اگر تازه به دنیای توسعهٔ نرمافزار به خصوص طراحی سایت قدم گذاشته باشید، احتمالاً درک مفاهیم پایهای معماری وب برای شما کمی دشوار باشد. در همین راستا، در این مقاله قصد داریم تا گام به گام و در عین حال با تعاریفی ساده و قابلفهم Web Architecture یا به عبارتی معماری یک وبسایت را تشریح کنیم به طوری که درک آن برای علاقمندان به این حوزه تسهیل گردد.
به منظور درک بهتر این موضوع، پیش از پرداختن به جزئیات کامپوننتهای موجود در معماری یک سایت، سناریویی فرضی را مد نظر قرار میدهیم بدین صورت که فرض کنید کاربری کلیدواژگان «آموزش اصول برنامهنویسی» را در گوگل جستجو میکند که یکی از لینکهای نتیجۀ جستجو متعلق به وبسایت سکان آکادمی خواهد بود؛ در ادامه، کاربر روی یکی از لینکهای پیشنهادی گوگل کلیک میکند و مرورگر وی به لندینگ پیج مد نظر در سایت سکان آکادمی هدایت میشود. مسلماً این ظاهر ماجرا است و در پشتپرده اتفاقات مختلفی میافتد که از دید کاربران پنهان میباشد و این همان چیزی است که در ادامه قصد داریم به تشریح آن بپردازیم.
در حقیقت، پس از اینکه کاربر روی یکی از لینکهای نتیجۀ جستجوی گوگل کلیک میکند، در مرحلۀ اول مرورگرِ کاربر ریکوئستی را به یک DNS Server ارسال میکند که این سرور راهی را برای اتصال به وبسایت یافته و سپس ریکوئست خود را به وبسایت مذکور ارسال میکند. در ادامه، ریکوئست کاربر به یک اصطلاحاً Load Balancer فرستاده میشود و این برنامه به صورت تصادفی یکی از چند وبسرور در نظر گرفته شده را انتخاب خواهد کرد که به منظور هندل کردن ریکوئستهای همزمان مورد استفاده قرار میگیرند.
در ادامه وبسرور انتخابی ریکوئست کاربر را بررسی کرده و اطلاعات مد نظر او را در Caching Service جستجو میکند که در صورت وجود چنین دیتایی در کَش، دیگر به سراغ دیتابیس نخواهد رفت (در برخی مواقع نیز ممکن است که پاسخ به دیتای ریکوئستی از سمت کاربر نیازمند انجام یک به اصطلاح Job خاص باشد که در چنین شرایطی یک Job در Job Queue قرار میگیرد و در ادامه سرویسهای مرتبط آن را به صورت آسِنکرون یا غیرهمزمان پردازش کرده و دیتابیس خود را متناسب با نتایج حاصلشده آپدیت میکنند.)
در ادامهٔ راه، یا یک کوئری به طور مستقیم برای دیتابیس ارسال میشود تا محتوای مذکور فِچ (فراخوانی) شده و در اختیار کاربر قرار گیرد و یا گاهی هم وبسرور در تلاش برای پیدا کردن نتایجی مشابه با عبارت جستجوشده توسط کاربر، از قابلیتی تحت عنوان Full Text Search در سیستم مدیریت دیتابیس (DBMS) استفاده میکند که در این مرحله عنوان عبارت مورد جستجوی کاربر به عنوان ورودی داده میشود.
سپس با فراخوانی یک Event (رویداد) که منجر به نمایش یک پیچ میگردد، دیتای حاصل از رصد کردن رفتار کاربران را در صورت نیاز در سرویس آنالیتیکس خود ذخیره ساخته که در این مرحله تحلیلگران و وبمسترها میتوانند دیتای ذخیرهشده را به منظور دستیابی به پاسخ یکسری سؤال در مورد کسبوکار و یا ارتقای کیفیت محتوای وبسایت تحلیل کنند (مثلاً اینکه پربازدیدترین صفحات کدامیک بودهاند.)
