در این مقاله به بررسی دیتابیسهای NoSQL، اصول طراحی، مدل سازی و زمان استفاده از آنها خواهیم پرداخت. انتظار میرود پس از مطالعه ی این مقاله با دیتابیس های NoSQL آشنا شده و بتوانیم در شرایط مختلف دیتابیس مناسبی را انتخاب نماییم.
این مقاله توسط دپارتمان دیتابیس تیم تولید محتوای سکان آکادمی برای شما تهیه شده است و برای درک هرچه بهتر مطالب ارائه شده تنها کافیست، اطلاعات عمومی دربارهی ریتابیس (یا همان پایگاه داده) و وظیفه ی آن داشته باشید.
دیتابیس NoSQL
با پیشرفت تکنولوژی طی سالیان اخیر نیاز به پردازش و ذخیره سازی بهینه تر با سرعت بالا و عدم امکان استفاده از جدول در بسیاری از پروژه های بزرگ مشاهده شد. از طرفی ذخیره سازی حجم بالایی از داده های بدون ساختار، در دیتابیسهای رابطهای باعث کاهش شدید سرعت و کارایی دیتابیس میگردد. از این رو تکنولوژی جدیدی به نام NoSQL با اهدافی همچون ذخیره سازی و کار با داده های بدون ساختار و حجیم معرفی شد.
برخی از اهدافی که دیتابیسهای NoSQL دنبال میکنند به شرح زیر است.
- ذخیرهسازی دادههایی با حجم بالا و بدون ساختار. در دیتابیسهای NoSQL شما هیچ گونه محدودیتی روی نوع دادههایی که در کنار هم قرار میدهید ندارید. همچنین به شما اجازه میدهد آن گونه که میخواهید دادهها را تغییر دهید. با استفاده از روش مبتنی بر سند، شما میتوانید دادههای مختلفی را بدون اینکه نوع آنها مسئله مهمی برای ذخیره سازی باشد، در یک سند قرار دهید.
- ذخیرهسازی و انجام محاسبات ابری. ذخیرهسازی مبتنی بر ابر یکی از راهحلهای بسیار مناسب، همراه با میزان هزینه خوب است، اما برای بالاتر رفتن میزان مقیاسپذیری نیاز است که دادهها را در سرورهای مختلف منتشر کنید.
- توسعه سریع. وقتی قصد دارید یک پروژه جدید را راه اندازی کنید، در حالتی که از دیتابیسهای رابطهای استفاده کنید، باید ابتدای کار ساختار برنامه را مشخص کنید و شمای کلی برای آن طراحی نمایید که این کارها در ابتدا بسیار زمانبر است. اما در حالتی که از دیتابیس NoSQL استفاده کنید، دیگر این مشکلات را نخواهید داشت.
به طور کلی این نوع دیتابیسها به دلیل عدم ذخیره مقادیر Null فضای کمتری اشغال میکنند و همچنین به دلیل عدم استفاده از Join بسیار سریع هستند.
💎 برای مطالعه ی بیشتر به مقالهی تفاوت های SQL و NoSQL مراجعه کنید.
انواع دیتابیسهای NoSQL (نو اس کیو ال)
به دلیل استفاده برای کاربردهای مختلف، این نوع دیتابیسها به چهار دسته تقسیم میشوند که در ادامه به معرفی آنها خواهیم پرداخت و اصول طراحی، مدلسازی داده و موارد استفاده آنها را بررسی خواهیم کرد.
1. دیتابیس سندی (Document Database)
در این نوع دیتابیس یک جفت کلید-مقدار(Key-value) وجود دارد که مقدار به عنوان یک دادهی قابل بازیابی ذخیره میشود و کلیدِ مربوط به آن هم، نشانگری منحصربهفرد است. همچنین مقدار ذخیره شده به نوعی کاملاً ساختیافته (یا حدوداً ساختیافته) می باشد. به طوری که این دادههای ساختیافته به عنوان یک سند شناخته میشوند و میتوانند یکی از فرمتهایXML ،JSON یا BSON را داشته باشند. در نتیجه میتواند دادههای تودرتو را نیز شامل شوند. از جمله دیتابیسهای سندی، میتوانMongoDB و Elasticsearch را نام برد که عمدهی موارد استفادهی آنها در فروشگاههای آنلاین، سیستمهای مدیریت محتوا، پلتفرمهای تجزیه و تحلیل داده و پلتفرمهای وبلاگی می باشد.
