
لینوکس ابزارهای متنوعی برای کار با فایلها در اختیار کاربرانش قرار میدهد که از جمله ی مهمترین آنها میتوان به موارد زیر اشاره کرد:
- sort
- uniq
- paste
- join
- split
ابزار sort
sort را میتوان به منظور مرتب سازی خطوط یک فایل متنی خواه از جدید به قدیم و خواه از قدیم به جدید مورد استفاده قرار داد. علاوه بر این، با استفاده از این دستور میتوان بر اساس فیلدهای یک فایل نیز محتویات را مرتب سازی کرد.
به منظور درک بهتر عملکرد دستور sort، ابتدا یک فایل تحت عنوان tmp ساخته و چند خط محتوا داخل آن وارد می سازیم. به عنوان خروجی این فایل داریم:
line one
line two
line three
line four
line five
line six
line sevenحال دستور زیر را روی این فایل اعمال میکنیم:
sort tmpبه عنوان خروجی دستور فوق داریم:
line five
line four
line one
line seven
line six
line three
line two
همانطور که مشاهده میشود، محتویات داخل این فایل بر اساس حروف الفبای انگلیسی از A تا Z مرتب شدهاند؛ اگر هم بخواهیم که ترتیب خطوط از Z به A باشد هم می بایست دستور زیر را اجرا کنیم:
sort -r tmpبه عنوان خروجی دستور فوق داریم:
line two
line three
line six
line seven
line one
line four
line five
میبینیم که آپشن r- که از واژه ی Reverse به معنی «برعکس» گرفته شده است کلیه محتویات فایل را از Z به A مرتب میسازد.
| نکته |
در صورتی هم که بخواهیم ۲ فایل مجزا را ابتدا با یکدیگر ادغام نموده سپس آنها را مرتب سازی کنیم، میتوانیم از دستور cat file1 file2 | sort استفاده نماییم. |
دستور uniq
این دستور برای حذف محتویات تکراری داخل یک فایل مورد استفاده قرار میگیرد البته این در حالی است که خطوط تکراری حتماً می بایست پشت سر هم قرار گرفته باشند.
برای روشنتر شدن کاربرد ابزار uniq در لینوکس، محتویات فایل tmp که پیش از این ساختیم را به صورت زیر آپدیت میکنیم:
line one
line two
line one
line one
همانطور که مشاهده میشود، اگرچه که خطوط اول، سوم و چهارم تکراری هستند، اما ابزار uniq صرفاً خطوط سوم و چهارم را تکراری تلقی میکند و از همین روی خط چهارم را حذف میکند. برای این کار، دستور uniq tmp را در کامند لاین وارد میکنیم؛ به عنوان خروجی دستور فوق داریم:
line one
line two
line one
با توجه به این ویژگی دستور uniq، بهتر آن است که ابتدا با استفاده از دستور sort خطوط را مرتب سازی کنیم تا خطوط تکراری پشت سر هم قرار گیرند سپس دستور uniq را با استفاده از علامت | اعمال کنیم. در همین راستا، ابتدا دستور sort tmp | uniq را در کامند لاین وارد می سازیم. به عنوان خروجی این دستور داریم:
line one
line two
به عنوان راهکاری جایگزین، میتوان با در نظر گرفتن آپشن u- در ابزار sort هر دو گام را در یک مرحله انجام داد:
sort -u tmpبه عنوان خروجی دستور فوق داریم:
line one
line two
میبینیم که هر دو دستور کار واحدی را انجام میدهند. در صورتی هم که بخواهیم تعداد خطوط تکراری را شمارش کنیم، میتوانیم از آپشن c- پس از کامند uniq به صورت زیر استفاده کنیم:
uniq -c tmpگاهی اوقات برایمان پیش میآید که تمایل داریم خروجی دستور uniq را در فایل دیگری ذخیره سازیم؛ در چنین مواقعی ۲ راهکار پیش رو داریم:
sort file1 file2 | uniq > file3و یا
sort -u file1 file2 > file3در کامند اول ابتدا فایلهای file1 و file2 را با یکدیگر ادغام و مرتب نموده سپس دستور uniq را روی آن اعمال نموده و در نهایت خروجی را در فایل جدیدی تحت عنوان file3 ذخیره میسازیم. کامند دوم هم دقیقاً همین کار را انجام میدهد اما به جای اعمال دستور uniq از آپشن u- کامند sort استفاده میکند.
آشنایی با دستور paste
فرض کنیم فایلی داریم که حاوی نام و نام خانوادگی پرسنل یک شرکت است و فایل دیگری حاوی شماره تلفن و شماره ی پرسنلی ایشان است؛ حال میخواهیم فایلی داشته باشیم که دربرگیرنده ی نام، نام خانوادگی، شماره تلفن و شماره ی پرسنلی باشد که در چنین شرایطی دستور paste به سادگی این کار را برایمان انجام خواهد داد.

همانطور که در تصویر فوق مشخص است، برای مجزا سازی بخشهای مختلف اطلاعات پرسنل از Space (اسپیس یا فضای خالی) استفاده شده است و ابزار paste هم از همین فضای خالی برای تشخیص ستونهای مختلف استفاده خواهد کرد. برای روشنتر شدن کاربر دستور paste، ابتدا یک فایل تحت عنوان file1 با محتویات زیر می سازیم:
Steve Jobs
Bill Gates
Elon Musk
سپس فایل دیگری تحت عنوان file2 با محتویات زیر میسازیم:
Apple
Microsoft
SpaceX
حال دستور paste file1 file2 را در کامند لاین وارد میکنیم؛ به عنوان خروجی این دستور داریم:
Steve Jobs Apple
Bill Gates Microsoft
Elon Musk SpaceX
میبینیم که خط اول از فایل file1 با خط اول از فایل file2 تطبیق داده شده الی آخر؛ حال اگر بخواهیم در حین ادغام ۲ فایل از «جدا کننده یی» استفاده کنیم، میتوانیم دستور زیر را اجرا نماییم:
paste -d ':' file1 file2
به عنوان خروجی دستور فوق داریم:
Steve Jobs:Apple
Bill Gates:Microsoft
Elon Musk:SpaceX
آشنایی با دستور join
فرض کنیم فایلی داریم تحت عنوان file1 که حاوی نام افراد به علاوه ی شماره تلفن ایشان است؛ فایل دیگری نیز داریم تحت عنوان file2 که این فایل هم حاوی شماره تلفن افراد است به علاوه ی شهر محل سکونت ایشان.