در نهایت، سرور ویوی وبسایت را در قالب یک یا چند فایل HTML رِندر کرده و برای مرورگر کاربر ارسال میکند که این صفحه مسلماً حاوی یکسری کدهای CSS و JS است که روی یک CDN در دسترس هستند و از همین روی مرورگر برای بازیابی محتوای وبسایت بایستی به شبکهٔ توزیع محتوای مذکور متصل شود که در نهایت، مرورگر وبپیج مد نظر را برای کاربر نمایش خواهد داد.
آنچه ذکر شد، خلاصهای از یک یک مدل ذهنی به منظور درک بهتر معماری وب بود اما به منظور درک بیشتر سازوکار معماری یک وب اپلیکیشن، در ادامه با جزئیات هر یک از کامپوننتهای فوقالذکر بیشتر آشنا خواهید شد که این کامپوننتها در ارتباط تنگاتنگی با یکدیگر، معماری یک وبسایت یا بهتر بگوییم وب اپلیکیشن را تشکیل میدهند.
DNS (مرحلهٔ ۱)
Domain Name Server یا به اختصار DNS، یکی از اصلیترین کامپوننتها در معماری وب به شمار میرود. در ابتدا و برای اینکه سیستم کاربر مسیر ریکوئست را به سمت سرور مربوطه بیابد، DNS امکان جستجویی مبتنی بر Key/Value را از یک نام دامنه همچون sokanacademy.com به یک آدرس آیپی همچون 185.143.232.34 متناظر آن دامنه فراهم میکند. تفاوت بین نام دامنه و آدرس آیپی را میتوان به تفاوت بین نام یک فرد و شمارۀ تلفن او تشبیه کرد. به طور کلی، تلاش DNS برای تبدیل نام دامنه به یک آدرس آیپی به مانند این است که شما دفترچه تلفنی را برای یافتن شمارهٔ تلفن یک فرد جستجو کنید؛ به عبارت دیگر، DNS را میتوان به عنوان دفترچۀ تلفن اینترنت نام برد!
Load Balancer (مرحلهٔ ۲)
پیش از پرداختن به جزئیات مفهوم Load Balancing، ابتدا نیاز داریم تا یک گام به عقب بازگشته و در مورد مقیاسپذیری اپلیکیشن در راستای افقی و عمودی بحث کنیم. مقیاسپذیری افقی بدین معنی است که دولوپرها با اضافه کردن اپلیکیشنها و دیوایسهای بیشتر به ریسورسهای اپلیکیشن خود، اندازۀ آن را بزرگتر میکنند و این در حالی است که مقیاسپذیری عمودی بدین معنی است که دولوپرها با افزودن منابع سختافزاری همچون رَم، سیپییو یا موارد دیگر به سرویس هاستینگ اپلیکیشن موجود، قدرت آن را افزایش دهند.
در توسعۀ وب تقریباً همه دولوپرها برای دستیابی به مقیاسپذیری افقی اپلیکیشن خود تلاش میکنند چرا که مقیاسپذیری افقی موجب میشود تا بخشهای مختلف بکاند اپلیکیشن (از جمله وبسرور، دیتابیس، سرویسهای مختلف و غیره) اتصال و وابستگی زیادی به دیگر بخشها نداشته باشند و دولوپرها میتوانند به سادگی با تغییر بخشهای مختلف، عملکرد اپلیکیشن خود را بهبود بخشند. برای مثال شرایطی را تصور کنید که سرورها به صورت رَندوم هنگ میکنند، سرعت شبکه برای ارسال ریکوئست یا دریافت ریسپانس از سرور کاهش مییابد و یا تمام دیتاسنترها به حالت آفلاین میروند که در چنین شرایطی پیادهسازی بخشهای مختلف اپلیکیشن روی بیش از یک سرور این امکان را در اختیار دولوپرها قرار میدهد تا بتوانند مشکلات به وجود آمده را مدیریت کرده و اپلیکیشن خود را همچنان اصطلاحاً Up نگاه دارند؛ به عبارت دیگر، Fault Tolerant یا تحمل خطای اپلیکیشن بالاتر میرود.