به طور معمول دیتابیسهای سندی انتخاب مناسبی برای دیتابیس اصلی نرم افزار هستند و به راحتی میتوان اطلاعات زیادی را در آنها ذخیره و بازیابی کرد.
طراحی دیتابیس سندی
در این نوع دیتابیس، دادهها به صورت یک Collection از سندها ذخیره میشود که به عنوان مثال در یک وبلاگ، اطلاعات هر پست، یک سند در نظر گرفته میشود. و اطلاعات کل پستها در Collection نگهداری میشود. چون اطلاعات به صورت تودرتو ذخیره میشوند در مواجه با حالتهای مختلف، روش کاریِ متفاوتی جهت طراحی و ذخیره داده اعمال میشود. که به دو دسته تقسیم می-شوند.
1. Embedding: در این روش اطلاعات Sub-document (اطلاعات زیرمجموعه ی سند اصلی) در همان مجموعه اصلی ذخیره میشود، در نتیجه موجب بالا رفتن حجم مجموعه اصلی میگردد. ساختار این روش طراحی را در زیر میتوان مشاهده کرد.
[
{
_id:2,
Author:"Jahn Doe",
Title:"NoSQL Databases",
Body:{...},
Comments:[
{id:1231, date:2020-04-04, message: "Very Good!", ...},
{id:1232, date:2020-04-05, message: "It’s really…", ...}
]
}
]
2. Referencing: در این روش اطلاعات Sub-document در مجموعهی دیگری و کلید آنها در مجموعه اصلی ذخیره میشود. در نتیجه حجم اطلاعاتِ مجموعهی اصلی کاهش مییابد،کار با آن راحتتر میشود و پرسوجوها سریعتر پاسخ داده میشوند. ساختار این روش طراحی را میتوانید مشاهده کنید:
[
{
_id:2,
Author:"Jahn Doe",
Title:"NoSQL Databases",
Body:{...},
Comments:[1231,1232]
}
]
[
{
id:1231,
date:2020-04-04,
message: "Very Good!",
...
},
{
id:1232,
date:2020-04-05,
message: "It’s really…",
...
}
]
در طراحی دیتابیسهای سندی برای ذخیره ی اطلاعاتی که ارتباط آنها یک-به-یک (One-to-One) است. بهتر است از روش Embedding استفاده شود. و در ذخیره ی اطلاعاتی که ارتباط آنها یک-به-چند (One-to-Many) یا چند-به-چند (Many-to-Many) است، در صورتی که حجم اطلاعات کمتر از 16 مگابایت باشد بهتر است به صورت Embedding و در غیر اینصورت Referencing ذخیره شوند.
2. دیتابیس کلید-مقدار (Key-Value Database)
در این نوع دیتابیسها، کلیدها به صورت جدول Hash ذخیره می شوند (برای آشنایی با ساختار Hash Table ها به مقالهی Hash Table چیست و چه زمانی از آن استفاده میشود؟ مراجعه کنید) تا بتوان آن ها را ساده تر و سریع تر جستجو کرد. این نوع دیتابیسها دارای سرعت فراخوانی بسیار بالایی هستند و کار کردن با دیتابیسهای کلید-مقدار بسیار ساده است.
این دیتابیس ها کاربردهای فراوانی دارند. از جمله این کاربردها میتوان به ذخیره سازی جلسه (Session)های کاربر (مثلا ذخیره سازی اطلاعات کاربری در یک وب سایت)، ذخیره سازی دادهها به صورت Cache، ذخیره سازی سبد خرید در یک فروشگاه اینترنتی، لیست آخرین بازدید کنندهها ،صف بندی و… اشاره کرد.
