش کنیم. برای این کار میتوانیم از تابع ()value_counts استفاده کنیم که فراوانی تکرار هر مقدار را نشان میدهد. بهعنوان مثال، در مجموعه دادههای ما، ۱۲.۵ ساعت بیشترین تکرار را دارد و چهار پستاندار در این مدت زمان میخوابند.
In [9]: msleep['sleep_total'].value_counts()
Out[9]:
12.5 4
10.1 3
9.4 2
9.8 2
10.9 2
..
19.4 1
17.0 1
14.3 1
19.9 1
5.2 1
Name: sleep_total, Length: 64, dtype: int64
علاوه بر استفاده از این تابع، میتوانیم از تابع ()mode موجود در کتابخانه statisties نیز بهره ببریم. برای استفاده از این تابع، ابتدا باید statisties را وارد (import) کنیم. سپس تابع ()mode را فراخوانی کرده و ستون مورد نظر را به آن ارسال میکنیم. بهعنوان مثال، برای ستون مربوط به ساعات خواب پستانداران، تابع ()mode مقدار ۱۲.۵ ساعت را بهعنوان خروجی به ما میدهد.
In [10]: import statistics as stats
In [11]: stats.mode(msleep['sleep_total'])
Out[11]: 12.5
اگر به یاد داشته باشید، همانطور که اشاره کردیم، شاخصهایی مانند مد برای دادههای کیفی بسیار مفید هستند، چرا که این دادهها ماهیت عددی ندارند و این شاخصها برای آنها کارایی بالاتری دارند.
برای محاسبه مد در مورد رژیم غذایی پستانداران، میتوانیم از تابع ()mode استفاده کنیم تا دادهای که بیشترین فراوانی را دارد شناسایی شود. بهعنوان مثال، برای شناسایی رژیم غذایی پستانداران، اگر ستون مربوط به رژیم غذایی (که ممکن است شامل مقادیری مانند گوشتخوار، گیاهخوار، و همهچیزخوار باشد) را به این تابع ارسال کنیم، خروجی به ما نشان میدهد که کدام یک از این مقادیر بیشترین تکرار را دارد. برای مثال، اگر پستانداران گیاهخوار بیشترین فراوانی را دارند، نتیجه نشان خواهد داد که این گروه بیشترین فراوانی را دارند.
In [12]: msleep['vore'].value_counts()
Out[12]:
herbi 32
omni 21
carni 19
insecti 4
Name: vore, dtype: int64
مقایسهی توابع ()value_counts و ()mode برای محاسبهی فراوانیها
برای محاسبه فراوانیها، میتوانیم از تابع ()value_counts استفاده کنیم تا ببینیم کدام داده بیشتر تکرار شده است. اما به جای این تابع، میتوانیم از تابع ()mode نیز بهره بگیریم که همان خروجی را به ما میدهد. این تابع بسیار ساده است و میتواند بهطور خودکار دادههای با بیشترین فراوانی را شناسایی کند.
کتابخانه numpy علاوه بر تابع ()mode، توابعی برای محاسبه میانگین و میانه نیز دارد. دلیل اینکه من از numpy برای محاسبه میانگین و میانه استفاده میکنم این است که این کتابخانه برای محاسبات عددی بسیار سریع و کارا است.
در مجموعه دادهی حیوانات، رژیم غذایی به چهار دسته تقسیم میشود. حالا فرض کنید که میخواهیم حیوانات حشرهخوار را از دادهها جدا کنیم. برای این کار، میتوانیم از کد زیر استفاده کنیم که حیواناتی که رژیم غذایی آنها حشرهخوار است را فیلتر میکند: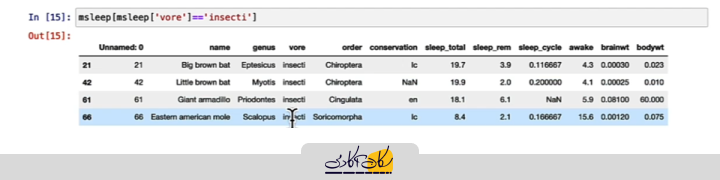
در این کد، مجموعه دادهها فیلتر میشود و فقط حیوانات حشرهخوار باقی میمانند. پس از فیلتر کردن، ممکن است بخواهیم مقدار مرکزی این دادهها را محاسبه کنیم. برای این منظور، میتوانیم از توابع میانگین و میانه استفاده کنیم که هر دو میتوانند برای دادههای ما محاسبه شوند. در این مثال، برای دادههای حشرهخوار، مقدار میانگین ۱۶.۵۲ ساعت و مقدار میانه ۱۸.۹ ساعت است.
msleep[msleep['vore'] == 'insecti']['sleep_total'].agg([np.mean, np.median])
حالا فرض کنید که یک دادهی پرت به مجموعه دادهها اضافه کنیم. برای مثال، فرض کنید که دادهای با ساعت خواب ۰ ساعت را به عنوان یک حیوان حشرهخوار اضافه میکنیم. این داده در موقعیت ۸۴ام قرار میگیرد و باید ساعت خواب آن به صفر تنظیم شود. برای انجام این کار، میتوانیم کدی مشابه زیر بنویسیم:
data.loc[83, 'sleep_hours'] = 0
در این کد، دادهی جدید به مجموعه اضافه میشود و مقدار آن صفر قرار میگیرد. پس از این تغییر، وقتی دوباره میانگین و میانه را محاسبه کنیم، مشاهده میکنیم که مقدار میانگین تغییر زیادی میکند و به ۳ ساعت کاهش مییابد، در حالی که مقدار میانه فقط ۸ دهم ساعت تغییر کرده است.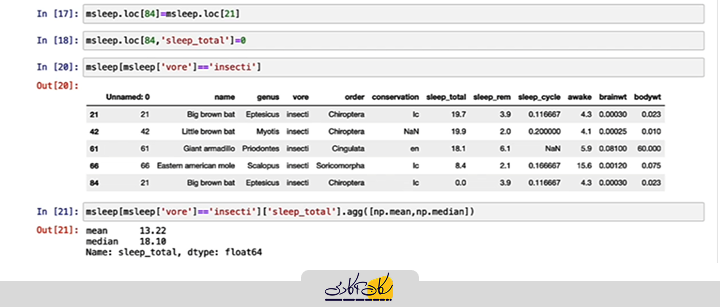
این تغییرات نشان میدهد که میانه نسبت به دادههای پرت مقاومتر است و تاثیر کمتری از این دادههای غیرمعمول میگیرد. این نکته اهمیت زیادی دارد، بهخصوص زمانی که با دادههایی مواجه هستیم که ممکن است شامل مقادیر عجیب و غیرمعمول باشند.
در این بخش، اصول محاسبه شاخصهای مرکزی مانند میانگین و میانه بررسی شد و نشان داده شد که چگونه میتوان از این شاخصها برای تحلیل دادهها استفاده کرد. اگر بخواهید بیشتر تمرین کنید، در بخش بعدی تمرینهای بیشتری برای شما آماده کردهایم.