حال با دانستن این توضیحات، به بررسی جزئیات Load Balancer میپردازیم که به منزلهٔ برنامهای است که امکان مقیاسپذیری افقی را برای وباپلیکیشنها فراهم میکند به طوری که ریکوئستهای ورودی از سمت کاربر را به یکی از چندین سرور در نظر گرفتهشده برای وب اپلیکیشن هدایت کرده و ریسپانس متناظر آن را از سرور به سمت کلاینت (کاربر) ارسال میکنند. به طور کلی، هر یک از لود بالانسِرها به روشی یکسان ریکوئستها را پردازش میکند و مسئلۀ مهم در اینجا توزیع ریکوئستها در میان مجموعهای از سرورها است بدین صورت که هیچیک از آنها دچار اصطلاحاً Overload نگردد.
Web Application Servers (مرحلهٔ ۳)
نرمافزارهای اجراکنندهٔ وب اپلیکیشنها به سادگی قابلتوصیف هستند بدین صورت که در واقع این وبسرورها وظیفۀ اجرای منطق اصلی اپلیکیشن را بر عهده دارند که ریکوئستهای کاربران را هندل کرده و فایلهای HTML مد نظر را به مرورگر کاربر باز میگردانند. این سرورها برای انجام تَسکهای مختلف با مجموعهای از زیرساختهای بکاند همچون دیتابیس، سرویس ذخیرهسازی کَش، صف مربوط به جابها، سرویسهای جستجو، میکروسرویسها، صف دیتا یا لاگهای کاربران و موارد دیگر ارتباط برقرار میکنند.
Database Servers (مرحلهٔ ۴)
هر وب اپلیکیشنی برای ذخیرهٔ دیتای خود به یک یا چند دیتابیس نیاز دارد و این در حالی است که دیتابیسها امکان تعریف دیتا استراکچر، وارد کردن دیتای جدید، جستجو در حجم زیادی از دادهها و پیدا کردن دیتای مد نظر، بهروزرسانی و یا حذف دیتای موجود، انجام محاسبات روی کل دادهها و غیره را برای دولوپرها فراهم میآورند.
در برخی موارد ممکن است که وب اپلیکیشن به طور مستقیم و تنها با یک دیتابیس ارتباط برقرار کند اما این احتمال وجود دارد که هر سرویسی مربوط به بکاند اپلیکیشن دیتابیس منحصربهفرد خود را دارا بوده و جدا از سایر قسمتهای اپلیکیشن باشد. در یک نگاه کلی، دیتابیسها را میتوان به دو دستهٔ مجزا تقسیم کرد که در ادامه جزئیاتی در مورد آنها، دیتابیسهای نوع SQL و همچنین نوع NoSQL، را مورد بررسی قرار خواهیم داد.
SQL مخفف Structured Query Language بوده و در دههٔ 1970 به عنوان یک روش استاندارد برای انجام کوئری (پرسوجو) از دیتاستهای به اصطلاح Relational (رابطهای) ابداع شد که در دسترس عموم بودند. دیتابیسهای نوع SQL دیتا را در جداولی ذخیره میکنند که از طریق یکسری به اصطلاح ID مشترک (معمولاً از نوع عدد صحیح) به یکدیگر لینک میشوند. لازم به ذکر است که دیتابیسهای نوع SQL غالباً قابلیت توسعه در مقیاس افقی را نداشته و فقط میتوان آنها را در مقیاس عمودی آن هم به یک اندازۀ خاص توسعه داد.
برای درک بهتر این مطلب، یک مثال ساده را در این مورد بیان میکنیم. فرض کنید یک دیتابیس رابطهای داریم که در آن اطلاعات مربوط به آدرس کاربران را ذخیره میکنیم که برای این منظور نیازمند دو جدول هستیم که یکی از آنها اطلاعات Users (کاربران) و دیگری اطلاعات مربوط به Users_Addresses (آدرس کاربران) را نگاهداری میکند. این دو جدول با استفاده از User_Id (شناسهٔ کاربر) به یکدیگر لینک شدهاند؛ بنابراین میتوان گفت دو جدول به این دلیل به هم لینک هستند که ستون مربوط به user_id در جدول User_Addresses به عنوان یک به اصطلاح Foreign Key (کلید خارجی) برای ستون مربوط به id از جدول Users محسوب میشود.