یکی از اشکالات این نوع دیتابیسها عدم وجود ویژگی Consistency (سازگاری) در آن هاست. اگر دادههایی که قصد ذخیره سازی آنها را داریم دارای ارتباطات مختلفی باشند، دیتابیس های کلید-مقدار کارایی خود را از دست میدهند. این دیتابیس ها معمولا در زمانی که میزان نوشتن دادهها در دیتابیس کم و خواندن آنها زیاد است توصیه میشوند. در شکل زیر شمای دیتابیسهای کلید-مقدار قابل مشاهده است.
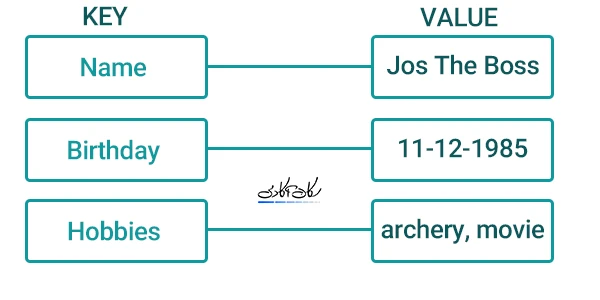
طراحی دیتابیس کلید-مقدار
در این مقاله دیتابیس Redis، به عنوان محبوب ترین دیتابیس کلید-مقدار جهت بررسی انتخاب شده است. در Redis، مقدار میتواند یکی از پنج نوعِ String, List, Set, Sorted Set, Hash باشد.
جهت ذخیره اطلاعات از نوع داده Hash استفاده میکنیم. در مثال وبلاگ، کلیدِ پستِ شمارهی یک را به صورت posts:1 در نظر گرفته و اطلاعات آنرا در یک دادهی Hash که ساختار آن مشابه زیر است ذخیره میکنیم.
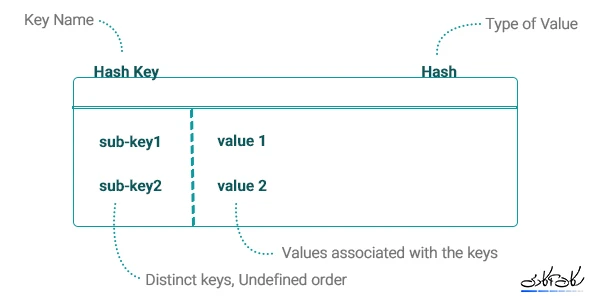
جهت ذخیره یک نظر برای پست میبایست کلید نظر را به صورت comments:1 در نظر گرفته، اطلاعات آنرا در یک دادهی Hash و ارتباط آنها را به وسیله یک دادهی Sorted Set که ساختار آن در شکل زیر مشخص است ذخیره کرد. و میتوان آنها را بر اساس تاریخ ایجاد نظر و یا هر مقدار عددیِ دیگری مرتب کرد.
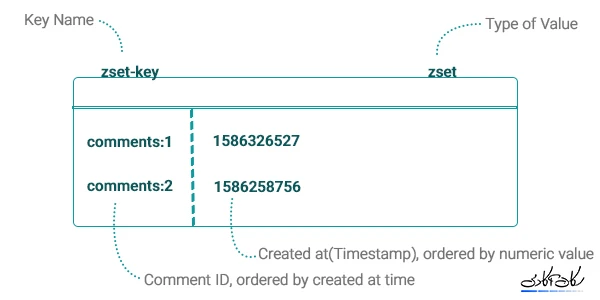
هرچند که این نوع دیتابیس میتواند دیتابیس اصلی پروژه باشد ولی پیشنهاد میشود که از آن در لایهی Cache پروژهی تان بهره ببرید.
💎 از دیگر دیتابیسهای key-value ، میتوان به دیتابیس UnQLite اشاره کرد که با مطالعهی مقالهی UnQLite: یک موتور پایگاه داده NoSQL با قابلیت اجرای مستقل میتوانید اطلاعات بیشتر راجع به آن کسب کنید.