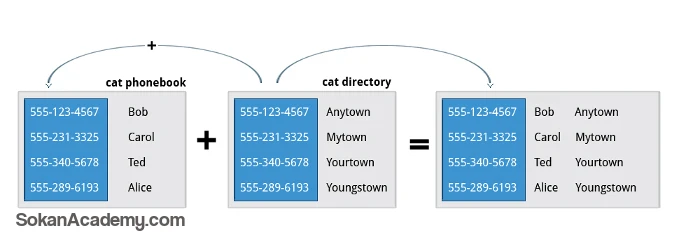
چیزی که در این ۲ فایل تکراری است، شماره تلفن افراد است؛ حال ممکن است شرایطی برایمان پیش بیاید که نیاز داشته باشیم هر ۲ فایل را با یکدیگر ادغام نموده اما ستونهای تکراری حذف شوند که در چنین شرایطی می بایست از ابزاری تحت عنوان join استفاده نمود (دستور join نسخه ی پیشرفته یی از دستور paste است.)
عملکرد دستور join به این شکل است که ابتدا هر ۲ فایل را مورد بررسی قرار میدهد تا ببیند که آیا دارای ستون مشترکی هستند یا خیر؛ سپس هر ۲ فایل را بر اساس ستونی که در هر دو فایل وجود دارد به یکدیگر الحاق میکند. برای روشنتر شدن این مسئله، ابتدا فایلی میسازیم تحت عنوان file1 که دارای محتویات زیر است:
07 Mohammad
14 Behzad
112 Siamak
سپس فایلی میسازیم تحت عنوان file2 که دارای محتویات زیر است:
07 Tehran
14 Arak
112 Ahvaz
همانطور که میبینیم، فیلد شناسه در هر دو فایل یکسان است. حال دستور join file1 file2 را در ترمینال وارد می سازیم:
07 Mohammad Tehran
14 Behzad Arak
112 Siamak Ahvaz
میبینم که هر ۲ فایل با یکدیگر ادغام شدند بدون آن که فیلد شناسه ۲ بار تکرار شود.
آشنایی با دستور split
ابزار split همانطور که از نامش پیدا است -split به معنای مجزا ساختن است- برای تقسیمبندی یک فایل به بخشهای مساوی به منظور سهولت بیشتر کار کردن با آن فایل مورد استفاده قرار میگیرد و معمولاً از این دستور برای کار با فایلهای خیلی حجیم استفاده میشود.
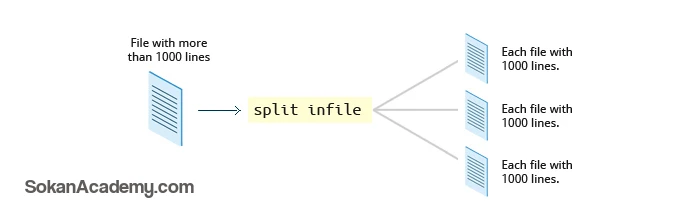
به صورت پیشفرض، کامند split یک فایل حجیم را به بخشهای ۱۰۰۰ خطی تقسیمبندی میکند و این در حالی است که فایل اورجینال یا اصلی بدون تغییر باقی خواهد ماند اما فایلهایی ۱۰۰۰ خطی با همان نام + یک پیشوند ساخته خواهند شد که این پیشوند به صورت پیشفرض حرف x است.
فرض کنیم فایلی داریم تحت عنوان american-persian که یک فایل دیکشنری است که چندین هزار خط محتویات دارد. با استفاده از دستور زیر، قادر خواهیم بود تا این فایل را به بخشهای ۱۰۰۰ خطی مجزا از یکدیگر در قالب فایلهایی تحت عنوان dictionay تقسیمبندی خواهد کرد:
$ split american-english dictionaryآشنایی با دستور wc
wc برگرفته از کلمات Word Count به معنی «تعداد کلمه» است و کاری که این دستور انجام میدهد این است که به صورت پیشفرض تعداد خطوط، لغات و کاراکترهای قرار گرفته در یک فایل متنی را در معرض دیدمان قرار میدهد. در صورتی که بخواهیم رفتار پیشفرض wc را تغییر دهیم، میتوانیم از آپشن l- برای نمایش فقط تعداد خطوط، از آپشن m- برای نمایش فقط تعداد کاراکترها و از آپشن w- فقط برای تعداد کلمات استفاده کنیم.
برای روشنتر شدن کاربرد دستور wc ابتدا فایلی تحت عنوان tmp ساخته سپس محتوایی دلخواه داخل آن میریزیم:
This is some dummy text.حال دستور wc tmp را اجرا میکنیم؛ به عنوان خروجی این دستور داریم:
1 5 25 tmpبرای آن که صرفاً تعداد کلمات را نشان دهیم، دستور wc -w tmp را در ترمینال وارد میکنیم؛ به عنوان خروجی این دستور داریم:
5 tmp