NoSQL مجموعۀ جدیدی از تکنولوژیهای مورد استفاده برای مدیریت دیتابیس است. این تکنولوژی در شرایطی کاربرد دارد که دیتای تولید شده توسط وب اپلیکیشنها بسیار زیاد باشد؛ به عبارت دیگر NoSQL برای هندل کردن #بیگ دیتا (کلان داده) مناسب است (برای کسب اطلاعات بیشتر در این خصوص، میتوانید به مقالهٔ درآمدی بر انواع مختلف دیتابیسهای NoSQL مراجعه نمایید.)
Caching Service (مرحلهٔ ۵)
در این سرویس دیتا با یک فرمت Key:Value ذخیره میشود و همین مسئله موجب شده است تا ذخیرهسازی یا جستجوی دیتا در داخل آن با پیچیدگی زمانی بسیار کم و معادل با (1) O انجام شود. اپلیکیشنها معمولاً از این سرویس به منظور کَش کردن تَسکهایی استفاده میکنند که انجام آنها پُرهزینه بوده، بنابراین در دفعات بعدی به جای انجام مجدد آنها، نتایج ذخیرهشده از حافظهٔ کَش وبسایت بازیابی میشوند (از جمله تکنولوژیهای محبوب در سرورهای مربوط به ذخیرهسازی دیتا در حافظۀ کَش میتوان Redis و Memcache را نام برد.)
همچنین یک اپلیکیشن ممکن است نتایج حاصل از یک کوئری به دیتابیس، اتصال به یک سرویس خارجی، فایلهای HTML مربوط به یک URL مشخص و بسیاری موارد دیگر را در حافظۀ کَش خود ذخیره کند که در ادامه برای درک بهتر این موضوع، چند مثال از اپلیکیشنهای دنیای واقعی را بیان میکنیم:
- گوگل نتایج جستجو از یکسری کوئری معمولی مانند «بهترین کتاب آموزش کدنویسی» یا «زندگینامهٔ محمدرضا شجریان» را در حافظۀ کَش خود ذخیره میکند تا در هر بار مجدداً آنها را جستجو نکند.
- فیسبوک بسیاری از اطلاعاتی را که یک کاربر در هنگام ورود به سیستم میبینید، مانند دیتای مربوط به یک پُست، صفحۀ پروفایل دوستان و غیره، را در حافظۀ کَش خود ذخیره میکند.
- سکان آکادمی خروجی فایل HTML صفحهٔ هومپیج را در حافظۀ کَش خود ذخیره میکند تا در صورت نیاز برای لود مجدد، صفحۀ مد نظر با سرعت بیشتری لود شود.
Job Queue & Servers (مرحلهٔ ۶)
در اکثر وب اپلیکیشنها بایستی یکسری به اصلاح Job به صورت آسنکرون (غیرهمزمان) و در پشت صحنه انجام شوند و این جابها به طور مستقیم به ریسپانس متناظر با ریکوئست کاربر مرتبط نیستند. به عنوان مثال، گوگل برای برگرداندن نتایج جستجوی خود بایستی کل اینترنت و صفحات وب را با استفاده از رباتهای خود کراول (بررسی) کرده و آنها را ایندکس نماید. در حقیقت، این کار با هر ریکوئست جستجوی کاربر انجام نمیشود بلکه گوگل صفحات موجود در وب را به صورت آسنکرون از قبل کراول کرده و دیتابیس خود را آپدیت نگاه میدارد به طوری که این دیتابیس حاوی دیتای مربوط به ایندکسگذاری صفحات وب است.
وب اپلیکیشنها برای انجام جابهای خود به صورت آسنکرون معماریهای مختلفی را میتوانند به کار گیرند که یکی از محبوبترین آنها برای این امر اصطلاحاً Job Queue نامیده میشود که از دو کامپوننت تشکیل شده که یکی از کامپوننتها صَفی است که یکسری تَسک را شامل میشود که بایستی اجرا شوند و کامپوننت دوم یک یا چند سرور هستند که بایستی تَسکهای موجود در صف را اجرا کنند که اصطلاحاً Worker نامیده میشوند.