3. دیتابیس Wide-column
درگذشته داده ها به صورت سطری ذخیره می شدند. ولی این دیتابیس ها روش دیگری از ذخیره ی داده را معرفی کردند. در ذخیره سازی ستونی، اطلاعاتِ فیلدهای یک سطر در ستونهای مختلف باهم در ارتباط هستند. این نوع ذخیره سازی، برای رفع نیاز سیستم هایی با مقیاس پذیریِ بسیار زیادِ اطلاعات، که نیاز به پاسخ دهی سریع و کارایی بالا داشتند معرفی شد.
این نوع دیتابیس، بر خلاف دیتابیسهای دیگر، اطلاعات را در حافظه کنار یکدیگر نگه میدارد. این روش نگه داری باعث رشد سرعت بازیابی اطلاعات میشود.
شمای کلی این نوع دیتابیس در شکل زیر قابل مشاهده است.
از جمله کاربردهای این نوع دیتابیس، میتوان به ذخیره سازیLog سنسورها در اینترنت اشیا ، اطلاعات جغرافیایی، سیستمهای گزارشگیری، اطلاعات سری زمانی، ثبت وقایع Online، نرمافزارهایی با نرخ نوشتن بالا در دیتابیس و… اشاره کرد.
معروف ترین دیتابیس این نوع، Cassandra میباشد که با زبان جاوا توسعه یافته است. جهت ارتباط با آن از زبان CQL استفاده میشود که این زبان پرس و جو بسیار به SQL نزدیک است.
از این دیتابیس در نرم افزارهای بزرگ زیر استفاده شده است.
• نمایش اطلاعات اضافی در مورد خواننده و آهنگها در نرم افزار Spotify
• پیدا کردن دوستان در اطراف شخص در نرم افزار Facebook
• ارائه بیش از 190 میلیارد توصیه محتوای شخصی در هر ماه در Outbrain
4. دیتابیس گرافی (Graph Database)
دیتابیس گرافی در واقع مجموعهی موجودیت ها و ارتباط بین آن هاست، که به صورت منظم ذخیره سازی شده اند. معمولاً در دیتابیسهایی که به صورت سطر و ستون ذخیره می شوند، سرعت دسترسی به اطلاعات خوب است (به خصوص زمانی که از Index استفاده شود)، این در حالی است که در بسیاری از مواقع به دلیل نیاز به سرعت بالای دسترسی به اطلاعات، سرعت خواندن و نوشتن داده ها، در دیتابیسهای رابطه ای مناسب به نظر نمی رسد. این اتفاق معمولاً زمانی رخ می دهد که میخواهید، یک یا چند ادغام (Join)، بر روی جداول مختلف یک دیتابیس انجام دهید.
💎 برای درک عمیق تر این نوع دیتابیس، به مقالهی آموزشی آشنایی با Graph database و انواع آن مراجعه کنید.
در این نوع دیتابیس هر موجودیت یک گره در نظر گرفته میشود و ارتباط آن با هر گرهی دیگر را یال مینامند. زمانی که نیاز به جستجو سریع در میان داده های مرتبط با هم را دارید این نوع دیتابیس میتواند انتخاب مناسبی باشد. از سوی دیگر اگر موجودیت ها دارای ویژهگی های زیادی باشند انتخاب این دیتابیس صحیح نیست. معروف ترین دیتابیس گرافی، Neo4j است.
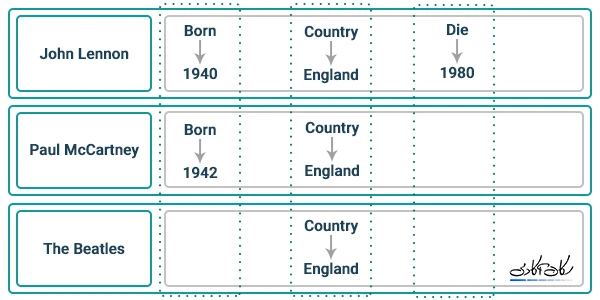
ساختار و شمای این نوع دیتابیس برای مثال ساده ای از یک وبلاگ و دسته بندی های شخصی یک کاربر در زیر نمایش داده شده است.