معماری Job Queue لیستی از تَسکهایی را ذخیره میکند که بایستی به صورت آسنکرون انجام شوند و سادهترین نوع از این لیستها به صورت First-In First-Out یا به اختصار FIFO کار میکند که در آن تَسکی که ابتدا وارد صف شده، اول از همه نیز انجام میشود. با این حال، اکثر اپلیکیشنها نیاز به نوع خاصی از سیستم اولویتبندی جابها در صف دارند که از همین روی هر زمانی که وب اپلیکیشن نیاز به انجام یک تَسک خاص داشته باشد، این تَسکها یا بر اساس یک اولویتبندی خاصی به ترتیب انجام میشوند و یا خود دولوپر یا وبمستر اولویت هر کدام از آنها را تعیین میکند.
به عنوان مثال، وبسایت سکان آکادمی نیز به منظور انجام یکسری از تَسکهای پشت صحنۀ مورد نیاز برای نشان دادن محتوای مناسب به کاربرانش، از یکسری به اصطلاح Job Queue استفاده میکند که از آن جمله میتوان به تَسکهایی مرتبط با انتخاب مقالات مرتبط با یک پست در وبلاگ، ارسال ایمیل بازیابی رمزعبور، ارسال ایمیلهای مربوط به پاسخ به کامنت یک کاربر و غیره را نام برد (اولویتبندی جابها با یک صَف سادۀ FIFO شروع شده و در ادامه به یک صَف اصطلاحاً Priority ارتقا یافته است تا این اطمینان حاصل شود که برخی عملیات حساس به تایم مانند ارسال ایمیلهای بازیابی رمزعبور یا ایمیلهایی که مربوط به پاسخ به کامنت یک کاربر است، در اسرع وقت برای ایشان ارسال میشود.)
در ادامه، جاب سرورها هر یک از این تَسکها را پردازش کرده و Queue (صَف) مربوط به Job (تَسک یا عملیات مربوطه) را بررسی میکنند که اگر تَسکی موجود بود، آن را از صف خارج کرده و انجام دهند (لازم به ذکر است که زبانهای برنامهنویسی و فریمورکهای مورد استفاده برای پیادهسازی جاب سرورها به اندازۀ زبانهای مورد استفاده برای وبسرورها متنوع هستند اما بررسی جزئیات بیشتر مربوط به آنها خارج از بحث این مقاله است.)
Full-Text Search Service (مرحلهٔ ۷)
برخی وب اپلیکیشنها تعدادی فیچرهای جستجو را ساپورت میکنند که از آن جمله میتوان به قابلیتی اشاره کرد که با استفاده از آن کاربر یک ورودی متنی را وارد کرده، که اغلب آن را تحت عنوان کوئری میشناسیم، و وب اپلیکیشن مد نظر نتایج مرتبط به موضوع مورد جستجو را در خروجی برمیگرداند. سرویسی که چنین قابلیتی را برای وب اپلیکیشنها فراهم میکند، معمولاً Full-text Search Service نامیده میشود که این تکنولوژی از روشی تحت عنوان Inverted Index استفاده میکند تا فرآیند جستجوی داکیومنتهایی را تسریع کند که حاوی کلمات کلیدی موجود در کوئری کاربر هستند. به عنوان نمونه داریم:
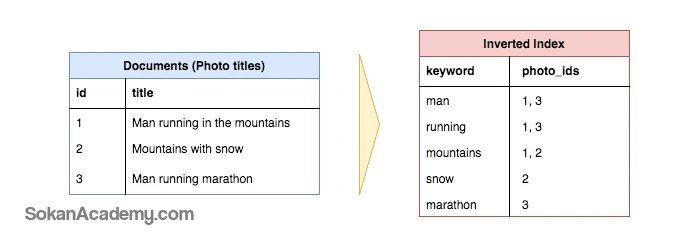
در تصویر فوق میبینید که چگونه عناوین سه مقالهٔ مختلف با استفاده از روش Inverted Index به چند اصطلاحاً ID (شناسه) تبدیل شدهاند تا سرعت جستجو برای یک کیوورد خاص به منظور دستیابی به داکیومنتی با عنوان مد نظر کاربر، افزایش یابد. نکتۀ لازم به ذکر این است که حروف اضافهای همچون in ،the ،with و غیره معمولاً در Inverted Index در نظر گرفته نمیشوند چرا که اساساً کمکی به یافتن محتوای مرتبط با با جستجوی کاربران نمیکنند.
برخی از سیستمهای مدیریت دیتابیس (DBMS) نیز قابلیت جستجوی به اصطلاح Full-Text را دارند که از آن جمله میتوان به MySQL اشاره کرد. در عین حال، برخی وب اپلیکیشنها از یک سرویس جستجوی جداگانه بهره میگیرند که امکان محاسبه و ذخیرۀ Inverted Index را به ازای عبارات جستجوی کاربران فراهم میکنند که از جملهٔ محبوبترین پلتفرمهای امروزیِ جستجو به شیوۀ فولتِکست میتوان Elasticsearch ،Sphinx یا Apache Solr را نام برد.
Services (مرحلهٔ ۸)
هنگامی که اپلیکیشنی به یک اندازۀ مشخص توسعه مییابد، احتمالاً سرویسهای خاصی مورد نیازش خواهند بود که در قالب اپلیکیشنهایی مجزا اما مرتبط با وب اپلیکیشن اصلی اجرا میشوند. برای مثال، میتوان سرویسهایی به شرح زیر را برای یک وبسایت خاص بیان کرد که برای هر یک از آنها نیز پلنی طراحی شده است:
- Account Service: این سرویس دیتای مربوط به یک کاربر خاص همچون نامکاربری، عکس پروفایل و ... را در تمامی کامپوننتهای وبسایت در قالب یک اصطلاحاً Session ذخیره میکند و این امکان را در اختیار وبمستر قرار میدهد تا با بررسی رفتار کاربران، محتوای مورد علاقۀ ایشان را برایشان فراهم کند که در نتیجه موجب ایجاد یک #تجربۀ کاربری بهتر میگردد.
- Payment Service: این سرویس بیشتر در فروشگاههای آنلاین دیده میشود بدین شکل که امکان پرداخت وجه را برای کاربران میسر میسازد که این کار با ارتباط با درگاه بانکها صورت میپذیرد.
- HTML → PDF Service: این سرویس یک رابط کاربری ساده را ارائه میدهد که از آن طریق یکسری فایل HTML را دریافت کرده و داکیومنتی با فرمت PDF مربوط به آن فایل را در خروجی برمیگرداند (همچون قابلیتی که در اکثر سایتهای رزومهساز آنلاین مشاهده میشود.)
Data (مرحلهٔ ۹)
امروزه ممات یا حیات برخی شرکتها و استارتاپها به چگونگی استفادۀ آنها از دیتا وابسته است و از همین روی دولوپرها برای اکثر اپلیکیشنهای مدرن که به یک اندازۀ مشخص توسعه یافتهاند، یک به اصطلاح دیتا پایپلاین تعریف میکنند تا اطمینان حاصل کنند که دیتای وب اپلیکیشن مد نظر جمعآوری، ذخیره و آنالیز میشود که این پایپلاینها معمولاً دارای مراحل اصلی زیر هستند:
- وب اپلیکیشن مذکور دیتا یا به طور کلی ایونتهای مربوط به تعامل کاربران با وبسایت را به اصطلاحاً یک Firehose میفرستد (Firehose یک رابط کاربری به منظور دریافت و پردازش دیتای کاربران را فراهم میکند.) که در این مرحله دیتای خام پس از آنالیز، که ممکن است به دیتایی دیگر تبدیل شده و یا همان دیتا با یکسری اطلاعات افزوده شده باشد، به یک Firehose دیگر منتقل میشود (برای این منظور نیز دو تکنولوژی رایج از جمله AWS Kinesis و Kafka را میتوان نام برد.)