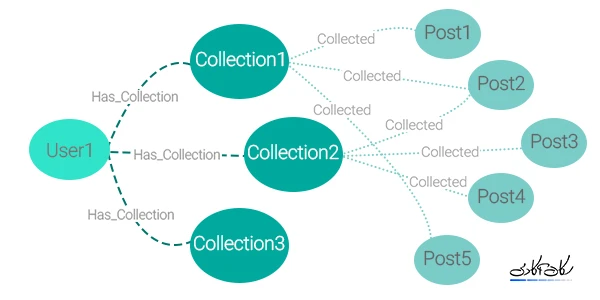
درک بهتر دیتابیس گرافی با یک مثال
فرض کنید،سه موجودیت نویسنده، کتاب و خریدار را داریم. حتماً در ذهن خود، ارتباط بین این موجودیتها را تصور کردید. نویسنده یک یا چند کتاب مینویسد، و خریدار یک یا چند کتاب را می-خرد. در چنین دیتابیسی، ارتباط نقش اساسی و مهمی را دارد. در واقع اطلاعات، به ارتباط بین آن ها وابسته است. حال فرض کنید، میخواهید از بین میلیون ها کتاب، هزاران نویسنده و چند ده هزار خریدار، پرسوجوهای مختلفی انجام دهید. برای مثال میخواهید تمامی خریدارانی که از کتاب های یک نویسندهی خاصرا خریده اند، را از دیتابیس بخوانید. این قبیل پرسوجوها، در دیتابیس های رابطهای، همیشه به اندازه کافی سرعت ندارند و بعضا کند هستند. برای مثال فرض کنید، دیتابیس شما، بسیار بزرگ شده است و میخواهید پرسوجوهای بسیار زیادی در لحظه و بدون هیچ دیرکردی پاسخ داده شوند. اینجاست که میتوانید، به جای استفاده از دیتابیسهای رابطهای، از دیتابیس های گرافی استفاده کنید.
همان طور که در شکل زیر مشاهده میکنید، یال ها نیز، انواعی دارند. در این جا ۲ نوع یال داریم: نوشتن کتاب و خریدن کتاب، که به وسیله این یال ها، رابطه های مختلف شناسایی می شوند.
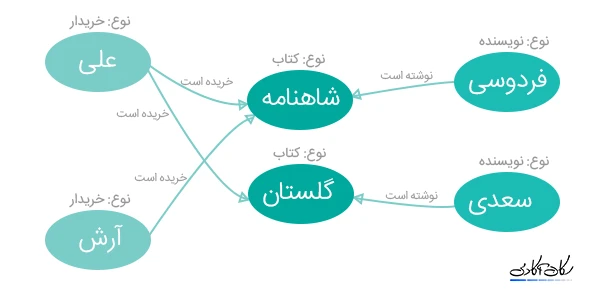
به نسبت دیتابیس های رابطه ای، که روابطی مانند مثال بالا را با استفاده از کلیدهای خارجی مدل میکنند و در زمان پرسوجو از آن کلیدها استفاده میکنند، دیتابیسهای گرافی گرهها و یالها را در سطح نخست ذخیره میکنند. درنتیجه در زمان خواندن اطلاعاتی با این گونه رابطه ها سریعتر عمل میکنند.
دیتابیس های گرافی، کاربرد فراگیری در زمینه های مختلف، مانند داده کاوی شبکه های اجتماعی، مدل های زنجیره تامین و… دارند.
جمع بندی
در این مقاله دیتابیس های NoSQL را بررسی کردیم. دیتابیس های NoSQL بسیار سریع بوده و مناسب برای ذخیره اطلاعاتِ غیر ساخت یافته ی توزیع شده هستند. در خانواده ی دیتابیس های NoSQL برای سناریو ها و نوع داده های مختلف دیتابیس متفاوتی پیشنهاد میشود. که این دیتابیس ها در چهار دسته ی کلی، در این مقاله به صورت مجزا معرفی شدند.
آیا تا بحال از دیتابیسهای NoSQL در پروژه هاتون استفاده کرده اید؟ لطفا از تجربیاتتون برامون بنویسید. منتظر خواندن نظراتتون هستیم.