- در ادامه، دیتایی که یکسری تَسکها روی آن صورت گرفته در یک به اصطلاح Data Warehouse (انبار داده) لود میشود که در این مرحله تحلیلگران میتوانند دست به آنالیز دادهها بزنند. تعداد بسیار زیادی از استارتاپها و همچنین شرکتهای بزرگ اغلب از تکنولوژیهایی همچون Oracle برای ذخیرۀ دیتا در Warehouse بهره میگیرند اما در شرایطی که دیتاستها بزرگ باشند، احتمالاً تکنولوژیهایی مشابه تکنولوژی NoSQL MapReduce Hadoop برای آنالیز دیتا مناسب باشد.
Cloud Storage (مرحلهٔ ۱۰)
سرویس AWS کمپانی آمازون که یکی از سرویسهای کلود معروف در دنیا است، در مورد سرورهای مبتنی بر کلود چنین میگوید:
ذخیرهسازی دیتا در سرورهای مبتنی بر کلود یک روش ساده و مقیاسپذیر برای ذخیره، دسترسی و به اشتراکگذاری دیتا در اینترنت است.
در واقع، با استفاده از کلود میتوانیم هر آنچه که در فایلسیستم لوکال خود ذخیره کرده بودیم را به صورت آنلاین در دسترس کاربران وبسایت خود قرار دهیم. اساساً انتخاب یک سرویس هاستینگ وبسایت، خواه یک سرور اشتراکی باشد و خواه سرور اختصاصی و یا حتی کلود، بسیار حائز اهمیت است که برای کسب اطلاعات بیشتر توصیه میکنیم به آموزش آشنایی با مفهوم هاستینگ و معیارهای انتخاب یک شرکت وب هاست خوب مراجعه نمایید.
CDN (مرحلهٔ ۱۱)
پیش از این اشارهای کوتاه به مفهوم شبکهٔ توزیع محتوا (CDN) کردیم که به طور خلاصه هدف از استفاده از این فناوری این است که یکسری Asset منجمله فایلهای JS ،CSS ،HTML و همچنین تصاویر موجود در یک صفحۀ وب سریعتر از حالتی لود شوند که بخواهیم برای لود آنها از سرور اصلی استفاده کنیم. نحوۀ کار CDN بدین صورت است که محتوای مد نظر در بین سرورهایی تحت عنوان Edge در سراسر جهان توزیع میشود به طوری که کاربران به جای سرور اصلی (مبدأ)، فایلهای مد نظر خود را از سرورهای Edge دانلود میکنند که از لحاظ جغرافیایی به ایشان نزدیکتر هستند (یک سرور Edge غالباً به عنوان سرور ارتباطی بین شبکههای جدا از هم به کار میرود و هدف اصلی آن کم کردن فاصلۀ محتوای درخواستی کاربران از دیوایسهای ایشان و در نتیجه کاهش تأخیر و بهبود زمان لود صفحات وب است.)
به عنوان مثال، فرض کنیم کاربری در اسپانیا یک صفحهای را از وبسایتی باز میکند که سرور آن در نیویورک است اما فایلهای مورد نیاز وبسایت از جمله فایلهای استاتیک HTML از یک سرور Edge در انگلستان لود میشوند که این امر از ارسال ریکوئستهای مکرر بر بستر اقیانوس اطلس جلوگیری میکند چرا که ارسال چنین ریکوئستهایی موجب کُند شدن سرعت لود صفحات وب میشود (برای آشنایی بیشتر با مفهوم شبکهٔ توزیع محتوا، توصیه میکنیم به مقالهٔ CDN (شبکهٔ توزیع محتوا) چیست و چگونه کار میکند؟ مراجعه نمایید.)
سخن پایانی
آنچه در این مقاله گفته شده، شرح سازوکار یک وبسایت به زبان ساده بود به طوری که فرایندهایی مورد بررسی قرار گرفتند که همواره از دید کاربران پنهان هستند اما برای اینکه وبسایتی به صورت کامل و در عین حال با کمترین زمان لود اجرا گردد، لازم و ضروری هستند (همچنین در دورهای تحت عنوان وب چگونه کار میکند؟ که مقدمهای بر مقولهٔ مهم حریم خصوصی است، مقدماتی در مورد نحوهٔ کارکرد وب آورده شده که به نوعی تکمیلکنندهٔ مباحث طرحشده در این مقاله هستند.)
